你有没有想过,输入一段歌词,再标上每个词该在什么时候唱,就能自动生成一首旋律自然、节奏准确、风格统一的完整歌曲?
这不是未来设想,而是已经实现的技术突破。
新加坡科技设计大学(SUTD)与 Lambda 实验室联合推出了一款名为 JAM 的新型歌词到歌曲生成模型。它不仅能将文本转化为包含人声和伴奏的完整音乐作品,更重要的是——实现了对歌词发音时间的精细控制,甚至可以精确到音素级别。
- 项目主页:https://declare-lab.github.io/jamify
- GitHub:https://github.com/declare-lab/jamify
- 模型:https://huggingface.co/declare-lab/JAM-0.5
这意味着:作曲人可以像编排MIDI一样,控制每一个字的起止时刻,让AI生成的歌声真正“踩点”。

为什么 JAM 值得关注?
当前大多数歌词到歌曲(Lyrics-to-Song)生成模型存在一个明显短板:缺乏对时间结构的细粒度掌控。
多数系统只能接收纯文本歌词,然后“自由发挥”地配上旋律和节奏。这种做法虽然能生成听起来像歌的东西,但在实际创作中很难使用——因为你无法决定哪句歌词该长、哪句该短,也无法保证歌词与节拍精准对齐。
而 JAM 的出现,正是为了解决这个问题。
它允许用户输入:
- 歌词文本
- 每个单词的开始和结束时间
- 目标歌曲总时长
- 风格提示(文本描述或参考音频)
然后输出一段结构完整、节奏准确、风格一致的歌曲,从旋律到人声演绎都接近人类专业创作水平。
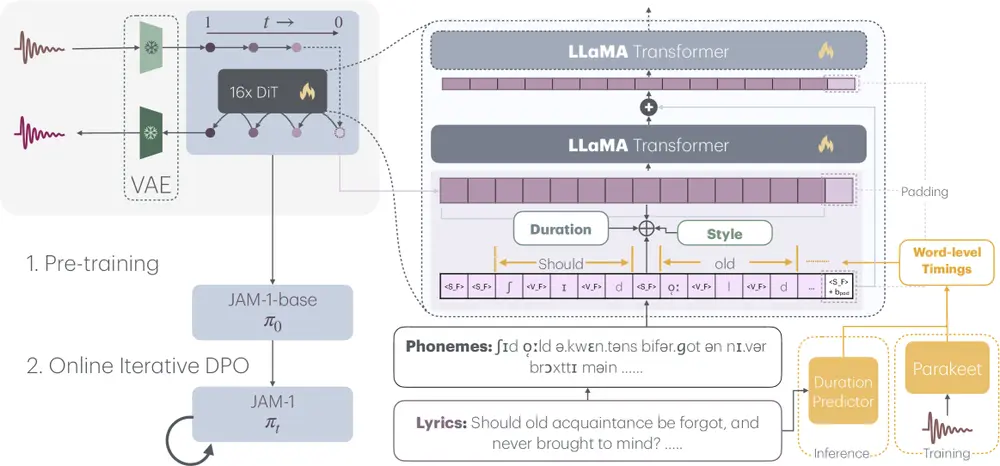
核心功能一览
✅ 单词与音素级时间控制
这是 JAM 最核心的创新。
用户可以明确指定每个词甚至每个音节的发声区间,模型会据此生成严格对齐的歌声。例如,“我爱你”三个字分别占0.3秒、0.2秒、0.4秒,JAM 就会按照这个节奏来安排发音。
这项能力极大提升了模型在真实音乐制作流程中的可用性,尤其适合需要精确同步歌词与画面的场景,比如影视配乐、广告音乐等。
✅ 全局时长控制,最长支持近4分钟
不同于只能生成短片段的模型,JAM 支持生成最长 3分50秒 的完整歌曲。无论是副歌重复结构,还是主歌-桥段-副歌的经典编排,都能自然呈现。
✅ 高保真歌词还原
通过引入音素边界注意力机制,JAM 显著降低了歌词错读率:
- 单词错误率(WER):0.151
- 音素错误率(PER):0.101
相较前代模型 DiffRhythm(WER 0.3481,PER 0.2643),错误率下降超过三倍,意味着“唱错词”的情况大幅减少。
✅ 审美对齐:让AI懂得“好听”
生成技术不仅要“准确”,还要“好听”。
JAM 采用 直接偏好优化(DPO) 方法,在无需人工标注的前提下,利用自动化评估工具 SongEval 构建合成偏好数据集,持续迭代优化生成结果。
最终生成的歌曲在旋律流畅度、节奏感、人声自然度等方面更贴近人类审美,在多项主观评价中表现优于同类模型。
✅ 多风格适配
只需提供风格提示(如“流行摇滚,带电子鼓点”或上传一段参考音频),JAM 即可生成风格一致的作品。测试显示其风格分类准确率达 70.4%,MuQ-MuLan 相似度评分达 0.759,具备较强的风格建模能力。
技术亮点:轻量高效,易于部署
| 项目 | JAM |
|---|---|
| 参数量 | 5.3亿(530M) |
| 模型层数 | 16层 LLaMA 风格 Transformer |
| 架构类型 | 基于流匹配(Flow Matching)的 DiT 结构 |
| 编码方式 | VAE 编码音频为潜在表示 |
| 训练策略 | 两阶段训练 + DPO 偏好对齐 |
尽管参数量仅为 DiffRhythm(11亿)的一半左右,JAM 在多项指标上反而表现更优。小模型带来的优势是:
- 推理速度更快
- 显存需求更低(建议8GB以上GPU即可运行)
- 更适合集成进本地创作工具或轻量级应用
它是怎么工作的?
JAM 的工作流程分为三个关键环节:
1. 输入条件解析
系统接收以下输入:
- 歌词文本 + 时间标记:定义每个词的起止时间
- 目标时长:控制整首歌长度
- 风格引导:可通过文本描述或参考音频指定风格
2. 潜在空间生成
音频先由 VAE 编码为低维潜在表示,模型在此空间内通过流匹配技术逐步去噪,生成符合条件的人声与伴奏联合表示。
3. 偏好对齐优化
在预训练和微调之后,使用 DPO 技术进行审美调优。整个过程依赖自动化评估反馈,避免了昂贵的人工打分标注。
实测表现如何?
客观指标全面领先
| 指标 | JAM 表现 | 对比模型(DiffRhythm) |
|---|---|---|
| WER(单词错误率) | 0.151 | 0.3481 |
| PER(音素错误率) | 0.101 | 0.2643 |
| MuQ-MuLan 相似度 | 0.759 | — |
| 风格分类准确率 | 70.4% | — |
| 内容享受(CE) | 7.423 | — |
| 整体连贯性(CO) | 8.0639 | — |
在 Audiobox-aesthetic 和 SongEval 等权威评估框架下,JAM 在内容质量、旋律表达、结构清晰度等多个维度均取得最高分。
主观听感接近专业水准
人类评委在盲测中普遍认为:
- JAM 生成的歌曲更具节奏控制力
- 歌词清晰、发音自然
- 音乐性和享受度优于多数基线模型
- 与当前最先进模型在音质上基本持平
开源与数据集贡献
除了模型本身,研究团队还发布了 JAME 数据集——一个专用于歌词到歌曲任务的公开评估集,涵盖多种音乐风格(流行、R&B、嘻哈等),每首歌均配有精确的时间标注和风格标签。
这一举措有助于推动该领域标准化评测的发展,也为后续研究提供了高质量基准。
使用要求
如需本地部署或实验,需满足以下条件:
- Python 3.10 或更高版本
- 支持 CUDA 的 GPU,建议显存 ≥ 8GB
项目代码与模型已公开,开发者可基于其构建定制化音乐生成工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...