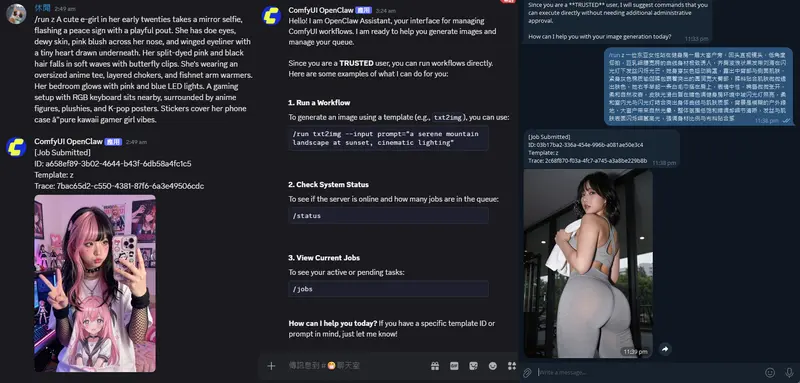
这是一个由 ShmuelRonen 最初创建的重构节点。ComfyUI 的非官方自定义节点集成,用于使用 ResembleAI 的 ChatterboxTTS 进行高质量文本转语音(TTS)和语音转换(VC),支持无限文本长度,并新增了专门处理 SRT 字幕时间 的节点。
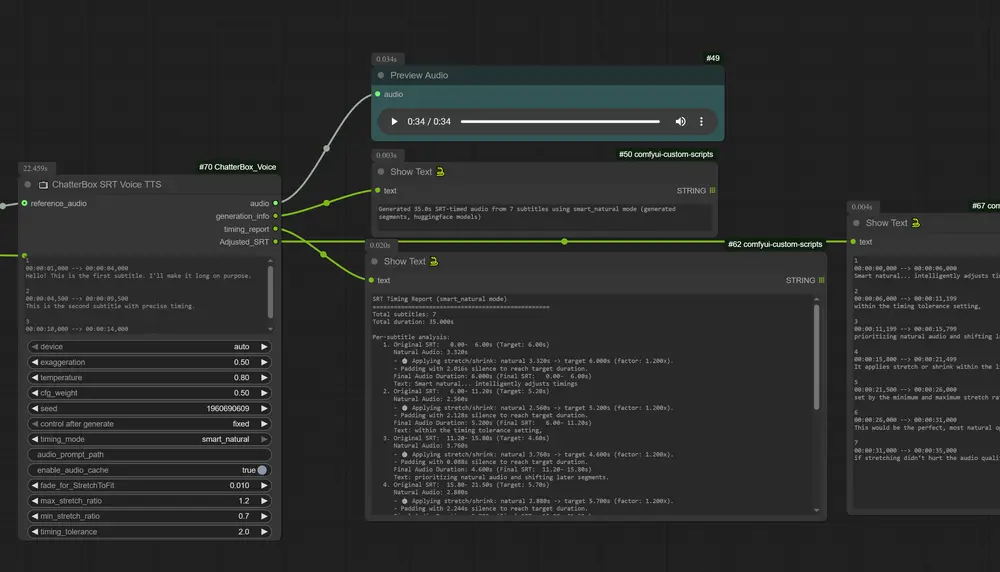
新增功能:SRT 时间与 TTS 节点
ChatterBox SRT Voice TTS 节点通过解析 SubRip 字幕(SRT)文件进行 TTS 生成,确保输出音频与字幕时间轴精确对齐。
主要特性:
- SRT 风格处理:按字幕节奏生成语音,保持音画同步。
- smart_natural 时间模式:智能分配片段间隔,避免重叠,保证自然语音流。
- Adjusted_SRT 输出:返回实际生成音频的时间戳,便于后续处理。
- 片段级缓存机制:仅重新生成修改过的片段,提高效率,节省资源。
如需深入了解,请查阅项目目录下的 SRT_IMPLEMENTATION.md 文件。
ChatterBox 文本转语音(TTS)功能概览
新增功能:
- 🎙️ 音频捕获节点:支持录音输入,用于语音克隆。
- 🎙️ F5-TTS 节点:提供多语言支持的高质量语音合成。
- 🔍 音频分析节点:用于提取语音特征与时间戳。
核心功能:
| 功能 | 描述 |
|---|---|
| 🎤 ChatterBox TTS | 支持文本生成语音,可选语音克隆 |
| 🎙️ F5-TTS | 基于参考音频与文本的高质量语音合成 |
| 🔄 ChatterBox VC | 实现语音风格转换 |
| 🎙️ 语音录制 | 内置静音检测的录音节点 |
| ⚡ 快速高效 | 性能优于 ElevenLabs 等主流服务 |
| 🎭 情感控制 | 可调节夸张参数,增强语音表现力 |
| 🌍 多语言支持 | 英语、德语、西班牙语、法语、日语等 |
| 📝 智能分块 | 自动拆分长文本,适应任意长度输入 |
| 📦 自包含模型 | 不依赖额外安装即可运行 |
| 🎵 音频处理 | 支持 FFmpeg 高质量拉伸,内置回退机制 |
| 🌊 波形分析器 | 可视化波形,辅助 F5-TTS 工作流 |
安装步骤
1. 安装 ChatterBox SRT Voice 插件
cd ComfyUI/custom_nodes
git clone https://github.com/diodiogod/ComfyUI_ChatterBox_SRT_Voice.git2. 安装依赖项
建议先更新 pip、setuptools 和 wheel:
python -m pip install --upgrade pip setuptools wheel然后安装插件所需依赖:
pip install -r requirements.txt3. 安装 FFmpeg(推荐)
Windows:
winget install FFmpeg
# 或使用 Chocolatey
choco install ffmpeg如果未安装 FFmpeg,系统将自动使用内置相位声码器进行音频处理,不影响正常使用。
下载模型文件
请将以下模型文件放置在:ComfyUI/models/TTS/chatterbox/
| 文件名 | 大小 | 描述 |
|---|---|---|
| conds.pt | 105 KB | 条件向量 |
| s3gen.pt | ~1 GB | 生成器模型 |
| t3_cfg.pt | ~1 GB | CFG 模型 |
| tokenizer.json | 25 KB | 分词器配置 |
| ve.pt | 5.5 MB | 编码器模型 |
🔗 下载地址:ResembleAI/chatterbox on HuggingFace
可选:F5-TTS 模型下载
适用于需要多语言语音合成的用户。
| 模型名称 | 语言 | 文件大小 | 下载链接 |
|---|---|---|---|
| F5TTS_Base | 英语 | ~1.2GB | HuggingFace |
| F5-DE | 德语 | ~1.2GB | HuggingFace |
| F5-ES | 西班牙语 | ~1.2GB | HuggingFace |
| F5-FR | 法语 | ~1.2GB | HuggingFace |
| F5-JP | 日语 | ~1.2GB | HuggingFace |
声码器(Vocos)推荐安装:
ComfyUI/models/F5-TTS/vocos/
├── config.yaml
├── pytorch_model.bin
└── vocab.txt语音参考管理
为方便语音克隆管理,建议创建如下结构:
ComfyUI/models/voices/
├── character1.wav
├── character1.txt
├── narrator.wav
├── narrator.txt
├── my_voice.wav
└── my_voice.txt要求:
- WAV 格式,5~30 秒,无背景噪音
- 文本文件为音频内容的准确转录
- 同名
.wav与.txt文件配对
可选:语音录制依赖安装
pip install sounddevice完成后重启 ComfyUI。
增强功能详解
📝 智能文本分块(新增!)
支持长文本自动切片生成语音,保留句子完整性,并提供多种拼接方式:
- 字符限制:每段 100~1000 字符
- 句子边界保留:不在句中打断
- 组合方式:
- auto(自动)
- concatenate(直接拼接)
- silence_padding(添加静音)
- crossfade(交叉淡出淡入)
- comma_split(基于逗号分割)
默认设置:
max_chars_per_chunk=400chunk_combination_method=autosilence_between_chunks_ms=100
📦 智能模型加载机制
优先级顺序:
- 插件自带模型(自包含)
- ComfyUI 默认模型路径
- HuggingFace 在线下载
控制台示例输出:
📦 使用捆绑的 ChatterBox(自包含)
📦 从捆绑模型加载:./models/chatterbox
✅ ChatterboxTTS 模型已从捆绑加载!
使用方法说明
语音录制节点
- 添加
🎤 ChatterBox Voice Capture - 设置麦克风、静音阈值、采样率
- 更改
Trigger值开始录音 - 输出可用于语音克隆或语音转换
文本转语音节点
- 添加
🎤 ChatterBox Voice TTS - 输入文本(任意长度)
- 可选连接参考音频
- 调整情感强度、温度、CFG 权重等参数
F5-TTS 节点
- 添加
🎤 F5-TTS Voice Generation - 输入目标文本
- 连接参考音频与文本
- 选择对应语言模型(英语、德语、日语等)
语音转换节点
- 添加
🔄 ChatterBox Voice Conversion - 连接源音频与目标音频
- 实现语音风格迁移
工作流示例
示例一:长文本智能分块
文本输入(2000+ 字符) → ChatterBox TTS(启用分块) → PreviewAudio示例二:语音克隆与录制
🎤 Voice Capture → ChatterBox TTS(参考音频) → PreviewAudio示例三:F5-TTS 多语言语音合成
德语文本 → F5-TTS(F5-DE 模型) → PreviewAudio
西班牙语文本 → F5-TTS(F5-ES 模型) → PreviewAudio示例四:语音转换管道
🎤 Voice Capture(源) → ChatterBox VC ← 🎤 Voice Capture(目标)推荐设置指南
分块设置建议
| 场景 | 参数配置 |
|---|---|
| 长篇文章/书籍 | max_chars_per_chunk=600, combination_method=silence_padding, silence_between_chunks_ms=200 |
| 自然语音 | max_chars_per_chunk=400, combination_method=auto |
| 快速处理 | max_chars_per_chunk=800, combination_method=concatenate |
| 平滑音频 | max_chars_per_chunk=300, combination_method=crossfade |
录音设置建议
| 场景 | 参数配置 |
|---|---|
| 常规环境 | silence_threshold=0.01, silence_duration=2.0 |
| 嘈杂环境 | threshold=0.05, duration=3.0 |
| 安静环境 | threshold=0.005, duration=1.0 |
TTS 参数建议
| 场景 | 参数配置 |
|---|---|
| 常规使用 | exaggeration=0.5, cfg_weight=0.5 |
| 表现力强的语音 | exaggeration=0.7, cfg_weight=0.3 |
文本处理能力对比
与其他 TTS 服务相比,ChatterBox 几乎没有文本长度限制:
| 服务 | 最大字符数 |
|---|---|
| OpenAI TTS | 4096 |
| ElevenLabs | 2500 |
| ChatterBox TTS | 无硬性限制 + 智能分块 |
智能文本分割逻辑:
- 在句号(.)、问号(?)、感叹号(!)处分割
- 保持句子完整性
- 长句按逗号分割,必要时按字符限制切割
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...