
ComfyUI官方宣布已原生支持Wan2.2 14B FLF2V(首尾帧视频生成) ,你现在可以直接在 ComfyUI 中,仅通过一张起始帧和一张结束帧图像,生成一段自然过渡的视频序列。

这一功能为创意表达提供了全新可能——无论是角色状态变化、场景演变,还是情绪转换,都可以通过“首尾控制”实现结构化动态生成。
- 模型下载:https://www.modelscope.cn/models/Comfy-Org/Wan_2.2_ComfyUI_Repackaged
- GGUF版:https://www.modelscope.cn/models/QuantStack/Wan2.2-I2V-A14B-GGUF
什么是 FLF2V?
FLF2V(First-Last Frame to Video) 是 Wan2.2 系列模型中的一种特殊推理模式,允许你:
- 输入:一张起始帧图像 + 一张结束帧图像
- 输出:一段从起始帧平滑过渡到结束帧的短视频
与传统 i2v(图像到视频)仅依赖单帧外推运动不同,FLF2V 引入了目标引导机制,让生成过程更具方向性和可控性。
✅ 适用场景:人物表情变化、姿态演进、环境光照转变、服装替换等“状态迁移”类视频生成。
使用前提
要使用该功能,请确保满足以下条件:
- ComfyUI 版本要求:
- 更新至最新版(Git 主干 / 便携版 / 桌面版)
- 硬件建议:
- 显存 ≥ 12GB(FP16 推理)
- 若显存有限,可使用较低分辨率(如 480×480)
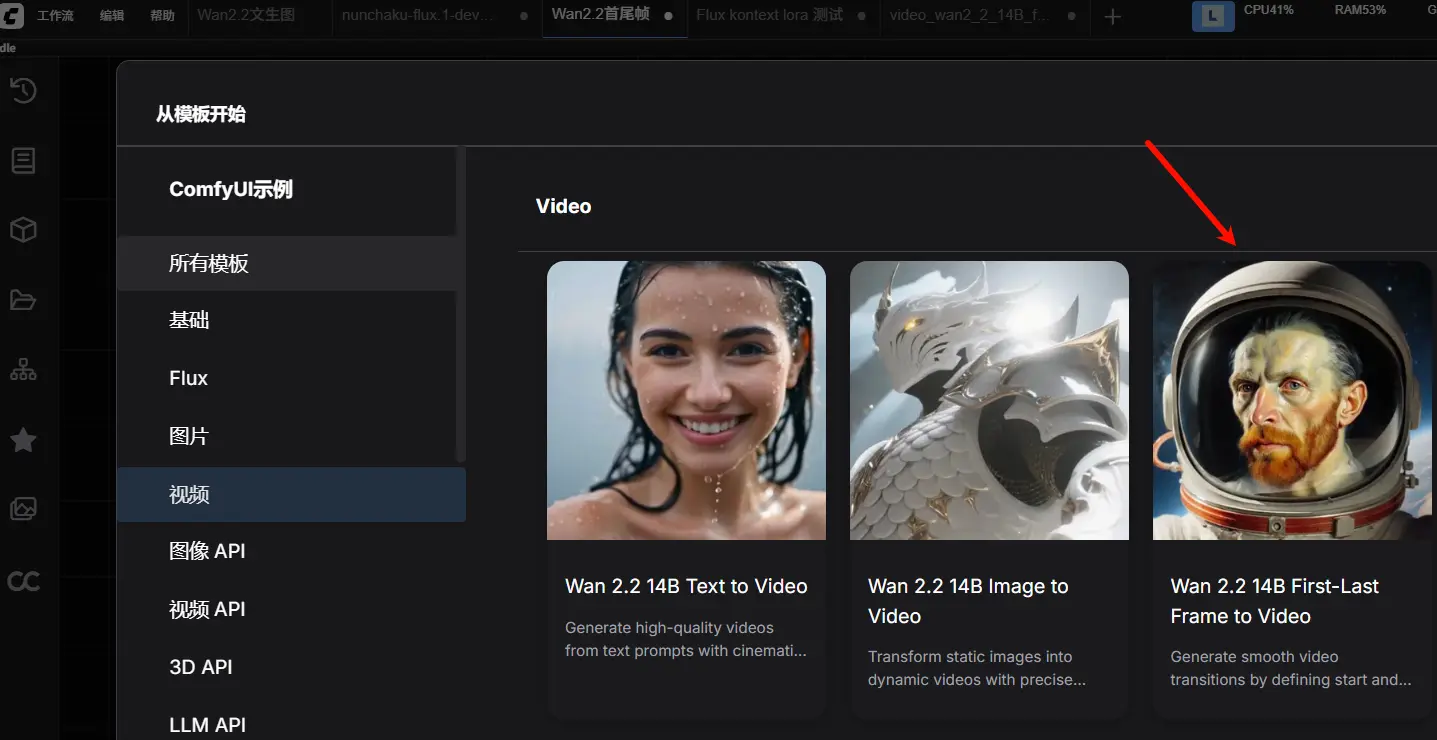
加载工作流
ComfyUI 官方已内置该功能模板,操作如下:
- 点击菜单栏:工作流 → 视频 → Wan 2.2 14B First-Last Frame to Video
- 系统将自动加载预设工作流
- 确保所有节点正常连接,无红色报错
⚠️ 若节点报错,请检查是否已更新 ComfyUI 至最新版本,并确认模型路径正确。
操作步骤详解
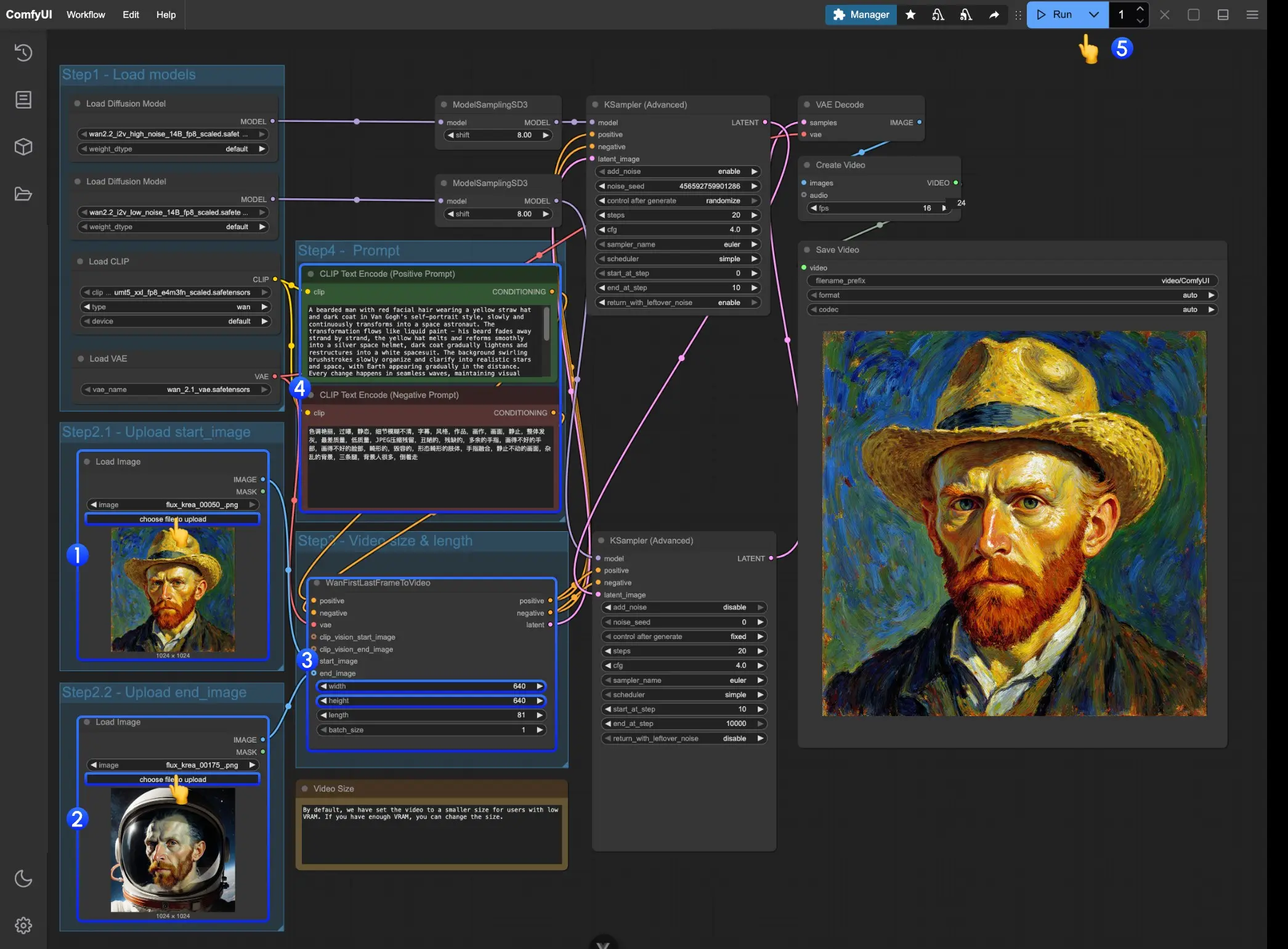
1. 上传首尾帧图像
- 第一个 Load Image 节点:上传起始帧图像
- 第二个 Load Image 节点:上传结束帧图像
📌 要求:
- 两图分辨率一致
- 主体位置尽量对齐(避免剧烈构图跳跃)
- 建议使用同一人物/场景的不同状态图像
2. 设置视频参数
在 WanFirstLastFrameToVideo 节点中调整以下设置:
| 参数 | 建议值 |
|---|---|
| 分辨率 | 默认较小(如 640×640),可提升至 720P(1280×720) |
| 帧数 | 官方默认为 81帧 |
| 帧率 | 16 fps |
💡 提示:高分辨率会显著增加显存占用,建议逐步测试。
3. 编写提示词(Prompt)
- 描述从起始状态到结束状态的变化过程
- 示例:
The person gradually turns from serious to smiling, eyes lighting up, slight head tilt forward - 避免只描述某一帧状态,应强调“过渡”与“动态”
4. 执行生成
- 点击 Run 按钮
- 或使用快捷键:Ctrl + Enter(Windows) / Cmd + Enter(Mac)
生成完成后,视频将自动保存至 output/ 目录。
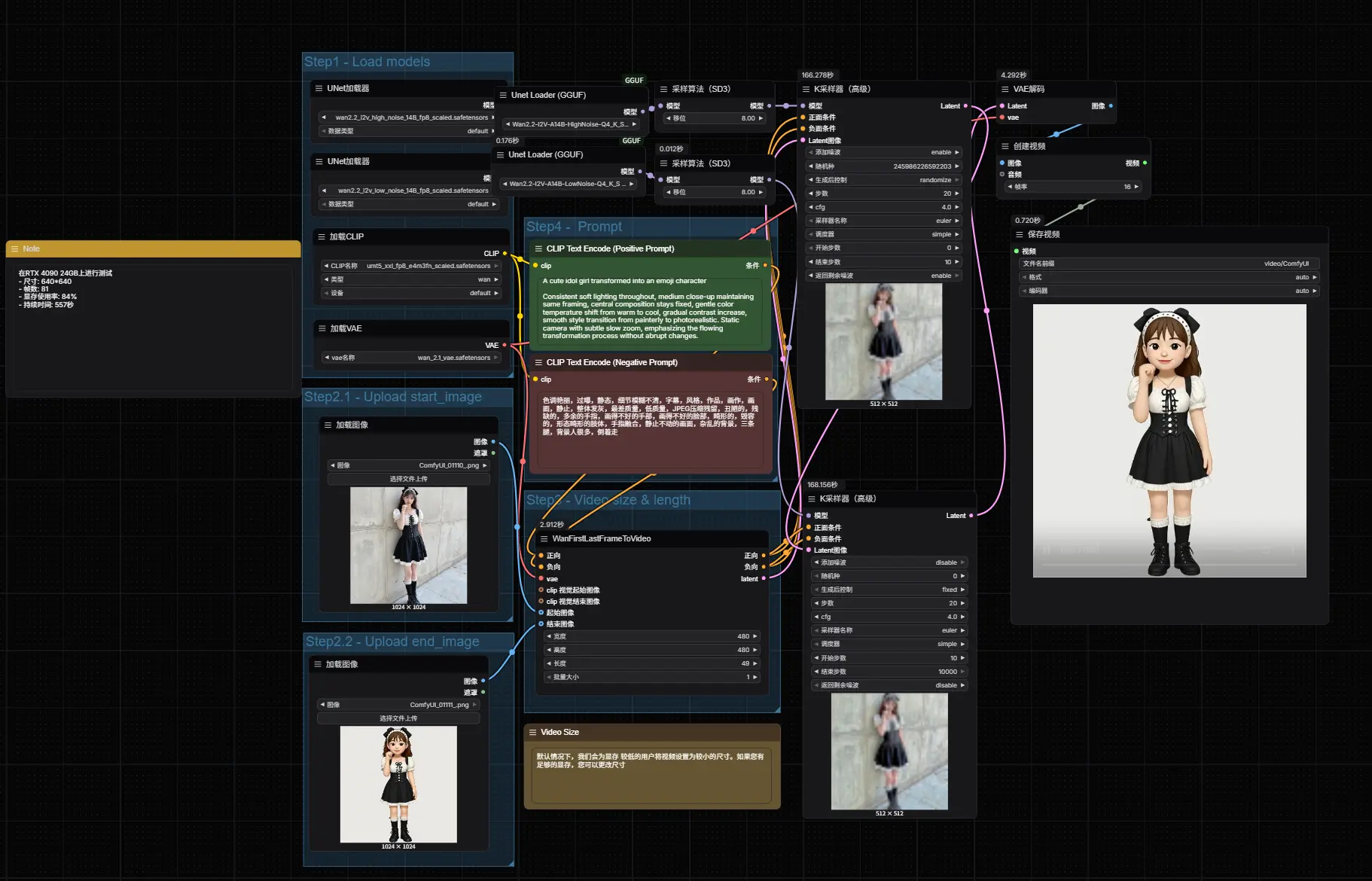
最佳实践建议
✅ 推荐做法
- 使用清晰、对齐良好的首尾帧,可使用 FLUX.1 Kontext Dev来生成尾帧图片;
- 提示词聚焦“变化过程”而非静态描述;
- 初始测试使用低分辨率,验证逻辑后再放大;
- 可结合 VAE 提升色彩还原度。
❌ 避免情况
- 首尾帧主体不一致(如换人、换场景);
- 构图差异过大(如近景变远景);
- 提示词空缺或过于抽象。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











