在图像领域,Meta 的 Segment Anything Model (SAM) 通过“任意分割”能力,彻底改变了计算机视觉的交互范式。如今,这一理念正式延伸至音频领域。
Meta 正式发布 SAM Audio——首个支持多模态提示的统一音频分离模型。它允许用户通过文本描述、视频点击或时间片段标记,从复杂音频混合物中精准分离出目标声音。无论是“提取吉他声”、“去掉狗叫”还是“只保留说话人语音”,SAM Audio 都能以接近专业工具的精度完成,且无需复杂操作。
- 项目主页:https://ai.meta.com/samaudio
- GitHub:https://github.com/facebookresearch/sam-audio
- 模型:https://huggingface.co/collections/facebook/sam-audio
更重要的是,SAM Audio 并非单一功能模型,而是整套音频AI基础设施的一部分,包含技术引擎、评估基准与自动化评判系统,全部开源。
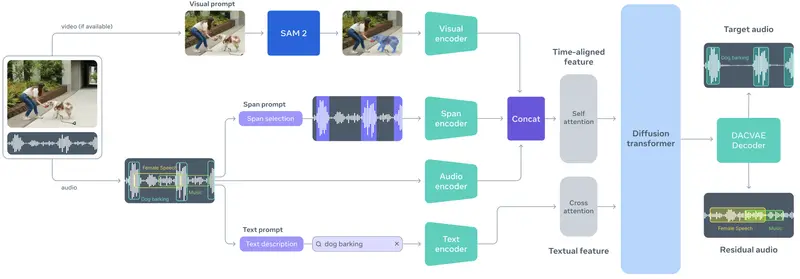
三大交互方式,还原人类听音直觉
传统音频分离工具通常针对特定任务(如人声提取、降噪)设计,功能割裂、操作复杂。SAM Audio 首次将人类与声音交互的自然方式引入模型设计:
- 文本提示:输入“交通噪音”或“女声独唱”,模型自动分离对应声源;
- 视觉提示:在视频中点击某个说话人、乐器或物体,系统同步分离其发声;
- 跨度提示(Span Prompting):标记一段包含目标声音的时间区间(如“00:12–00:15 的狗叫”),模型将自动在整个音频中识别并移除该类声音。
✅ 组合使用更强大:例如,先用视觉提示定位视频中的小提琴手,再用文本提示“只保留小提琴”,可提升分离准确性。
这种多模态提示机制,使得 SAM Audio 能覆盖语音、音乐、环境音效三大主流音频场景,且在各项任务中均达到或超越此前最优的领域专用模型。
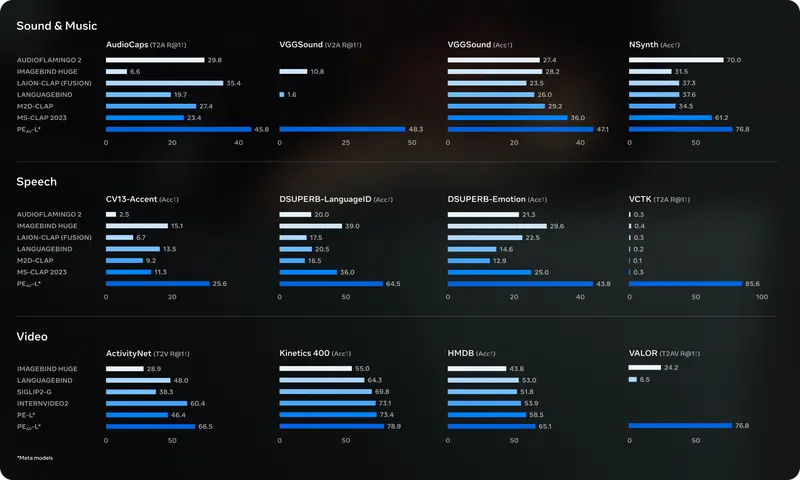
技术核心:PE-AV —— 音频分离的“感知引擎”
SAM Audio 的高性能背后,是 Perception Encoder Audiovisual (PE-AV) 的支撑。它是 Meta 今年早些时候发布的 Perception Encoder 模型的音视频扩展版本,可视为 SAM Audio 的“感知大脑”。
PE-AV 的关键能力在于:
- 跨模态对齐:将视频帧与音频在精确时间戳上对齐,建立“所见即所听”的语义关联;
- 语义特征提取:利用对比学习,在超1亿视频上训练,提取鲁棒的视听联合表示;
- 上下文推理:不仅能分离画面中的声源(如屏幕上的歌手),还能推断画面外的声音事件(如画外婴儿啼哭)。
技术栈整合了 PyTorchVideo(视频处理)、FAISS(语义搜索)与多模态对比学习框架,形成一个可扩展、高泛化的骨干网络,为多模态音频任务提供统一编码基础。
配套工具链:不止于模型
Meta 同步发布了三项关键配套资源,旨在推动音频分离领域的标准化与可复现性:
1. SAM Audio-Bench:首个真实世界音频分离基准
- 覆盖语音、音乐、通用音效三大领域;
- 每个10秒样本均配有人工标注的视觉掩码、时间标记、文本描述;
- 支持无参考评估(无需干净干声),更贴近实际应用场景;
- 数据来自高质量真实视频与合成混合,避免早期基准过度依赖人工合成音频的局限。
2. SAM Audio Judge:首个音频分离自动评判模型
- 基于9个感知维度(如保真度、精确度、整体质量)训练;
- 使用人类评分数据优化,输出更贴近真实听感的客观指标;
- 特别适用于无参考场景(如用户上传的混音视频),传统指标(如SI-SDR)在此类场景失效。
3. Segment Anything Playground
- 在线平台,用户可上传音视频或从素材库选择,实时体验 SAM Audio 的分离效果;
- 同时支持 SAM 3(图像)、SAM 3D(3D场景)与 SAM Audio 的交互演示。
性能与局限
✅ 优势
- SOTA性能:在语音、音乐、通用声音三大类任务上,全面超越此前模型;
- 实时效率:处理速度达 RTF ≈ 0.7(即1秒音频处理耗时0.7秒),支持5亿至30亿参数规模部署;
- 统一架构:一个模型处理多类任务,避免为每个场景训练独立模型。
⚠️ 局限
- 不支持音频作为提示(例如上传一段参考声音来分离同类声源);
- 无法执行无提示的全分离(即“把所有声音都分开”);
- 对高度相似声源分离仍有挑战:如从合唱中分离单一声部,或从交响乐中提取单一乐器。
应用前景:从创作到无障碍
Meta 已与多家机构合作探索 SAM Audio 的实际价值:
- Starkey(美国最大助听器厂商):研究如何利用模型实时分离语音与背景噪音,提升听障用户体验;
- 2gether-International(残障创业者加速器):探索音频AI在无障碍交互中的创新应用。
对普通用户和开发者而言,SAM Audio 意味着:
- 视频创作者可一键去除环境噪音;
- 播客主可自动清理录音中的突发干扰;
- 研究者可基于统一框架开发新音频Agent;
- 开源社区可构建下一代音频编辑插件或智能助手。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...