
在使用 Qwen-Image-Edit 进行图像编辑时,不少用户会遇到图像出现意外更改(如莫名放大)的问题。这一现象并非模型本身缺陷,而是节点设置、模型尺寸要求与内部预处理逻辑共同作用的结果。

本文将详细解析问题成因,并提供可落地的规避策略与最佳实践。
一、关键问题:TextEncodeQwenImageEdit 节点可能引发非预期图像变化
TextEncodeQwenImageEdit 是 Qwen 图像编辑工作流中的核心节点,负责编码参考图像与文本提示。但该节点默认行为包含一个隐式操作:
它会通过内置 VAE 编码器生成参考潜变量(latent)。
这意味着:
- 如果你不加干预,该节点将自动处理输入图像,生成潜变量;
- 当你后续使用
ReferenceLatent或其他自定义潜变量节点时,若未断开连接,可能出现潜变量来源冲突; - 最终导致生成图像出现非预期的形变、放大或细节错位(如视频中所示)。
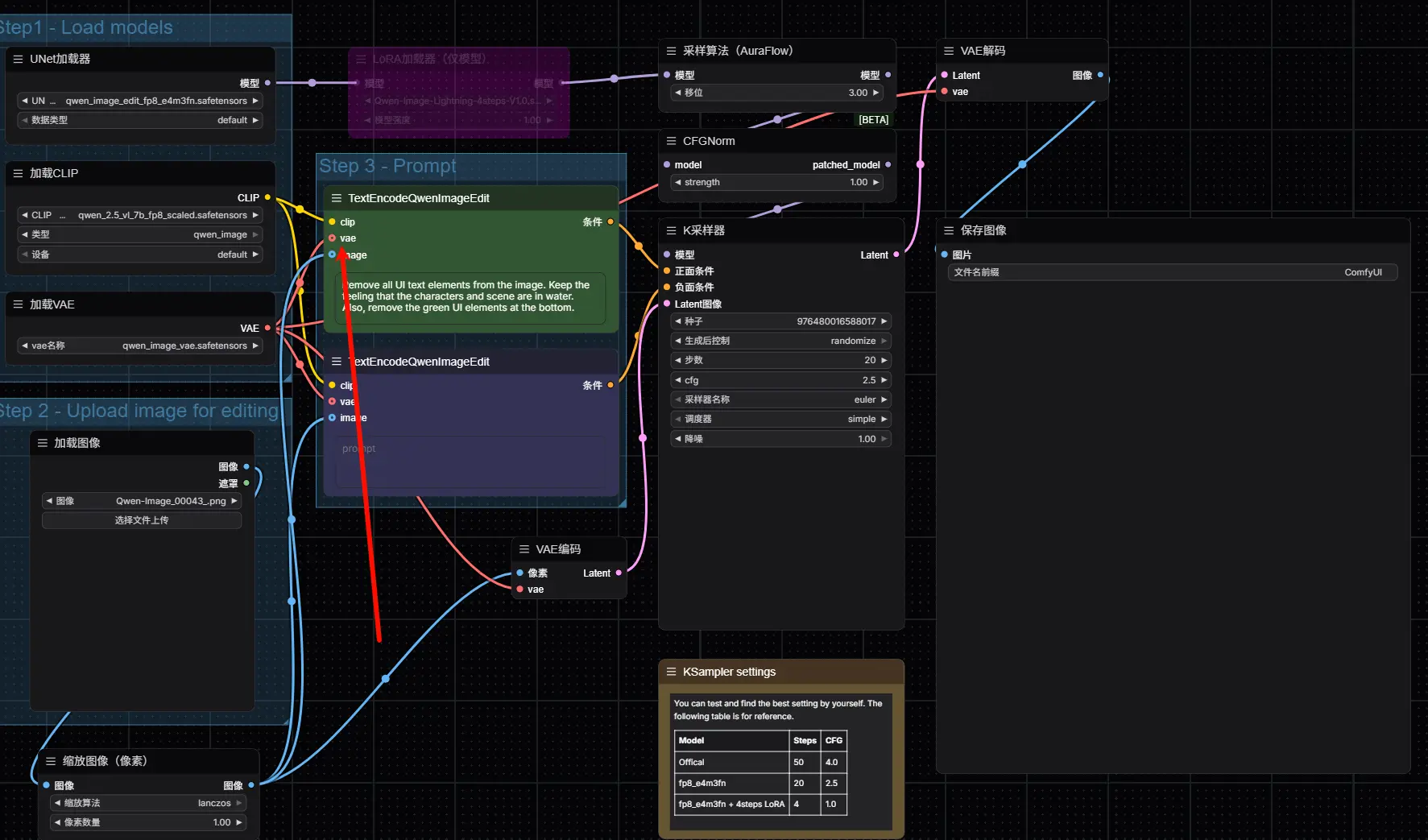
✅ 正确做法:
如果你希望使用自定义参考潜变量(例如通过独立 VAE 编码),请务必:
断开
TextEncodeQwenImageEdit节点上的 VAE 输入连接
这样可防止其内部重新编码图像,避免潜变量不一致问题。
二、图像尺寸不匹配:VAE 与视觉编码器的“最小公倍数”陷阱
更深层的问题来自 VAE 解码机制 与 Qwen2.5-VL 视觉编码结构之间的尺寸对齐问题。
核心差异:
| 组件 | 尺寸要求 |
|---|---|
| VAE(潜变量编码) | 基于 ×8 下采样 → 要求图像宽高为 16 的倍数 |
| Qwen2.5-VL 视觉编码器 | 使用 14×14 图像块(patch)→ 要求图像宽高为 14 的倍数 |
两者的最小公倍数为 LCM(16, 14) = 112
实际影响:
- 若输入图像尺寸不是 112 的倍数,VAE 和视觉编码器会对图像进行不同方式的填充或重采样;
- 导致潜变量空间与语义特征空间错位;
- 最终在生成阶段引发伪影、拉伸、放大效应等视觉异常。
🔍 示例:输入图像为 1024×1024(16 的倍数,但非 14 的倍数),系统会自动调整至符合 Qwen 输入要求,造成轻微放大。
三、TextEncodeQwenImageEdit 内部的自动缩放机制
该节点在预处理阶段会强制将输入图像调整为约 100 万像素(如 1024×1024 或 1344×768 等),以适配模型训练时的数据分布。
这意味着:
- 即使你输入了 112 的倍数尺寸,也可能被进一步重采样;
- 潜变量图像(由 KSampler 使用)与参考潜变量之间仍可能存在分辨率错配;
- 特别是在高精度编辑任务中,这种差异会被放大。
四、推荐解决方案与最佳实践
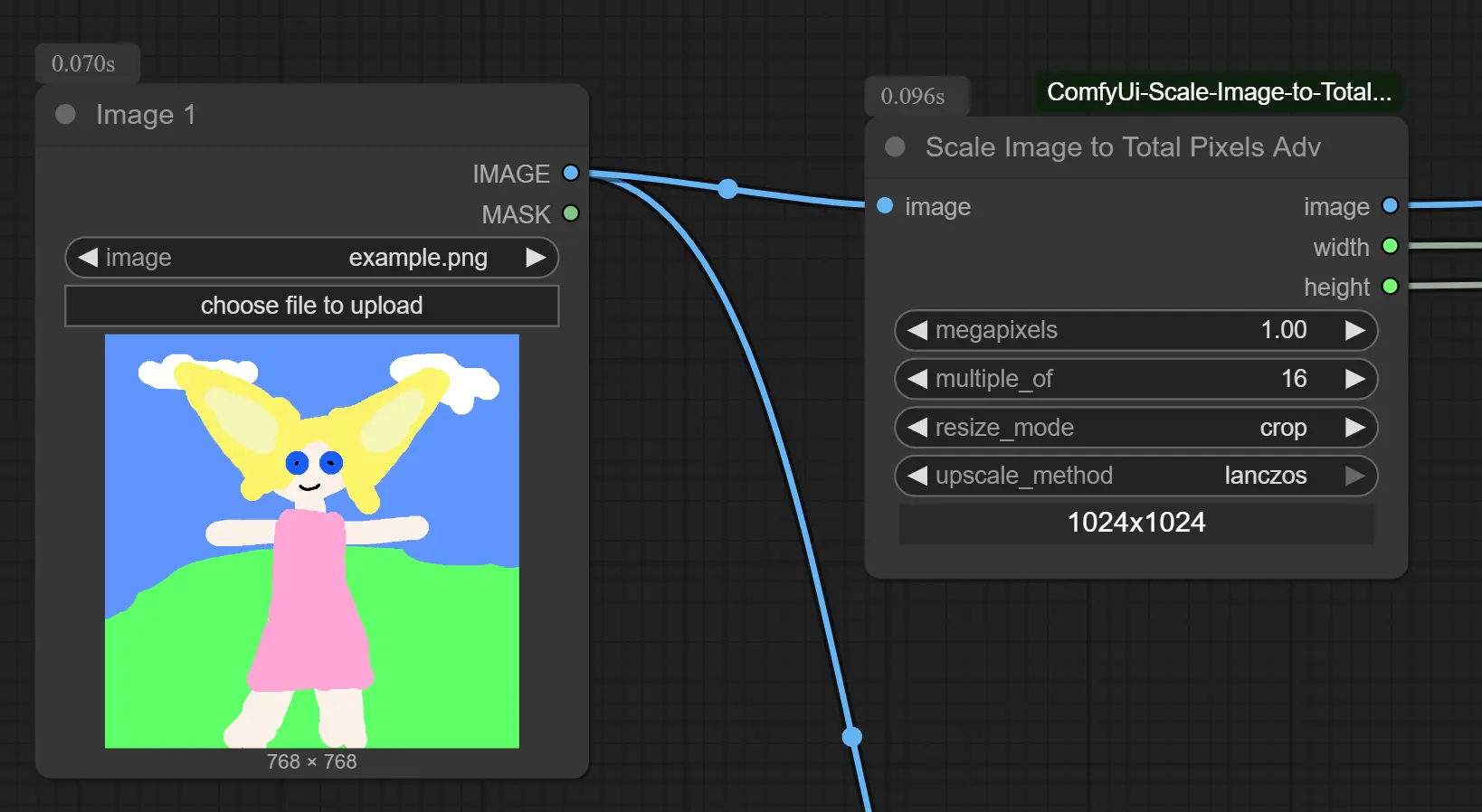
✅ 1. 统一输入图像尺寸为 112 的倍数
建议将所有输入图像预处理为:
- 宽高均为 112 的整数倍(如 896×896、1344×1344)
- 或使用
Scale Image to Total Pixels Adv节点,设置目标像素接近 1M 且尺寸满足 112×n
📌 提示:可在 ComfyUI Manager中安装该节点
✅ 2. 显式控制参考潜变量流程
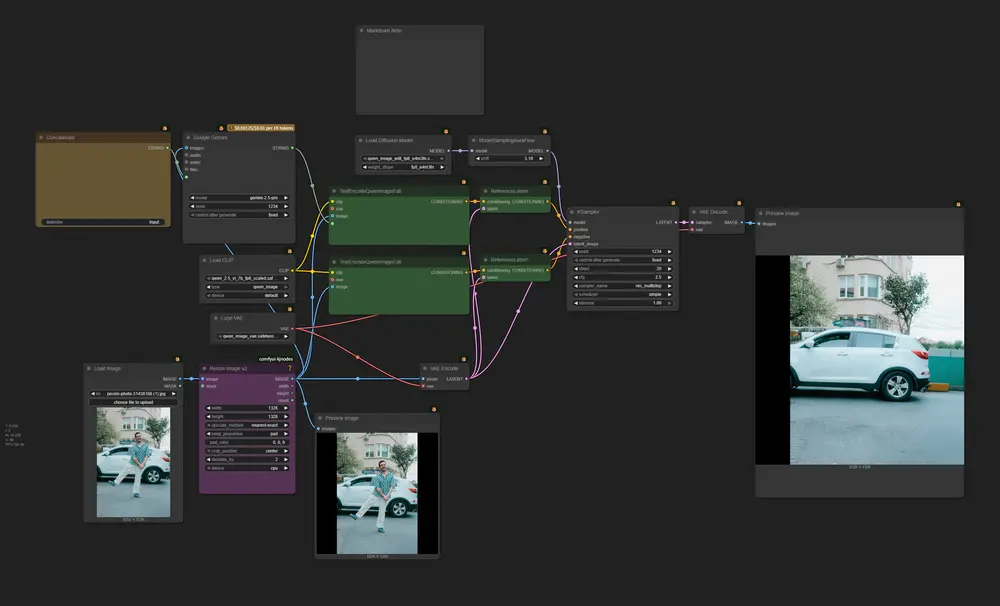
构建工作流时采用以下结构:
[输入图像]
↓
[VAE Encode] → [ReferenceLatent]
↓
[断开 TextEncodeQwenImageEdit 的 VAE 输入]
↓
TextEncodeQwenImageEdit(仅用于文本+图像特征编码)
这样可确保:
- 潜变量由你完全控制;
- 避免节点内部重复编码;
- 保持编辑过程的空间一致性。
- 工作流下载:https://pan.quark.cn/s/e5b9621fa0c1 提取码:B83V
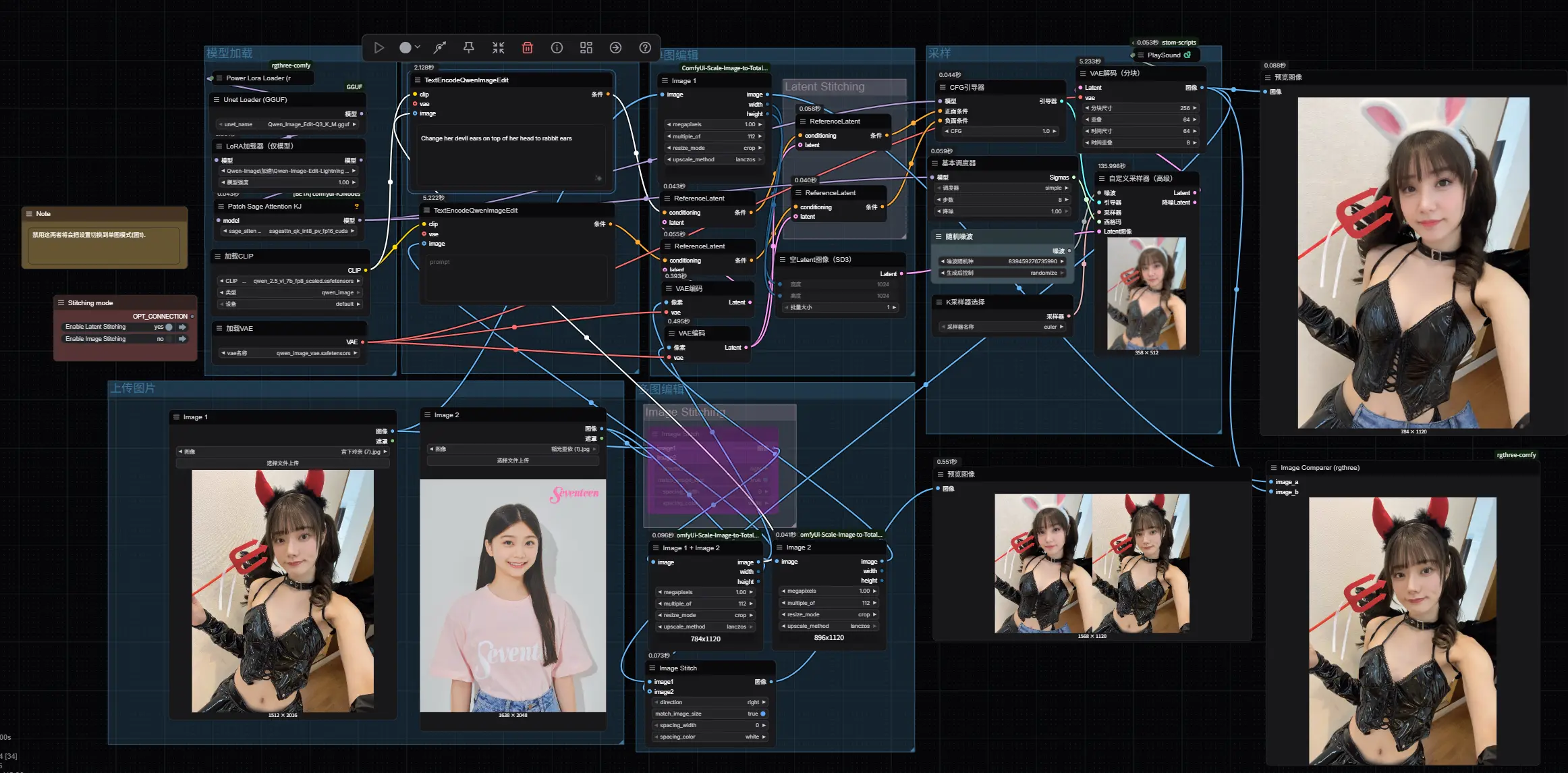
单图编辑
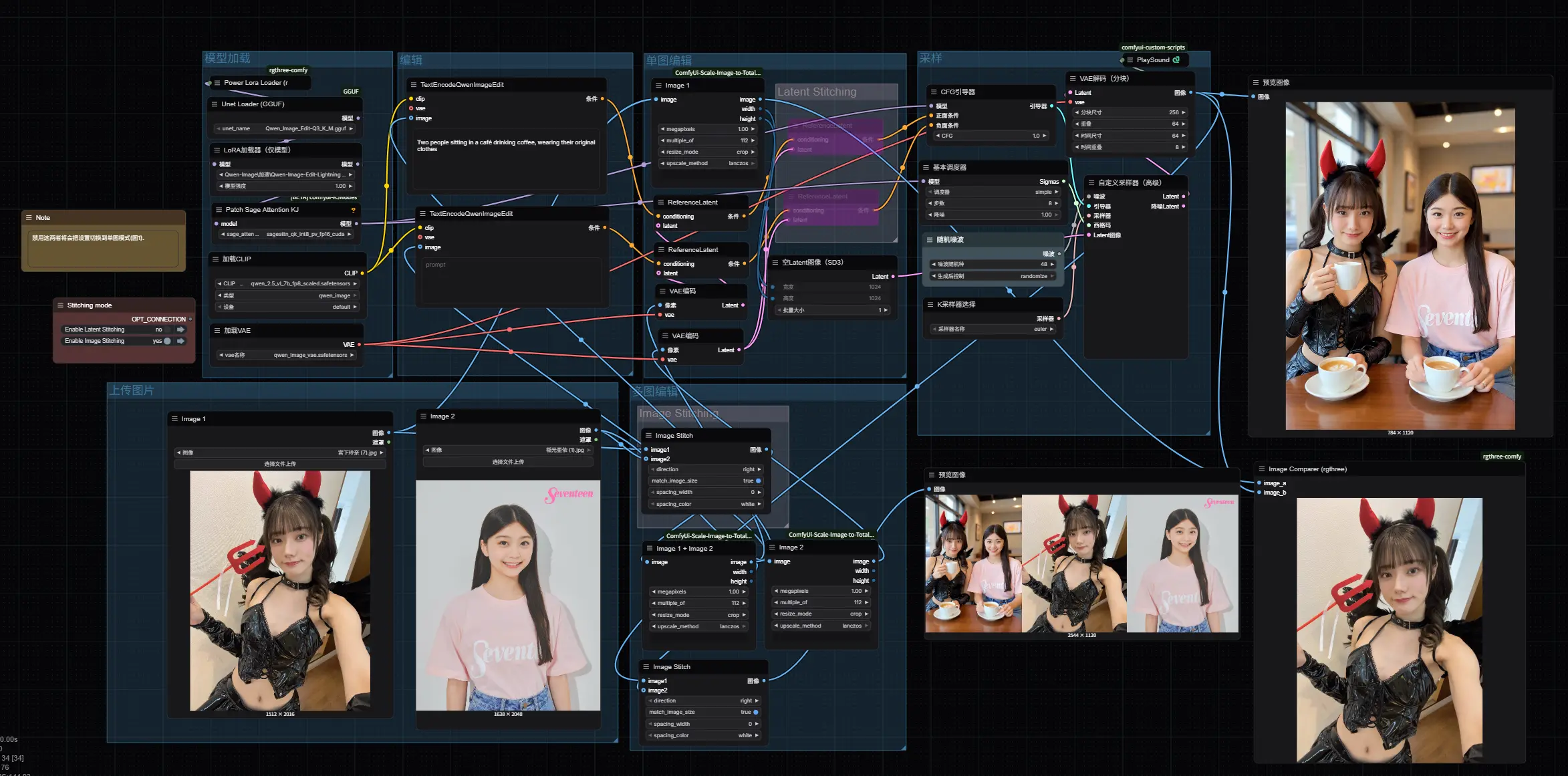
多图编辑
✅ 3. 关注后续版本优化建议
目前 TextEncodeQwenImageEdit 的一体化设计虽然方便,但也带来了灵活性不足的问题。社区建议:
- 将图像编码与文本编码功能解耦;
- 提供可配置的预处理选项(如固定尺寸、禁用自动缩放);
- 支持更细粒度的 patch 对齐控制
延伸思考
Qwen-Image-Edit 的这一现象揭示了一个普遍问题:多模态模型中不同子系统(VAE、视觉编码器、语言模型)的预处理不一致,可能成为生成质量的瓶颈。未来更理想的架构应支持:
- 统一的图像网格对齐策略;
- 可插拔的编码流程;
- 更透明的内部处理日志输出。
这对开发者和平台设计者都提出了更高要求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











