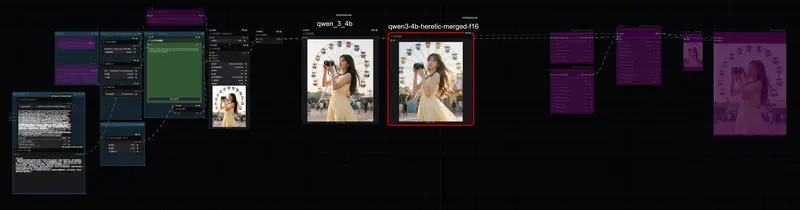
ComfyUI Prompt Helper:本地化提示词工程套件,专为 Z-Image 与Qwen Image优化在 AI 图像生成工作流中,提示词质量直接决定输出上限。然而,大多数用户仍依赖手动编写或在线工具,既低效又难以与 ComfyUI 深度集成。ComfyUI Prompt Helper 正是为解决这一痛...插件# ComfyUI Prompt Helper# Qwen-Image# Z-Image2个月前02200
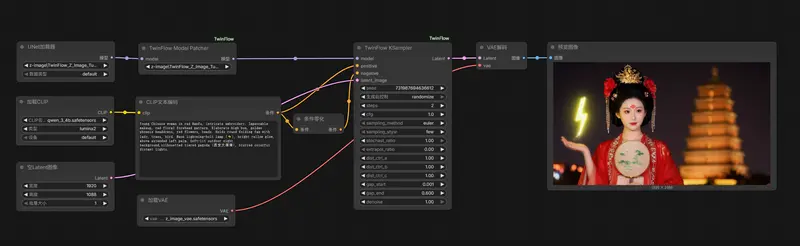
ComfyUI-TwinFlow:加速Qwen-Image、Z-Image生成速度,兼容 LoRA 与 ControlNetTwinFlow是一种通过自对抗流(Self-adversarial Flows)将大型扩散模型(如 Qwen-Image、Z-Image)加速至 1 步或极低步数(2–4 步)生成的先进技术。 1步...插件# ComfyUI-TwinFlow# Qwen-Image# Z-Image3个月前0510
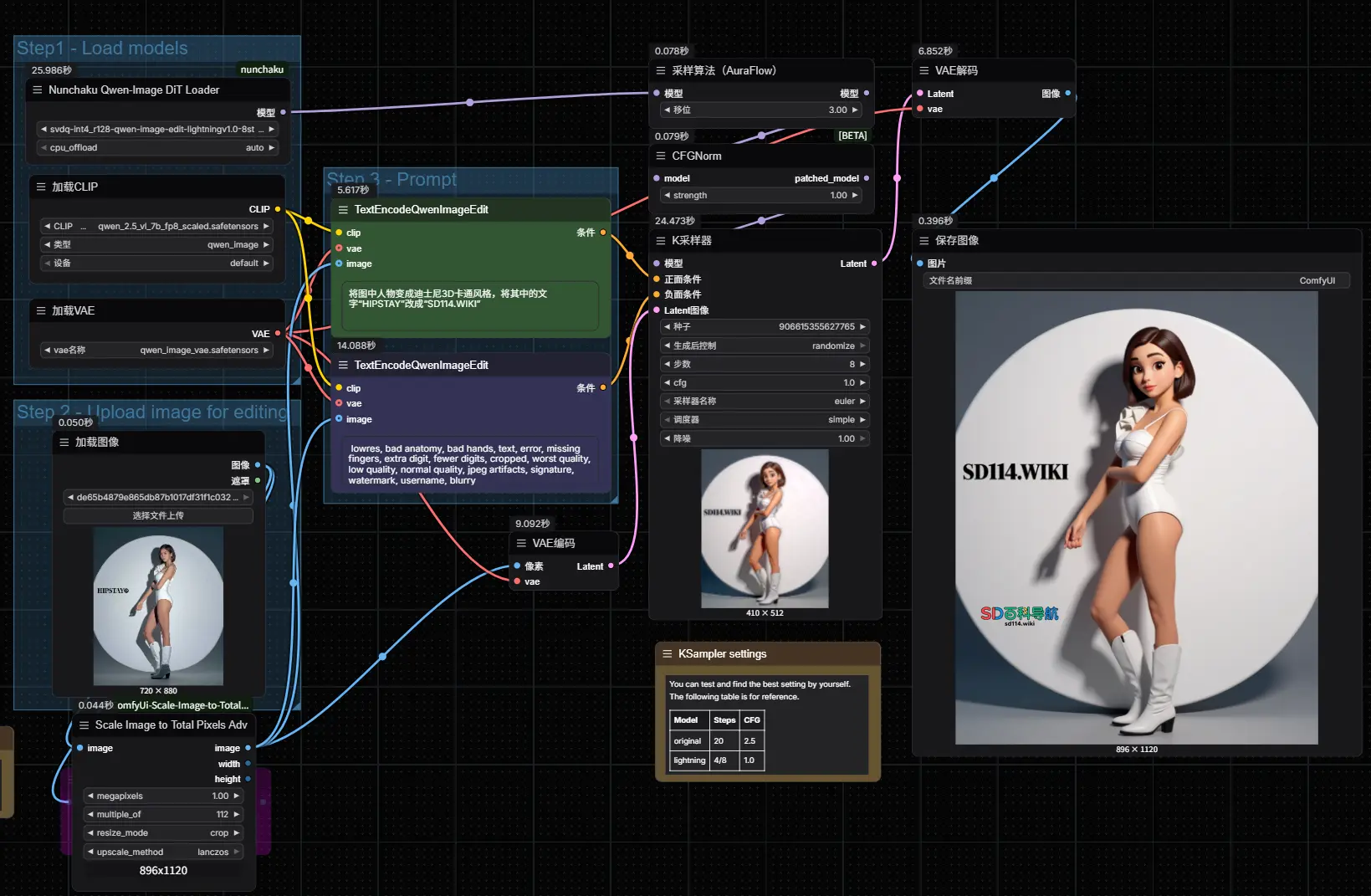
Nunchaku 正式发布 1.0:让 Qwen-Image 与 Qwen-Image-Edit 模型在低显存设备上跑起来9月4日,Nunchaku 团队正式发布 v1.0.0 版本,标志着这一面向 4 位量化神经网络(SVDQuant) 的高性能推理引擎进入稳定可用阶段。 GitHub:https://github.c...工作流# Nunchaku# Nunchaku v1.0.0# Qwen-Image7个月前01,7760
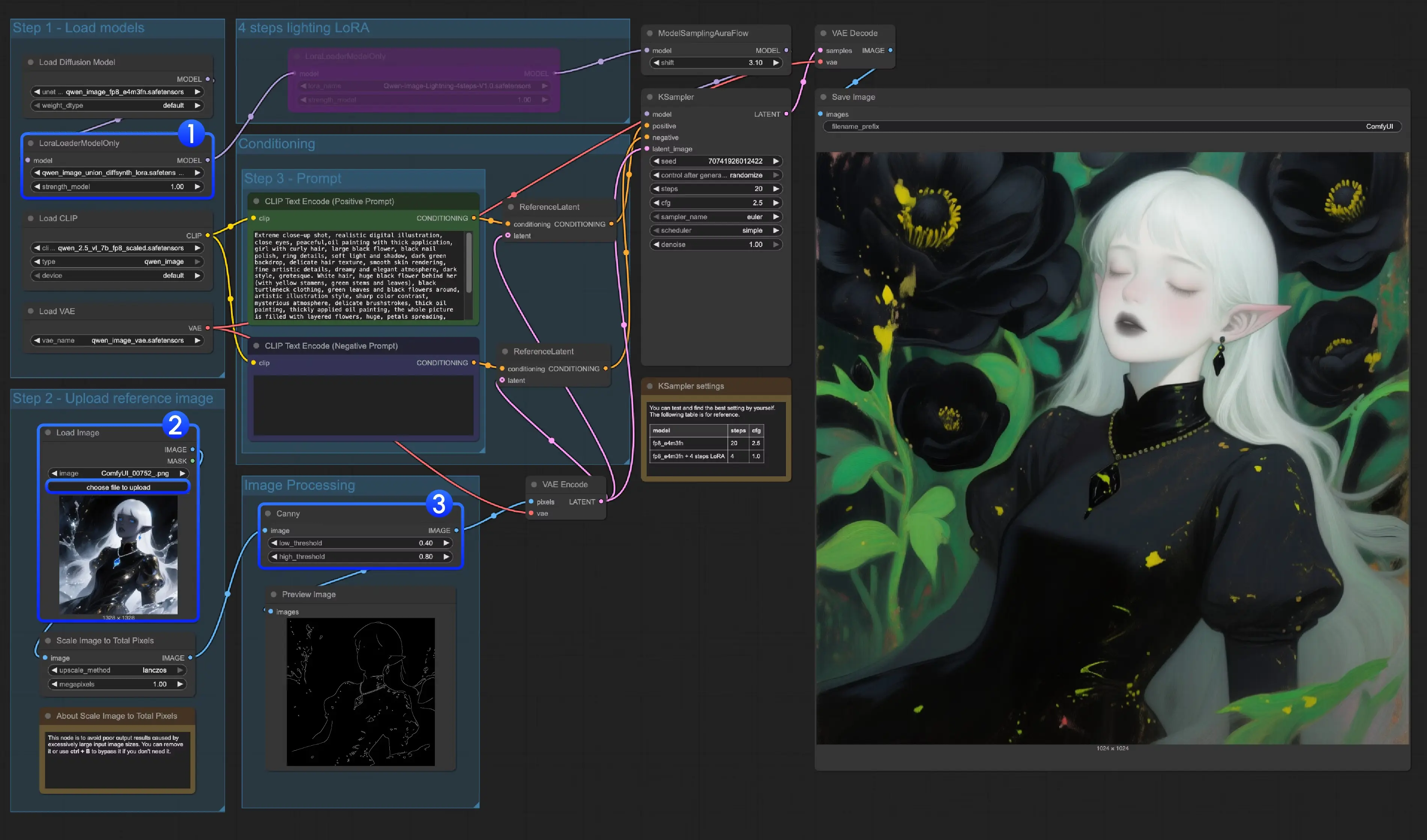
Qwen-Image 图像生成实操指南:三大ControlNet 方案从部署到运行,新手也能上手阿里巴巴通义千问团队发布的 Qwen-Image,是首个基于 MMDiT 架构的开源图像生成基础模型,参数规模达 20B,采用 Apache 2.0 许可证开放,支持高分辨率、多轮对话式图像生成。 H...工作流# controlnet# Lora# Qwen-Image7个月前01,2840
ComfyUI 更新速递:Qwen Image ControlNet/LoRA、EasyCache 与上下文窗口支持ComfyUI 近期迎来多项重要更新,涵盖模型支持、推理优化与工作流扩展能力。本次升级聚焦于提升图像生成的可控性、灵活性与运行效率,尤其增强了对 Qwen Image 系列模型的支持,并引入了更高效的...新闻# ComfyUI# EasyCache# Qwen-Image7个月前06730
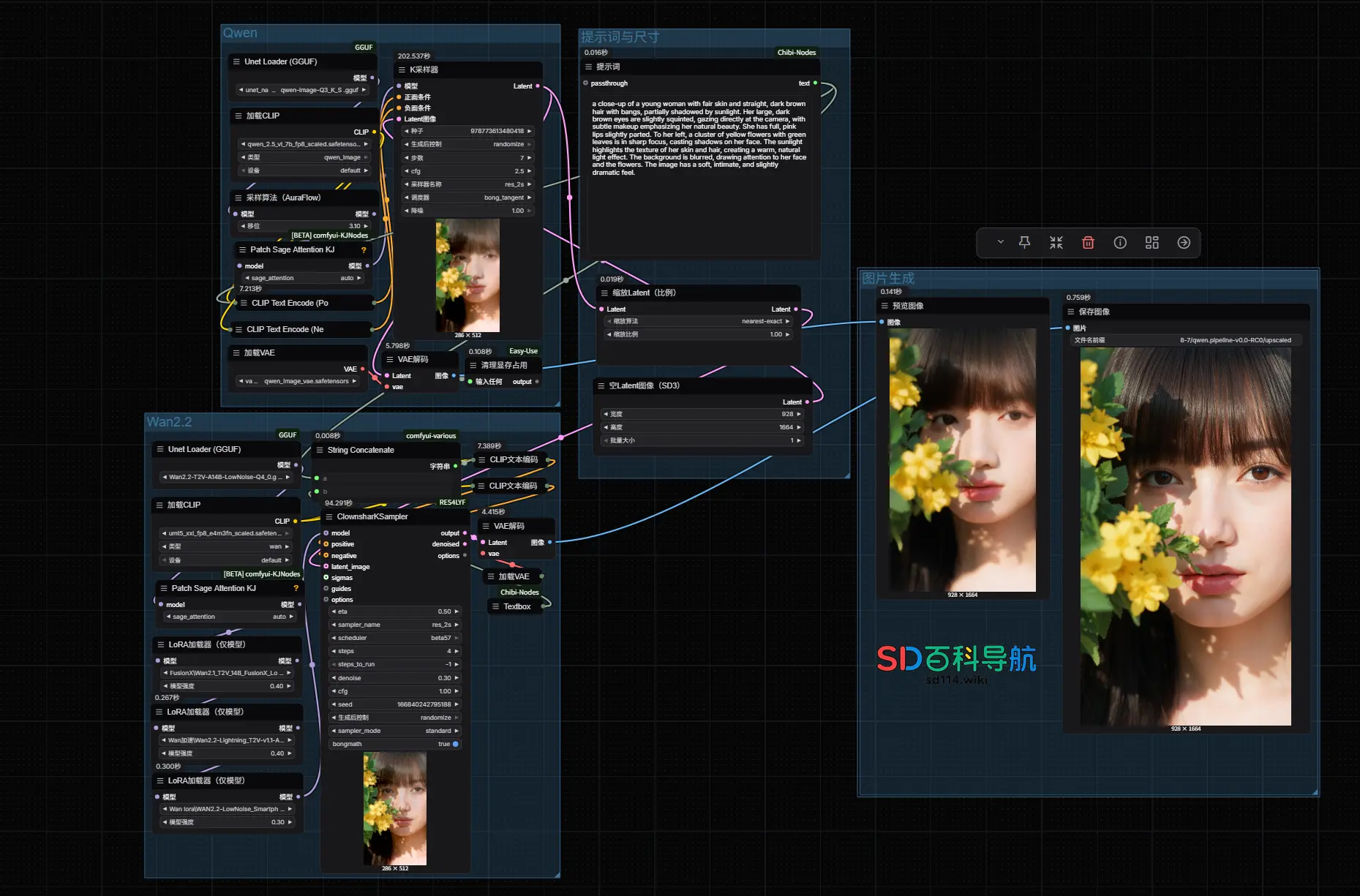
ComfyUI-QwenImageWanBridge:Qwen-Image到WAN 2.2的潜在空间桥接方案,当前部分可用ComfyUI-QwenImageWanBridge是一款针对ComfyUI的技术插件,核心功能是搭建Qwen-Image图像模型与WAN 2.2视频生成模型之间的“潜在空间桥接”——无需经过VAE解...插件# ComfyUI-QwenImageWanBridge# Qwen-Image# WAN 2.27个月前02010
Nunchaku发布量化版Qwen-Image模型,支持高效图像生成Nunchaku 官方宣布,其基于Qwen-Image的四个量化版本模型已正式上线 Hugging Face和魔塔!这些模型专为高效文本到图像生成而优化,尤其在复杂文本渲染方面表现突出。 Huggin...图像模型# Nunchaku# Qwen-Image8个月前06150
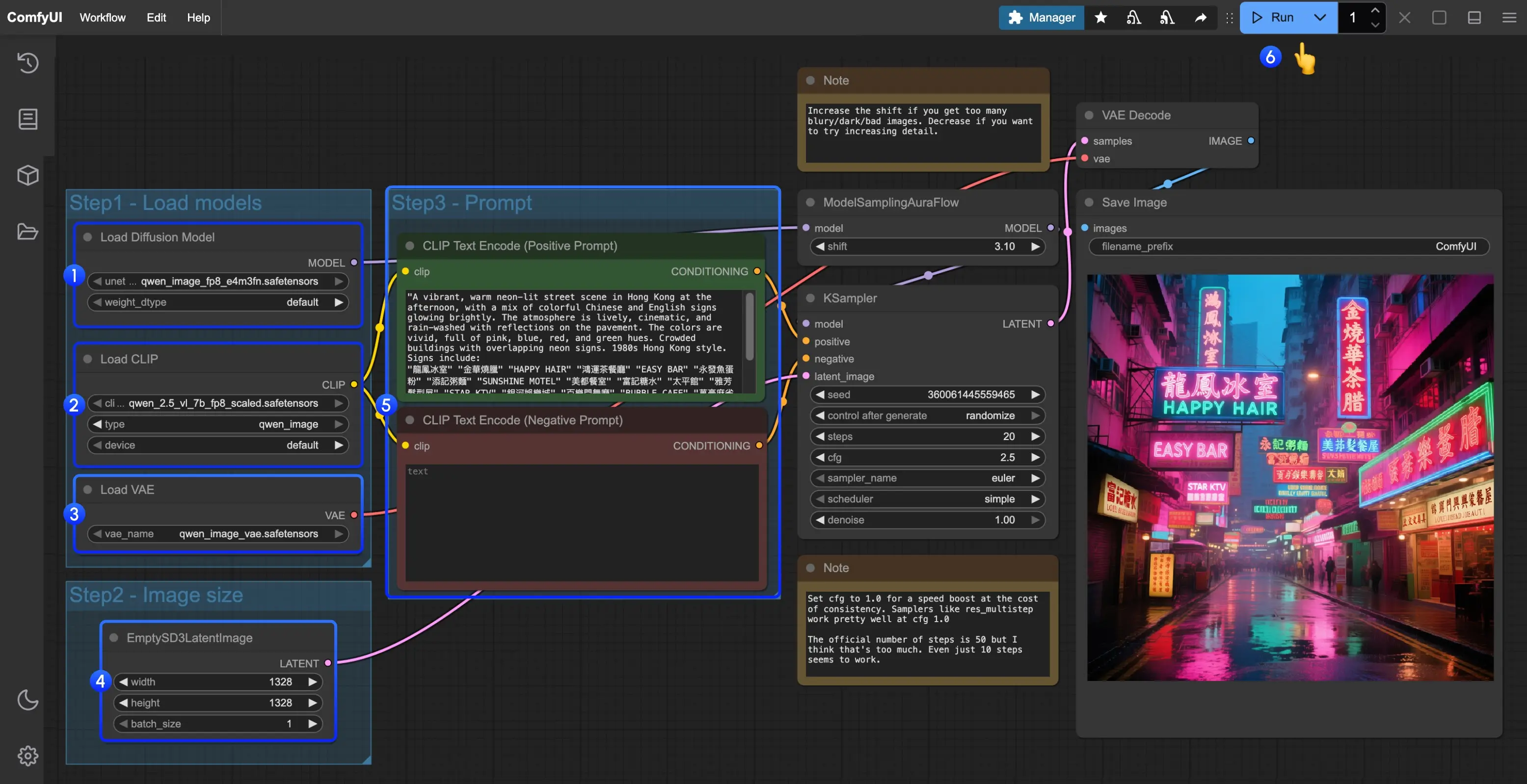
Qwen-Image 使用指南:如何用提示词与参数生成高质量图像在闭源图像模型主导的今天,阿里巴巴推出的 Qwen-Image 成为一股清流——它不仅性能强大,更以 Apache 2.0 开源协议发布,允许企业、开发者和创作者自由使用、修改和部署。 这一特性使其迅...教程# Qwen-Image# 提示词8个月前01,2810
如何兼顾“创意”与“真实”?用 Qwen-Image + Wan 2.2 实现高质量图像生成阿里Qwen项目组近期发布的两款模型Qwen-Image和Wan 2.2都具有图像生成功能,但两款模型在生成图片的时候具有局限性: Qwen-Image 擅长创意构图,想象力丰富,但人物细节 AI 感...工作流# Qwen-Image# WAN 2.2# 图像生成8个月前01,6120
Qwen-Image 原生 ComfyUI 工作流发布:阿里通义千问首个开源图像生成模型阿里巴巴通义千问团队正式推出其首个开源图像生成基础模型 —— Qwen-Image。 这是一个基于 MMDiT(Multi-Modal Diffusion Transformer) 架构的 20B 参...工作流# ComfyUI# Qwen-Image8个月前02,2200
阿里 Qwen 项目组发布 Qwen-Image:首个 20B 级 MMDiT 图像生成基础模型阿里 Qwen 项目组正式推出 Qwen-Image,这是通义千问系列中首个专注于图像生成的基础大模型。基于 20B 参数的 MMDiT(Multimodal Diffusion Transforme...图像模型# Qwen-Image# 图像生成模型8个月前04760