
阿里巴巴通义千问团队正式推出其首个开源图像生成基础模型 —— Qwen-Image。
这是一个基于 MMDiT(Multi-Modal Diffusion Transformer) 架构的 20B 参数大模型,采用 Apache 2.0 开源许可证,支持多语言高保真文本渲染与精确图像编辑,已在 GitHub、Hugging Face 和 ModelScope 全面上线。

该模型在复杂提示理解、跨语言文本生成、艺术风格控制等方面表现突出,尤其在中英文混合输入下的排版与字体还原能力上达到领先水平。
为方便开发者快速上手,官方同步发布了 Qwen-Image 原生 ComfyUI 工作流示例,支持本地部署与自定义调优。
模型亮点:不止于“文生图”
Qwen-Image 并非简单的扩散模型,而是一个具备强大多模态理解能力的生成系统,核心优势包括:
✅ 卓越的多语言文本渲染
- 支持 中文、英文、日语、韩语、意大利语 等多种语言;
- 在图像中准确保留文字内容、字体样式与布局结构,适用于海报、广告、UI 设计等场景;
- 中文长文本生成清晰可读,无乱码或字符断裂问题。
✅ 多样化艺术风格适应
- 从照片级写实到印象派绘画;
- 从动漫美学到极简平面设计;
- 能根据提示词自动匹配风格特征,无需额外 LoRA 微调。
✅ 高保真图像生成
- 基于 MMDiT 架构,提升细节生成质量;
- 支持 1024×1024 及更高分辨率输出;
- 提供 FP8 与 BF16 两种精度版本,兼顾性能与画质。
如何运行 Qwen-Image?ComfyUI 原生工作流详解
官方提供了一套完整的 ComfyUI 原生工作流,帮助用户快速部署和测试 Qwen-Image。
⚠️ 注意:该工作流依赖最新功能,必须使用 ComfyUI 最新开发版(nightly)。
🔧 环境准备
- 安装 ComfyUI
- 推荐使用 ComfyUI 官方仓库 的
nightly分支; - 不建议使用稳定版(release)或桌面版(desktop),因缺少新节点支持。
- 推荐使用 ComfyUI 官方仓库 的
- 更新 ComfyUI 到最新 commit
git pull origin nightly若加载工作流时报错“节点缺失”,请确认是否成功更新并重启 ComfyUI。
模型下载
Qwen-Image 提供两个精度版本,均托管于 Hugging Face 与 魔搭(ModelScope):
| 模型组件 | 文件名 | 大小 |
|---|---|---|
| 扩散模型 | qwen_image_fp8_e4m3fn.safetensors | 20.4 GB |
qwen_image_bf16.safetensors | 40.9 GB | |
| 文本编码器(CLIP) | qwen_2.5_vl_7b_fp8_scaled.safetensors | - |
| VAE 解码器 | qwen_image_vae.safetensors | - |
下载地址:
- Hugging Face:https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/tree/main
- 魔搭:https://modelscope.cn/models/Comfy-Org/Qwen-Image_ComfyUI/files
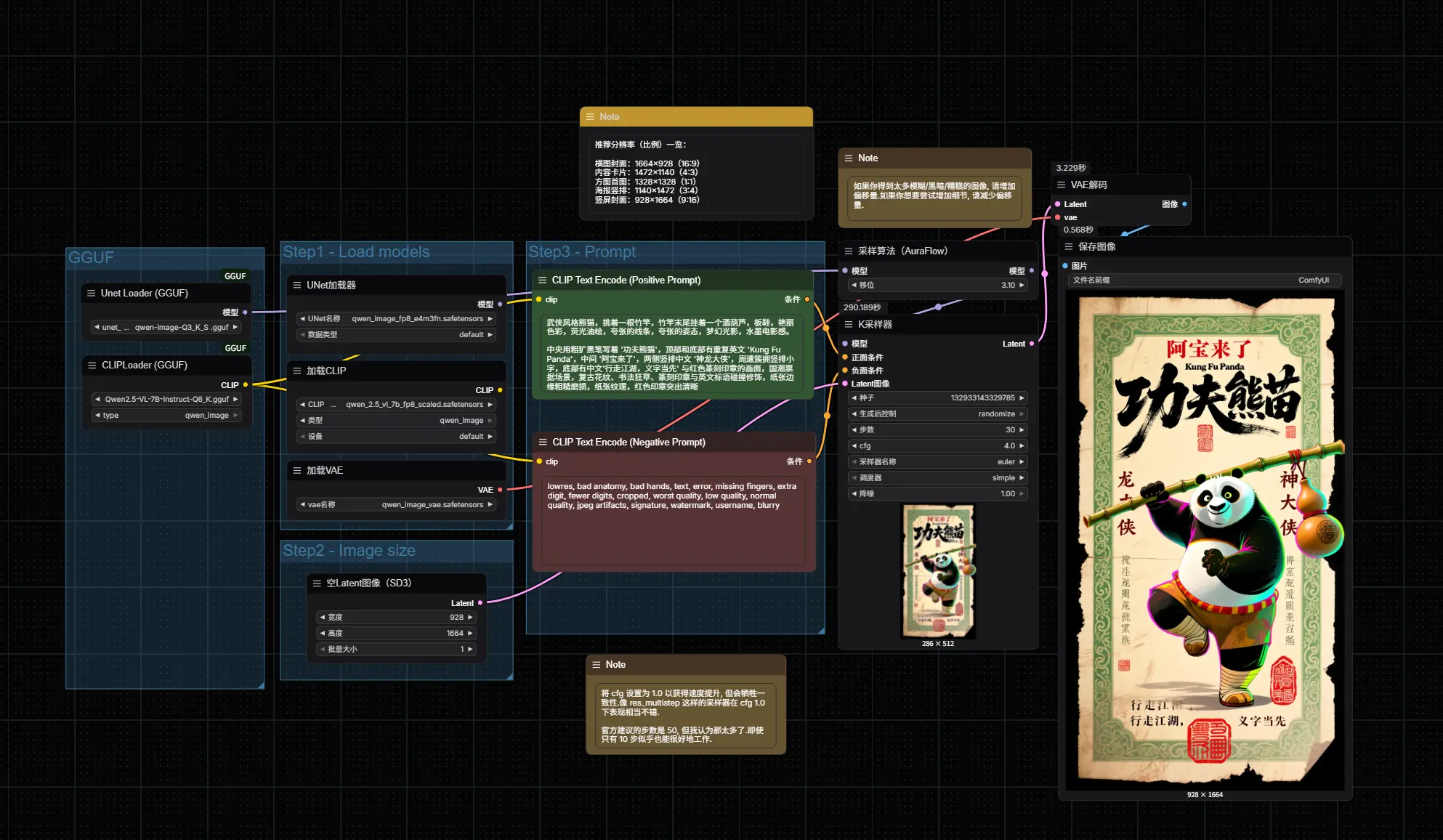
- GGUF版:https://modelscope.cn/models/city96/Qwen-Image-gguf
🛠️ 工作流配置步骤
在 ComfyUI 中加载官方提供的工作流文件(JSON 格式);
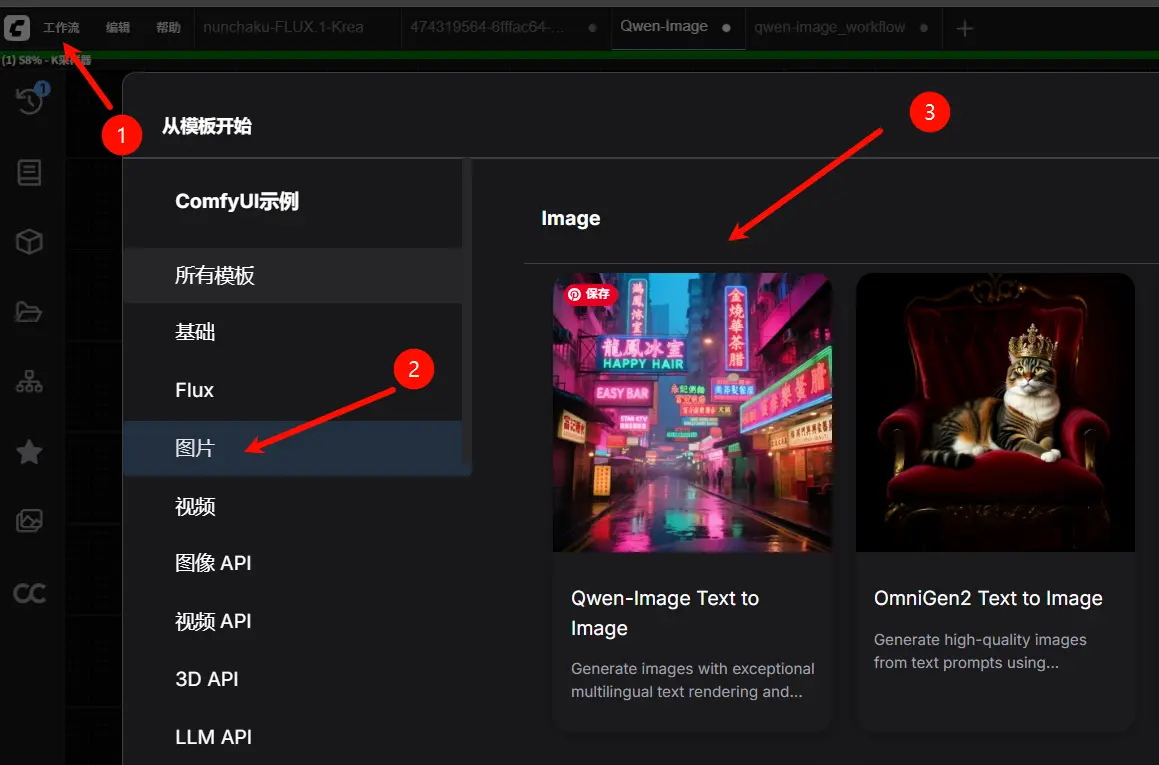
按步骤完成工作流
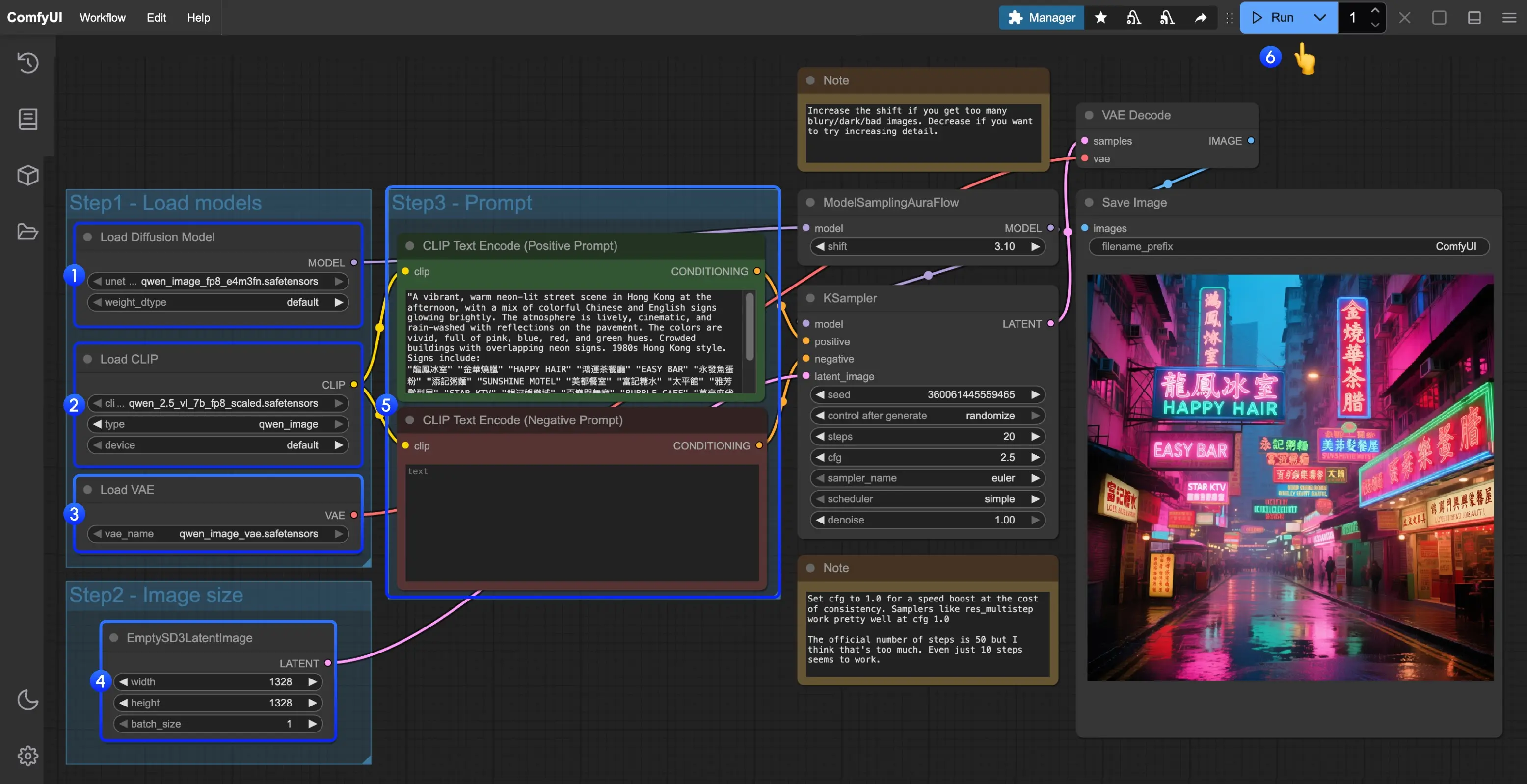
- 按以下顺序检查模型加载:
- Load Diffusion Model 节点 → 加载
qwen_image_fp8_e4m3fn.safetensors或qwen_image_bf16.safetensors - Load CLIP 节点 → 加载
qwen_2.5_vl_7b_fp8_scaled.safetensors - Load VAE 节点 → 加载
qwen_image_vae.safetensors
- Load Diffusion Model 节点 → 加载
- 设置图像尺寸:
- 使用 EmptySD3LatentImage 节点设定输出分辨率(如 1024×1024)
- 输入提示词:
- 在 CLIP Text Encoder 节点中输入自然语言描述,支持多语言混合输入
- 运行生成:
- 点击 Queue 按钮,或使用快捷键
Ctrl/Cmd + Enter
- 点击 Queue 按钮,或使用快捷键
推荐分辨率(比例)一览:
横图封面:1664×928(16:9)
内容卡片:1472×1140(4:3)
方图首图:1328×1328(1:1)
海报竖排:1140×1472(3:4)
竖屏封面:928×1664(9:16)
显存与性能参考(RTX 4090D 24GB)
| 模型版本 | 显存占用 | 首次生成时间 | 第二次生成时间 |
|---|---|---|---|
| FP8 | 86% (~20.6 GB) | 94 秒 | 71 秒 |
| BF16 | 96% (~23.0 GB) | 295 秒 | 131 秒 |
💡 建议优先使用 FP8 版本,在画质损失极小的前提下大幅提升推理效率。如果显存不足,建议试用GGUF版本模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











