在自动语音识别(ASR)领域,Whisper 一直是开源社区的标杆——强大、鲁棒、支持零样本迁移。但它有一个根本局限:训练数据未公开,模型行为难以分析,也无法完全复现。
现在,艾伦人工智能研究所(AI2)推出了一个全新的开源 ASR 模型家族:OLMoASR。它不仅性能对标 Whisper,更重要的是——从数据到代码,每一层都彻底开放。
这不是另一个“开源权重”的项目,而是一次对 ASR 研究基础设施的重新定义。

什么是 OLMoASR?
OLMoASR 是由 AI2 开发的一系列端到端英文语音识别模型,全部从零开始训练,目标是实现与 Whisper 相当甚至更优的零样本(zero-shot)表现,同时确保完全可复现、可审计、可改进。
其核心理念是:
开放,不应止于模型权重。
因此,OLMoASR 公开了整个技术栈:
- ✅ 模型权重
- ✅ 训练代码与超参配置
- ✅ 评估脚本与测试集处理流程
- ✅ 最关键的:训练数据集本身
这在当前主流 ASR 项目中极为罕见。
模型家族:覆盖多尺度需求
AI2 发布了六个初始模型,参数规模从 3900 万到 15 亿不等,满足不同场景需求:
| 模型 | 参数量 | 特点 |
|---|---|---|
OLMoASR-tiny.en | 39M | 轻量级,适合边缘设备 |
OLMoASR-base.en | 74M | 小模型高效率 |
OLMoASR-small.en | 244M | 平衡性能与资源消耗 |
OLMoASR-medium.en | 769M | 主流性能段位 |
OLMoASR-large.en-v1 | 1.5B | 训练于 44 万小时音频 |
OLMoASR-large.en-v2 | 1.5B | 训练于 68 万小时音频,与 Whisper-large-v1 相当 |
所有模型均专注于英语语音识别,采用统一架构设计,便于横向对比与研究。
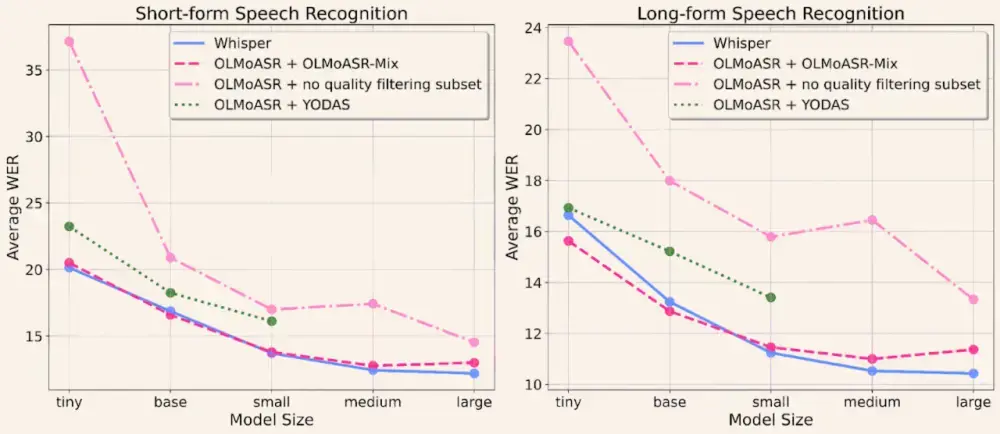
性能表现:媲美 Whisper,部分场景更优
为验证模型鲁棒性,团队在 21 个多样化测试集上进行了评估,涵盖:
- 有声书、播客、电话录音
- 会议记录、讲座、访谈
- 多种口音、语速与背景噪声
结果表明:
OLMoASR-medium.en在短语音任务中达到 12.8% WER,长语音为 11.0% WER,与同规模 Whisper 模型性能相当OLMoASR-large.en-v2(68万小时训练)将与 Whisper-large-v1 的 WER 差距缩小至 仅 0.4%- 小模型如
tiny和base在长语音任务中表现优于 Whisper 对应版本
这意味着:即使不依赖多语言数据或私有语料,纯英语专用模型也能达到顶尖水平。
真正的创新:数据优先的开放策略
OLMoASR 的最大突破不在模型结构,而在数据构建方式。
数据来源:300万小时原始音频池(OLMoASR-Pool)
- 来自公开网络资源
- 包含约 1700 万条音频-文本对
- 覆盖广泛语音类型,但包含大量噪声
多阶段过滤:提炼出高质量子集(OLMoASR-Mix)
通过严格的数据清洗流程,最终构建出 100 万小时高质量音频-文本对,关键步骤包括:
- 语言对齐:移除音频与文本语言不符的样本
- 去噪处理:过滤机器生成的全大写转录、重复行
- 忠实度筛选:基于自动对齐质量(WER)剔除低信噪比片段
这套流程完全开源,允许研究者分析每一步对最终性能的影响。
为什么“开放数据”如此重要?
许多现有开源 ASR 模型(如 Distil-Whisper、Parakeet)虽然发布了模型,但训练数据仍模糊不清。这导致:
- 无法判断性能提升来自数据还是架构
- 难以复现实验结果
- 无法针对性改进数据偏差
OLMoASR 改变了这一点。它提供了一个可控的实验平台,让研究者可以:
- 测试不同过滤策略的效果
- 分析数据质量对泛化能力的影响
- 构建更公平的评估基准
正如 AI2 所强调:数据质量与规模同等重要。OLMoASR 用实证证明了这一点。
完全开放的技术栈
OLMoASR 不只是一个模型发布,而是一个完整的开放研究平台,公开内容包括:
- 📁 OLMoASR-Pool:原始 300 万小时数据索引
- 🧹 数据处理与过滤代码:完整清洗流水线
- 🧠 模型权重与训练管道:支持复现训练过程
- 📊 评估代码与脚本:统一测试框架
所有资源均可在 Hugging Face 和 AI2 官网获取。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...