
在Black Forest Labs发布了FLUX.1 Tools系列开源模型以后,ComfyUI也在第一时间宣布支持这些模型,并且v0.3.0版本也正式释出。ComfyUI现在支持来自Black Forest Labs为Flux.1设计的3系列新模型:Redux适配器、Fill模型、ControlNet模型和LoRA(深度和Canny)。

这些新增功能为用户提供了在图像生成中轻松精确控制细节和风格的能力。
FLUX.1 Fill [dev]:需要输入图像、输入蒙版(与输入图像相同大小的黑白图像)和提示词 FLUX.1 Redux [dev]:一个小型适配器,可用于dev和schnell版本来生成图像变体。输入为图像(无需提示词),模型将生成与输入图像相似的图像 Controlnet模型:需要输入图像和提示词 FLUX.1 Depth [dev]:使用深度图作为实际条件控制 FLUX.1 Depth [dev] LoRA:可与FLUX.1 [dev]一起使用的LoRA FLUX.1 Canny [dev]:使用Canny边缘图作为实际条件控制 FLUX.1 Canny [dev] LoRA:可与FLUX.1 [dev]一起使用的LoRA
请查看以下内容,详细了解每个模型、其功能以及如何开始使用。
1.Fill
Fill模型设计用于通过蒙版和提示词进行内填充和外填充。
功能: 内填充:填充图像中缺失或移除的区域 外填充:无缝扩展图像
输入:输入图像、输入蒙版(与输入图像相同大小的黑白图像)和提示词 增强的CLI功能:对于内填充任务,CLI根据输入图像和蒙版的尺寸自动推断生成图像的大小
开始使用:
- 将ComfyUI更新至最新版本
- 下载clip_l和t5xxl_fp16模型到models/clip文件夹
- 下载flux1-fill-dev.safetensors到ComfyUI/models/unet文件夹
使用示例页面上的flux_inpainting_example或flux_outpainting_example工作流程。
PS:
- GGUF版本:https://huggingface.co/YarvixPA/FLUX.1-Fill-dev-gguf
- FP8版:https://civitai.com/models/969431/flux-fill-fp8

2.Redux
Redux模型是一个轻量级模型,可与Flux.1[Dev]和Flux.1[Schnell]配合使用,基于1张输入图像生成图像变体——无需提示词。它非常适合快速生成特定风格的图像。
- 输入:向Remix适配器提供现有图像
- 输出:一组保持输入图像风格、色彩搭配和构图的变体
开始使用:
- 将ComfyUI更新至最新版本下载sigclip_patch14-384.safetensors到ComfyUI/models/clip_vision
- 确保flux1-dev模型在ComfyUI/models/unet文件夹中
- 下载Redux模型到comfyui/models/style_models
- 从我们的示例页面下载如下图所示的remix工作流程
重混1张图像

重混多张图像

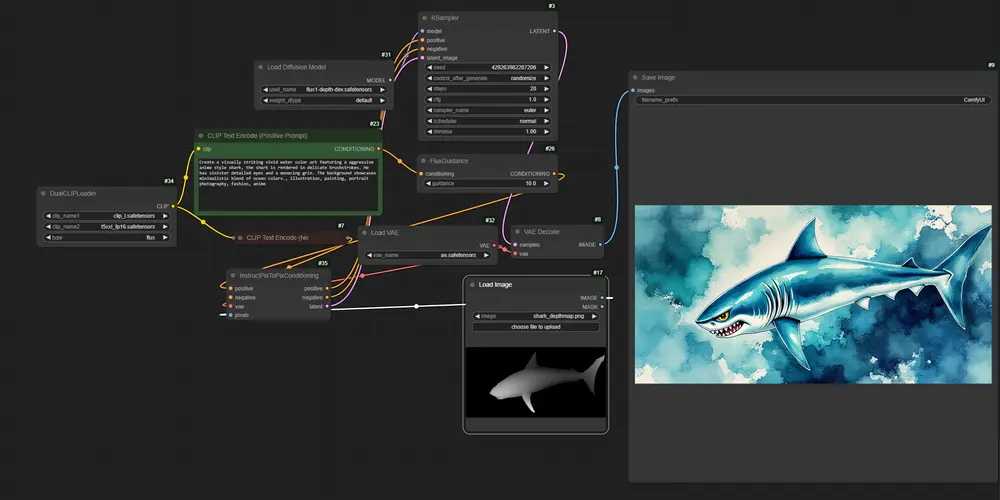
3.ControlNets
ControlNet模型通过添加特定的地图条件控制来增强生成工作流程,提供对结构和设计的无与伦比的控制。
类型: 深度模型:利用深度图来指导透视和结构 Canny模型:使用Canny边缘图进行基于轮廓的条件控制
所需输入:图像、文本提示词以及深度图或Canny边缘图 输出:紧密遵循提供的结构并符合提示词的生成图像
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











