阿里巴巴通义千问团队发布的 Qwen-Image,是首个基于 MMDiT 架构的开源图像生成基础模型,参数规模达 20B,采用 Apache 2.0 许可证开放,支持高分辨率、多轮对话式图像生成。
- Hugging Face:Qwen-Image-DiffSynth-ControlNets | Qwen-Image-InstantX-ControlNets
- 魔塔:Qwen-Image-DiffSynth-ControlNets | Qwen-Image-InstantX-ControlNets
- comfyui_controlnet_aux插件:https://github.com/Fannovel16/comfyui_controlnet_aux
随着社区生态的发展,目前已涌现出多种 ControlNet 与 LoRA 控制方案,帮助用户实现对生成图像的结构化引导,如边缘、深度、姿态、线稿等控制。
本文将系统梳理当前主流的三种控制方式:
- InstantX 统一 ControlNet
- DiffSynth Model Patches(模型补丁)
- DiffSynth Union LoRA
每种方案在兼容性、灵活性与部署方式上各有特点,适用于不同使用场景。
前置说明:Qwen-Image基础环境与核心概念
在开始具体工作流操作前,需先明确两个关键前提,避免后续部署出错:
- 基础环境:所有工作流均基于ComfyUI运行,请将ComfyUI升级到最新开发版(nightly),下载所需模型;
- 核心差异:三类ControlNet方案的本质不同——InstantX是“统一ControlNet模型”,DiffSynth是“模型补丁(Model Patch)”,Union是“控制型LoRA”,对应的文件存放路径、预处理逻辑均有区别,需重点注意模型保存位置(后文会逐一标注)。
- 工作流:所需工作流均可在工作流模板中获取,点击即可加载。
方案概览:三种控制方式对比
| 方案 | 类型 | 支持控制类型 | 模型位置 |
|---|---|---|---|
| InstantX ControlNet | 统一 ControlNet 模型 | canny, soft edge, depth, pose | models/controlnet/ |
| DiffSynth Model Patches | 模型补丁(Model Patch) | canny, depth, inpaint | models/model_patches/ |
| DiffSynth Union LoRA | LoRA 模型 | canny, depth, pose, lineart, softedge, normal, openpose | models/loras/ |
下面逐一介绍各方案的使用方法与注意事项。
方案一:InstantX统一ControlNet(支持4类控件,新手友好,对硬件要求高)
InstantX团队推出的Qwen-Image-InstantX-ControlNet-Union是“一站式控制模型”,无需切换多个文件,直接支持canny(线稿)、soft edge(软边缘)、depth(深度)、pose(姿势) 4种常见控制类型,适合新手快速入门。
1. 准备工作:下载模型与工具
需下载两类核心文件,注意区分保存路径:
| 文件类型 | 具体文件名 | 保存路径 | 说明 |
|---|---|---|---|
| 统一ControlNet模型 | Qwen-Image-InstantX-ControlNet-Union.safetensors | ComfyUI/models/controlnet/ | 核心控制模型,必须正确放置 |
| 深度图生成模型(Lotus Depth) | lotus-depth-d-v1-1.safetensors | ComfyUI/models/diffusion_models/ | 用于生成depth控制所需的深度图 |
| VAE模型 | vae-ft-mse-840000-ema-pruned.safetensors(或任意SD1.5 VAE) | ComfyUI/models/vae/ | 配合Lotus Depth生成高质量深度图,SD1.5 VAE可通用 |
此外,若需处理其他类型图像(如pose),建议安装comfyui_controlnet_aux自定义节点(ComfyUI中搜索节点名称即可安装),用于完成pose检测等预处理。


2. 分步操作指南
- 确认模型加载:找到“Load ControlNet Model”节点,检查其加载的模型是否为“Qwen-Image-InstantX-ControlNet-Union.safetensors”(路径正确则会自动识别,若未加载需手动选择);
- 上传输入图像:在“Load Image”节点中上传需要控制的原始图像(如人物照、场景照);
- 处理深度图(仅depth控制需此步):
- 若使用depth控制,找到工作流中的“Lotus Depth子图”(ComfyUI中可双击子图查看细节);
- 确保“Lotus Depth模型”(lotus-depth-d-v1-1.safetensors)和“VAE模型”已正确加载,子图会自动将原始图像预处理为深度图;
- 运行工作流:点击界面顶部“Run”按钮,或使用快捷键Ctrl(Windows)/Cmd(Mac)+ Enter,等待生成结果。
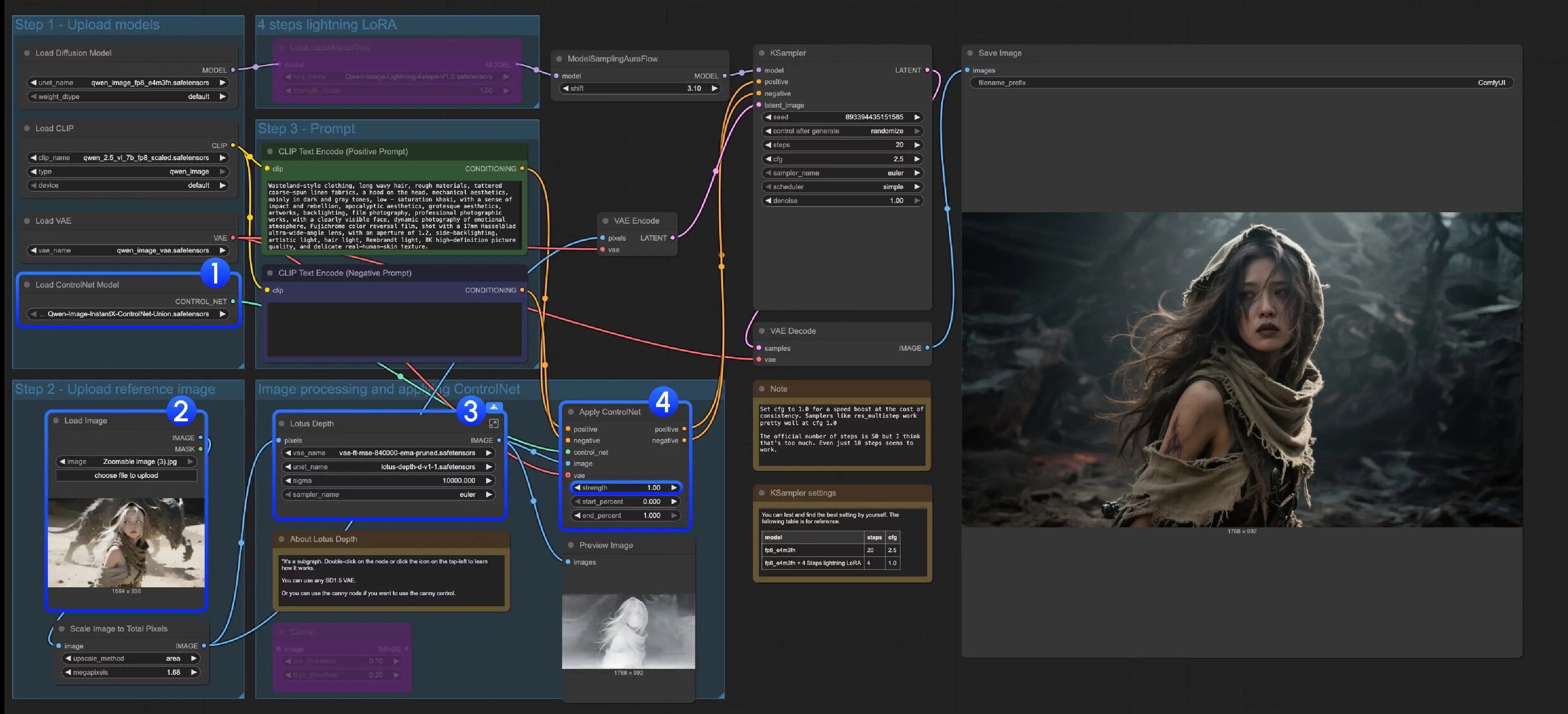
3. 注意事项
- 若需切换控制类型(如从canny改为pose),只需替换“图像预处理节点”(如用comfyui_controlnet_aux的pose检测节点替换canny节点),核心ControlNet模型无需更换;
- 生成结果若控制效果过强/过弱,可调整“ControlNet Apply”节点中的“strength”参数(数值越高,控制越严格,建议从0.7开始测试)。
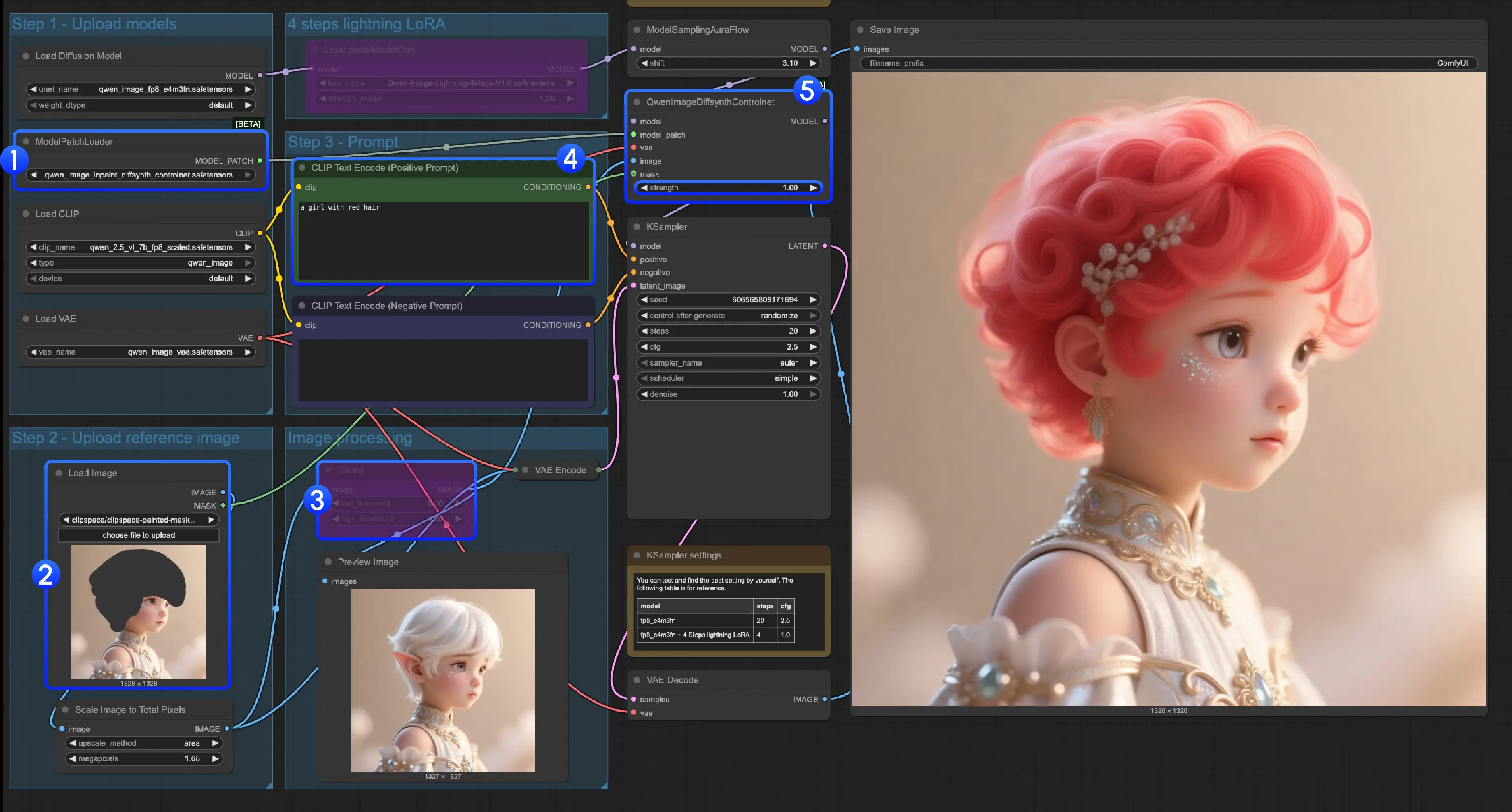
方案二:DiffSynth-ControlNets模型补丁(分3类模型,精准适配场景)
DiffSynth-Studio的方案并非传统ControlNet,而是“模型补丁(Model Patch)”,需根据控制类型选择对应的补丁文件,支持canny、depth、inpaint(重绘) 三类场景,适合对“局部控制精度”有高要求的用户。

1. 准备工作:下载模型补丁
该方案无需额外下载ControlNet模型,只需下载3个补丁文件,注意保存路径为ComfyUI/models/model_patches/(与ControlNet路径不同,不可混淆):
- qwen_image_canny_diffsynth_controlnet.safetensors(canny控制补丁)
- qwen_image_depth_diffsynth_controlnet.safetensors(depth控制补丁)
- qwen_image_inpaint_diffsynth_controlnet.safetensors(inpaint控制补丁)

其他基础模型(如Qwen-Image主模型、VAE)与Qwen-Image基础工作流一致,无需重复下载。

2. 分类型操作指南
三类补丁的使用逻辑不同,需分别设置预处理步骤,以下为详细流程:
(1)Canny控制(线稿轮廓控制)
- 加载补丁模型:找到“ModelPatchLoader”节点,选择“qwen_image_canny_diffsynth_controlnet.safetensors”;
- 预处理图像:使用ComfyUI原生的“Canny”节点(无需额外安装),上传原始图像后,通过调整“low threshold”“high threshold”参数(建议low=100、high=200,可根据图像细节微调),生成线稿轮廓;
- 调整控制强度:在“QwenImageDiffsynthControlnet”节点中,修改“strength”参数(默认0.8,数值越高线稿控制越明显);
- 运行:点击“Run”或使用快捷键,生成符合线稿轮廓的图像。
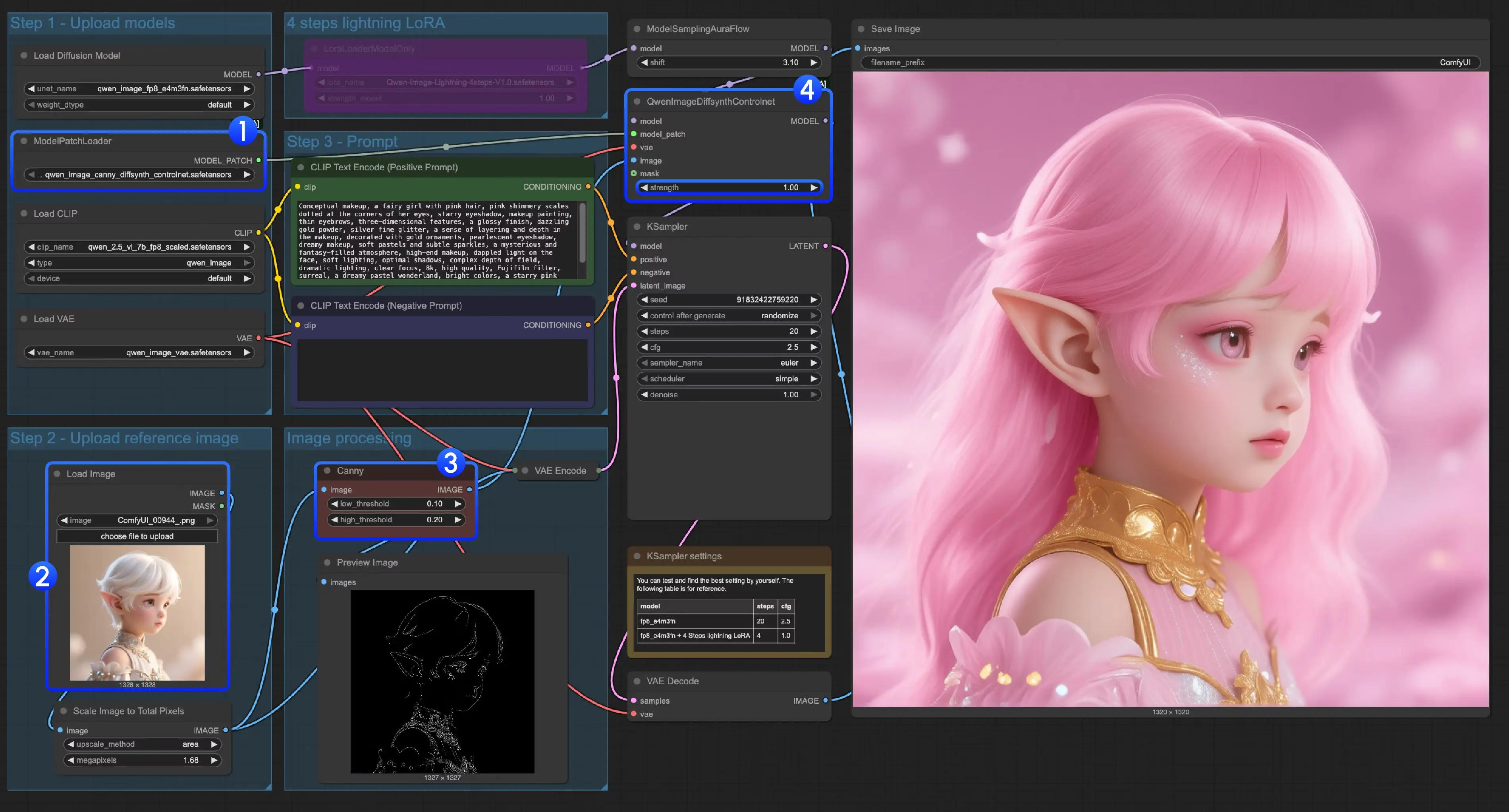
(2)Depth控制(空间关系控制)
- 加载补丁模型:“ModelPatchLoader”节点选择“qwen_image_depth_diffsynth_controlnet.safetensors”;
- 生成深度图:参考InstantX工作流的“Lotus Depth子图”逻辑,用Lotus Depth模型将原始图像预处理为深度图,替换工作流中的“image processing”节点输出;
- 运行:后续步骤与Canny控制一致,无需额外调整其他节点。
(3)Inpaint控制(局部重绘控制)
Inpaint需额外处理“蒙版(Mask)”,步骤稍多:
- 加载补丁模型:“ModelPatchLoader”节点选择“qwen_image_inpaint_diffsynth_controlnet.safetensors”;
- 上传图像与绘制蒙版:
- 在“Load Image”节点上传原始图像;
- 使用ComfyUI自带的“蒙版编辑器”(点击“Load Image”节点的“mask”按钮),用画笔标记需要重绘的区域(标记区域为白色,未标记为黑色);
- 将“Load Image”节点的“mask”输出端,连接到“QwenImageDiffsynthControlnet”节点的“mask”输入端,确保蒙版生效;
- 绕过Canny节点:由于Inpaint无需线稿控制,按下快捷键Ctrl+B,将工作流中的“Canny”节点设置为“绕过模式”(节点会显示灰色,不再参与处理);
- 输入重绘指令:在“CLIP Text Encoder”节点中,输入对蒙版区域的重绘需求(如“将蒙版区域改为蓝色天空,保持其他部分不变”);
- 运行:点击“Run”,模型会仅对蒙版区域进行重绘,保留非蒙版区域的原始内容。
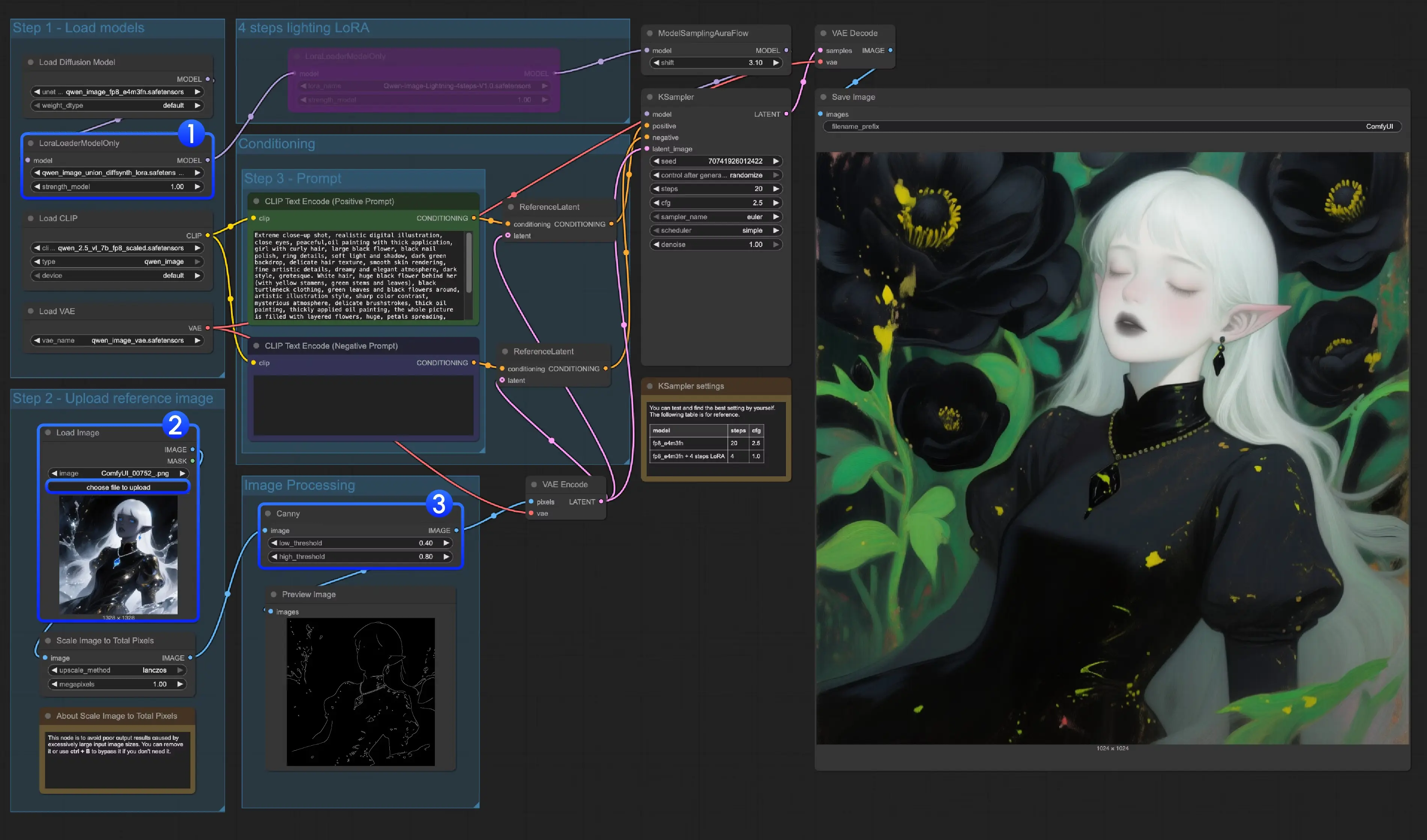
方案三:Union ControlNet LoRA(支持7类控件,灵活度最高,硬件要求低推荐使用)
DiffSynth-Studio的qwen_image_union_diffsynth_lora是“控制型LoRA”,无需单独加载ControlNet模型,直接通过LoRA注入控制能力,支持canny、depth、pose、lineart(线稿)、softedge(软边缘)、normal(法向量)、openpose(骨骼姿势) 7类控制类型,灵活度最高。

1. 准备工作:下载LoRA模型
仅需下载1个LoRA文件,保存路径为ComfyUI/models/loras/(LoRA专属路径,不可放错):

2. 操作指南
- 加载LoRA模型:找到“LoraLoaderModelOnly”节点,选择“qwen_image_union_diffsynth_lora.safetensors”,确保LoRA成功注入(节点会显示LoRA名称及权重);
- 上传与预处理图像:
- 上传原始图像后,根据控制类型选择预处理节点(如canny用原生Canny节点,pose用comfyui_controlnet_aux的OpenPose节点);
- 若预处理效果不佳(如线稿细节过少),可调整预处理节点参数(如Canny的阈值、OpenPose的骨骼检测精度);
- 运行工作流:点击“Run”或使用快捷键,生成结果。
3. 注意事项
- 该LoRA支持多类控制,但同一时间建议仅使用一种控制类型(如同时开启canny和depth可能导致效果冲突);
- 若需切换控制类型,只需替换预处理节点(如将Canny节点换成Lineart节点),LoRA模型无需重新加载。
通用注意事项
- 建议安装
comfyui_controlnet_aux插件,支持自动预处理图片; - 不同输入图像可能需要调整预处理参数(如 Canny 的低/高阈值);
- Qwen-Image 对输入尺寸有一定要求,建议使用官方推荐分辨率。
推荐分辨率(比例)一览:
- 横图封面:1664×928(16:9)
- 内容卡片:1472×1140(4:3)
- 方图首图:1328×1328(1:1)
- 海报竖排:1140×1472(3:4)
- 竖屏封面:928×1664(9:16)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











