2025 年 12 月 5 日,面壁智能正式发布 VoxCPM1.5 模型权重。作为 VoxCPM 系列的重大升级版本,它在保留上下文感知语音生成与零样本声音克隆能力的基础上,通过两项关键技术改进,显著提升了音频质量、推理效率与可定制性。
- GitHub:https://github.com/OpenBMB/VoxCPM
- 模型:https://huggingface.co/openbmb/VoxCPM1.5
- ComfyUI插件:https://huggingface.co/openbmb/VoxCPM1.5
核心升级:更高保真,更低开销
🔊 AudioVAE 采样率:16kHz → 44.1kHz
- 支持生成 CD 级音频质量(44.1kHz),保留更多高频细节;
- 在使用高质量参考音频时,声音克隆更自然、语音合成更清晰;
- 注意:输出质量仍依赖提示语音质量——低质输入无法通过模型“修复”。
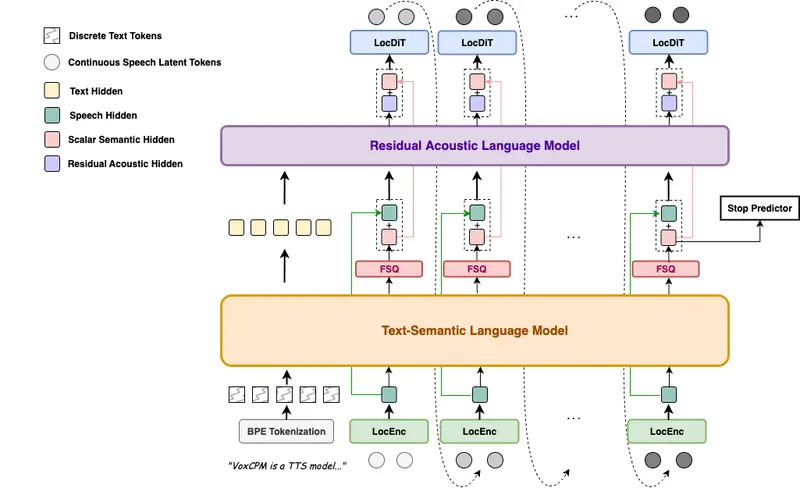
⚡ 标记率:12.5Hz → 6.25Hz
- 通过将 LocEnc 与 LocDiT 模块的补丁大小从 2 扩展至 4,语言模型处理频率减半;
- 实际收益:
- 生成 1 秒音频仅需 6.25 个标记(原为 12.5);
- 计算量显著降低,为长语音生成和更大模型训练奠定基础;
- 实时因子(RTF)保持稳定或略有改善,尽管参数量因网络深度增加而小幅上升。
模型总参数量略有增加,但因标记数减半,整体推理效率更高。
全面支持微调:全参数 + LoRA
VoxCPM1.5 同时开放全参数微调(SFT),赋能用户:
- 基于自有语音数据训练个性化声音模型;
- 在垂直领域(如客服、播客、有声书)构建专属语音合成系统;
- 通过 LoRA 实现低成本、低显存的快速适配。
微调指南已随模型发布,包含完整训练脚本与示例。
稳定性改进与现存挑战
针对社区反馈的稳定性问题,VoxCPM1.5 已优化:
✅ 已修复:
- 音频开头/结尾的噪音伪影(通过推理逻辑与数据优化);
- 长语音生成中的部分不连贯问题(得益于 6.25Hz 标记率)。
⚠️ 仍在优化:
- 极短文本(如 "hello")的合成稳定性;
- 复杂情感语音在自回归生成中的错误累积(尤其长语音);
- 音量波动、语速突变等细节控制。
面壁智能表示将持续分析长语音生成机制,并在后续版本中系统性优化。
未来路线图(2026 Q1 起)
- 🌍 多语言 TTS:扩展至中英文以外的语言(欢迎社区提需求);
- 🎯 指令可控语音生成:通过自然语言控制情感、音色、韵律等属性;
- 🎵 通用音频基座:探索统一生成语音、音乐、音效的通用模型(长期愿景)。
下一版本计划于 2026 年第一季度发布,将包含重大功能更新。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











