Boson AI 正式推出 Higgs Audio Generation 版本2(Higgs Audio V2),这是Boson AI在音频生成领域的一次重要突破。该模型具备强大的多说话者对话生成能力,现已全面开源。
- GitHub:https://github.com/boson-ai/higgs-audio
- 模型:https://huggingface.co/bosonai/higgs-audio-v2-generation-3B-base
- Demo:https://boson.ai/demo/tts
与当前大多数依赖微调或后训练的语音系统不同,Higgs Audio V2 是一个纯预训练模型,未经任何任务特定优化,却在表达性语音生成上展现出卓越表现。这意味着它不仅能准确发音,更能理解语义、情感和语境,在无需额外干预的情况下生成自然、生动的语音内容。
更重要的是—— 它已开源。
开发者、研究者和创作者现在可以自由使用这一模型,构建属于自己的语音应用:从有声书、播客,到虚拟角色对话系统,皆可实现。
为什么 Higgs Audio V2 值得关注?
语音合成(TTS)技术早已超越“把文字读出来”的阶段。真正有价值的系统,应当能传达情绪、区分角色、适应语境,甚至在没有明确指令时做出合理判断。
Higgs Audio V2 正是朝着这个方向迈出的关键一步。
核心亮点一览
| 能力 | 说明 |
|---|---|
| ✅ 多说话者对话生成 | 支持自然的双人及以上对话,自动区分角色语气与情感 |
| ✅ 零样本跨语言生成 | 无需训练即可生成多种语言的连贯语音 |
| ✅ 高保真输出 | 音频采样率提升至 24kHz,细节更丰富 |
| ✅ 长文本稳定生成 | 保持声音一致性,适用于文章朗读、故事讲述等场景 |
| ✅ 声音克隆与哼唱还原 | 可复现特定人声,并支持旋律哼唱的语音重建 |
| ✅ 开源免费 | 模型、Tokenizer、训练数据处理流程全部开放 |
性能表现:在多个基准测试中领先
Boson AI重点关注语音的自然度、类人性和情感表达能力。为此,Higgs Audio V2 在多个权威基准上进行了评估。
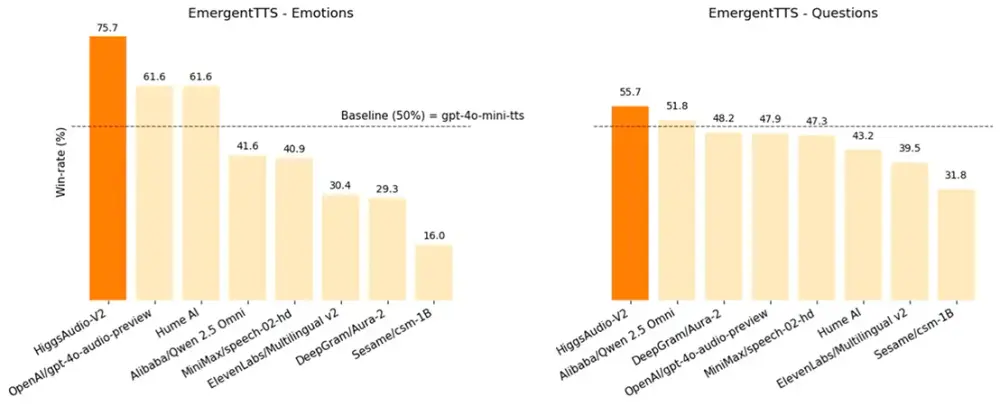
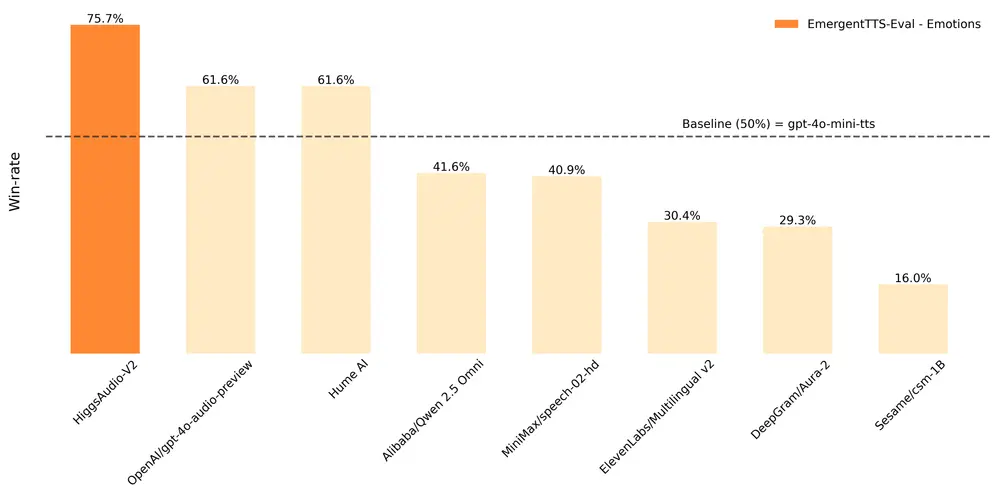
1. EmergentTTS-Eval:情感与提问场景对比
该基准通过人类盲测比较不同模型在“情感表达”和“提问语气”上的表现。Higgs Audio V2 在“情感”类别中以 75.7% 的胜率 超过 gpt-4o-mini-tts(基准为 50%),显著优于其他主流模型。
| 模型 | 情感 (%) ↑ | 提问 (%) ↑ |
|---|---|---|
| Higgs Audio V2 (base) | 75.71% | 55.71% |
| gpt-4o-audio-preview† | 61.64% | 47.85% |
| Hume.AI | 61.60% | 43.21% |
| BASELINE: gpt-4o-mini-tts | 50.00% | 50.00% |
| ElevenLabs Multilingual v2 | 30.35% | 39.46% |
注:测试中使用“belinda”声音克隆,未做额外调优。
2. Seed-TTS Eval 与 情感语音数据集(ESD)
在传统 TTS 指标中,Higgs Audio V2 同样表现出色,尤其在语义相似度(SIM)方面领先。
| 模型 | Seed-TTS Eval | ESD | ||
|---|---|---|---|---|
| WER ↓ | SIM ↑ | WER ↓ | SIM (emo2vec) ↑ | |
| HiggsAudio V1 | 2.18 | 66.27 | 1.49 | 82.84 |
| HiggsAudio V2 (base) | 2.44 | 67.70 | 1.78 | 86.13 |
尽管词错误率略有上升(因生成更具表现力的语音),但语义保真度显著提高。
3. 多说话者对话评估:首次实现高质量零样本角色分配
Boson AI构建了一个专门用于评估多说话者生成能力的测试集,包含三个子任务:
- 双人对话:两个角色交替发言,需匹配参考声音
- 简短对话:短轮次交互,测试声音一致性
- 无参考对话:模型需自主分配不同声音给不同说话者
结果如下:
| 模型 | 双人对话 | 简短对话 | 无参考对话 | |||
|---|---|---|---|---|---|---|
| WER ↓ | Sim&Dis-sim ↑ | WER ↓ | Sim&Dis-sim ↑ | WER ↓ | Sim&Dis-sim ↑ | |
| MoonCast | 38.77 | 41.00 | 8.33 | 46.02 | 24.65 | 41.00 |
| nari-labs/dia | - | - | 17.62 | 63.15 | 19.46 | 61.14 |
| Higgs Audio V2 | 18.88 | 51.95 | 11.89 | 67.92 | 14.65 | 55.28 |
Higgs Audio V2 在所有指标上均优于现有开源方案,尤其是在角色区分度(Sim&Dis-sim)方面表现突出。
技术架构:三大核心创新
Higgs Audio V2 的强大性能源于其独特的设计思路。以下是关键技术突破:
1. 超大规模训练数据:AudioVerse
模型基于超过 1000万小时 的音频数据进行预训练,这些数据来自公开语料库,并通过自动化管道进行清洗与标注。
Boson AI构建了 AudioVerse——一个高质量、多语言、多场景的音频语料库,结合多个 ASR 模型、声音事件分类器和内部音频理解模型,实现自动注释,大幅提升了数据利用效率。
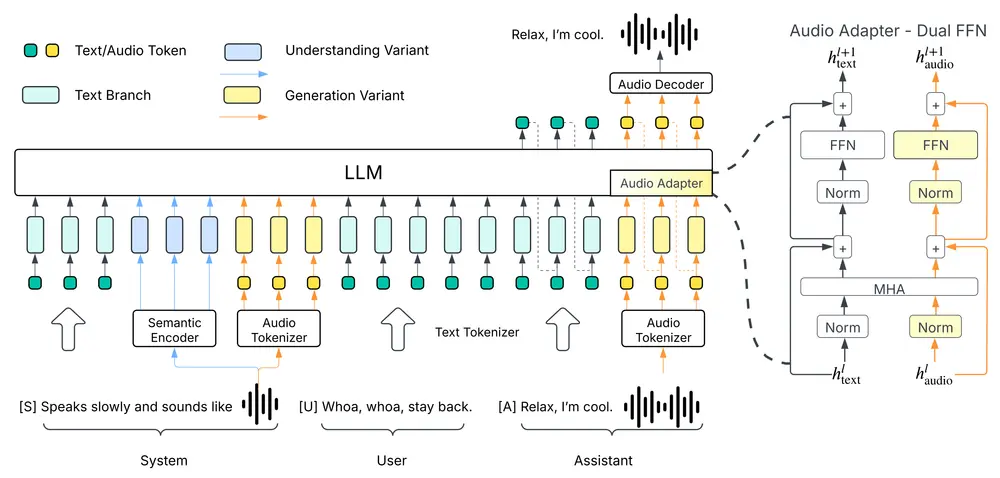
2. 统一音频 Tokenizer
传统方法常将音频压缩为高密度 token 序列,导致模型负担过重。Higgs Audio V2 采用语义-声学双通道 tokenizer,分别提取语言含义和声音特征,在保持 25Hz 的低 token 率的同时,保留丰富的声学细节。
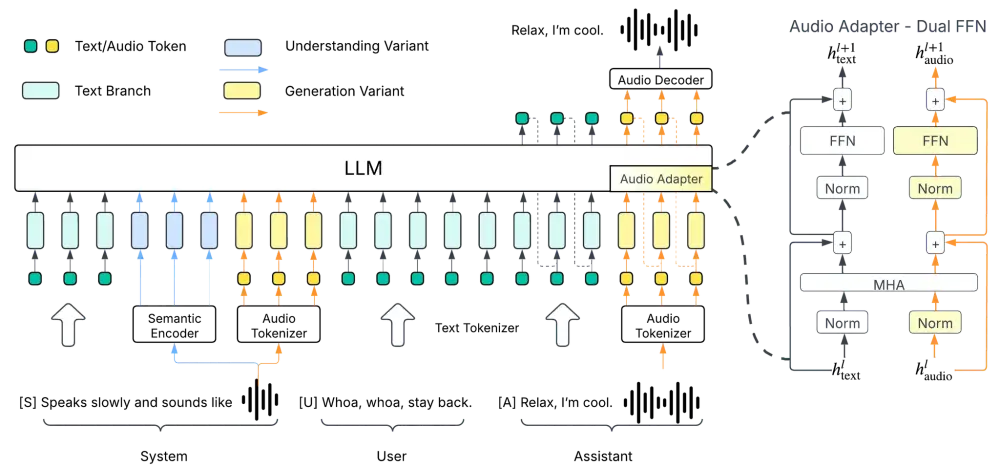
3. 双 FFN 架构 + 跨注意力机制
模型在 LLM 主干基础上引入双前馈网络(Dual FFN)结构,分别处理文本 token 和音频 token,并通过跨注意力模块共享信息。这种设计让模型能更高效地建模文本与声音之间的复杂关系。
实际能力展示
Higgs Audio V2 不只是一个“会说话”的模型,它具备一些此前罕见的能力:
- 自动韵律适应:在叙述长段落时,自动调整语调起伏,避免机械重复
- 多语言零样本生成:输入中文提示,可生成自然的英文对话,无需翻译中间步骤
- 声音克隆+哼唱还原:提供一段人声哼唱录音,模型可复现相同旋律与音色
- 语音与背景音乐同步生成:支持生成带配乐的语音内容,节奏自然对齐
这些能力使得它在内容创作、教育、游戏、客服等领域具有广泛潜力。
推理效率:兼顾性能与可用性
Boson AI深知,模型不仅要强,还要能跑得动。
- 最小版本可在 Jetson Orin Nano 上运行,适合边缘设备部署
- 主力 3B 参数模型建议使用 RTX 4090 或同等算力 GPU 以实现高效推理
- 支持 Hugging Face Transformers 接口,易于集成进现有流程
开源承诺:让每个人都能参与语音创新
Boson AI坚信,开放是推动技术进步的最佳方式。
因此,Higgs Audio V2 的以下部分已全部开源:
- 预训练模型权重
- 音频 tokenizer
- 数据处理脚本
- 推理示例代码
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











