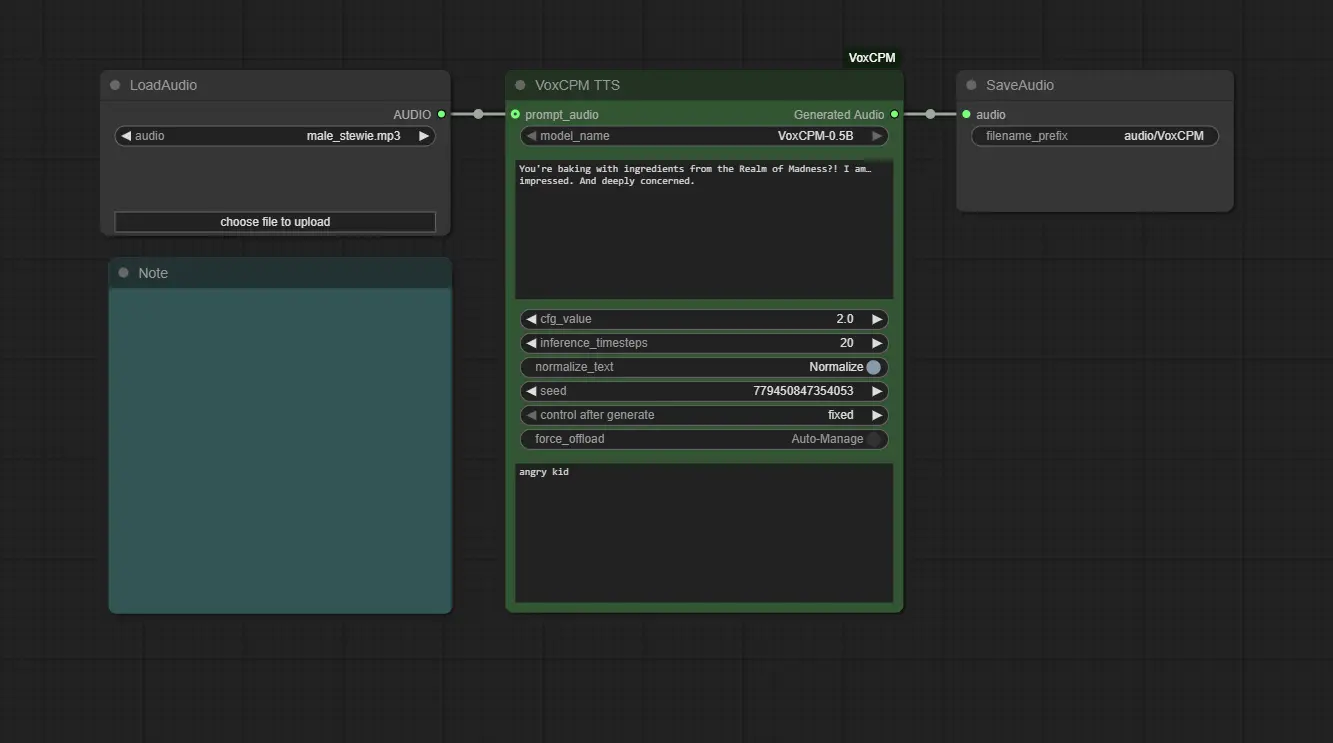
ComfyUI-VoxCPM 是一个为 ComfyUI 设计的自定义节点,集成了 VoxCPM —— 一种基于 MiniCPM-4 架构的新型无分词器(tokenizer-free)文本到语音(TTS)系统,支持高表现力语音生成与零样本语音克隆。
该节点实现了从模型管理、音频输入处理到语音合成的全流程自动化,让用户可通过图形化工作流,直接从文本和参考音频生成自然、富有情感的语音内容。
核心特性
| 特性 | 说明 |
|---|---|
| ✅ 上下文感知语音生成 | 理解语义上下文,自动调整语调、节奏与情感表达 |
| ✅ 零样本语音克隆 | 仅需一段短音频即可复现音色、口音与说话风格 |
| ✅ 无需训练 | 支持即时克隆,不依赖微调或长时间适配 |
| ✅ 自动模型管理 | 模型按需下载,路径统一管理,支持 VRAM 卸载 |
| ✅ 细粒度控制 | 可调节 CFG 缩放、推理步数等参数优化输出质量 |
| ✅ 高效合成 | 在消费级 GPU 上也可实现快速语音生成 |
🔧 基于 MiniCPM-4 骨干网络,VoxCPM 在连续语音空间中建模发音过程,跳过传统音素切分,显著提升自然度与跨语言泛化能力。
⚙️ 安装指南
方法一:通过 ComfyUI Manager 安装(推荐)
- 打开 ComfyUI Manager
- 搜索
ComfyUI-VoxCPM - 点击“安装”
方法二:手动安装
cd ComfyUI/custom_nodes/
git clone https://github.com/wildminder/ComfyUI-VoxCPM.git
cd ComfyUI-VoxCPM
pip install -r requirements.txt
重启 ComfyUI 后,VoxCPM TTS 节点将出现在 audio/tts 类别下。
首次使用时,节点会自动下载所需模型至:
ComfyUI/models/tts/VoxCPM/
使用方法
1. 添加节点
将 VoxCPM TTS 节点拖入工作区。
若需语音克隆,请同时添加 Load Audio 节点加载参考音频。
2. 连接音频输入(可选)
将 Load Audio 的 AUDIO 输出连接至 VoxCPM TTS 的 prompt_audio 输入端口。
3. 输入文本
- text:要合成的目标文本(必填)
- prompt_text(语音克隆专用):提供
prompt_audio的精确转录本(必须匹配)
📌 示例:
prompt_text: "你好,今天天气不错"
text: "欢迎收听本期播客"
4. 设置参数并生成
配置以下关键参数后提交队列:
| 参数 | 推荐值 | 说明 |
|---|---|---|
cfg_value | 1.8 – 2.2 | 控制对提示音频或文本意图的遵循程度 |
inference_timesteps | 15 – 25 | 步数越多,细节越丰富,速度越慢 |
normalize_text | 开启(默认) | 自动处理数字、缩写、标点;如需音素控制则关闭 |
seed | -1(随机)或固定值 | 用于结果复现 |
force_offload | True/False | 生成后是否强制卸载模型以释放显存 |
📦 节点输入说明
| 输入项 | 类型 | 是否必需 | 描述 |
|---|---|---|---|
model_name | string | 是 | 选择模型版本,支持自动下载 |
text | string | 是 | 目标合成文本 |
prompt_audio | audio | 否 | 参考语音文件(wav/mp3) |
prompt_text | string | 克隆时必需 | 与 prompt_audio 完全对应的文本 |
cfg_value | float | 否 | 默认 2.0 |
inference_timesteps | int | 否 | 默认 20 |
normalize_text | bool | 否 | 默认开启 |
seed | int | 否 | 默认 -1(随机) |
force_offload | bool | 否 | 默认 False |
🍳 “语音厨师”操作指南
想做出更地道的声音?试试这三个步骤:
🥚 第一步:准备基础成分(内容输入方式)
方式 A:常规文本(推荐日常使用)
- ✅ 保持
normalize_text = True - 输入自然语言文本,如
"Hello world! 今年GDP增长了6.2%" - 系统自动处理数字读法、英文发音等
方式 B:音素输入(高级控制)
- ❌ 关闭
normalize_text - 使用
{}包裹音素标记,例如:- 英文:
{HH AH0 L OW1} {W ER1 L D} - 中文:
{ni3}{hao3}{ma1}
- 英文:
- 适用于精确控制多音字、连读、重音等场景
🍳 第二步:选择风味轮廓(语音风格)
选项 A:使用参考音频(语音克隆)
- 提供一段 3–10 秒干净录音作为
prompt_audio - 模型将复制其音色、语速、情绪甚至背景氛围
- 需同步提供准确的
prompt_text转录
💡 小贴士:避免背景噪音、断句不清或多人对话片段
选项 B:零样本生成(无提示)
- 不连接
prompt_audio - 模型根据
text内容自主决定合适语气(如新闻播报、童声讲述等) - 利用 MiniCPM-4 的强语义理解能力进行风格推断
🧂 第三步:最终调味(参数微调)
| 参数 | 调整建议 |
|---|---|
cfg_value | • 过高(>2.5):声音僵硬、机械感增强 • 过低(<1.5):偏离提示风格,可能模糊不清 • 推荐范围:1.8–2.2 |
inference_timesteps | • 5–10 步:快速预览,适合草稿阶段 • 15–20 步:平衡质量与效率 • 20+ 步:追求极致自然度,适合成品输出 |
⚠️ 注意事项与限制
🚫 模块化设计原则
原始 VoxCPM 库包含内置去噪模块(ZipEnhancer),但本节点已主动移除该功能。我们遵循 ComfyUI 的模块化哲学:每个节点专注单一任务。
👉 如需降噪,请在前置流程中使用专用音频处理节点(如 RNNoise、Demucs)清理 prompt_audio。
⚠️ 技术限制
| 限制项 | 说明 |
|---|---|
| 训练语言 | 主要在中英文上训练,其他语言效果不保证 |
| 输入长度 | 过长文本可能导致生成不稳定,建议单次不超过 100 字 |
| 克隆精度 | 对低质量、带混响或多人语音的克隆效果有限 |
更新(12月12日)
开发者推送了一项新更新,其中包含对 VoxCPM 1.5 和 0.5B 模型的同时支持。此外,引入了两个 TTS 节点以适应不同的工作流:
基础 TTS 节点
- 零门槛的文本转语音。
- 只需输入文本 → 立即生成。
- 专为希望快速获得结果或进行最少配置的用户设计。
高级 TTS 节点
- 为希望完全掌控的用户提供:
- 声音克隆、推理设置、长度调节、设备选择、淡入效果等等。
- 非常适合资深用户、工作流构建者和 TTS 完美主义者。
更新亮点
- 全面支持 VoxCPM 1.5(5 天前发布)
- 旧版 0.5B 模型仍获支持
- 更佳清晰度,更少伪影
- 改进的克隆一致性
- 更快更稳定的 TTS
- 自动模型下载
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











