
在文本到图像(Text-to-Image, T2I)生成领域,开发者通常会基于强大的基础模型(如Stable Diffusion 1.5)进行微调,以适应特定风格或场景的需求。例如,某些模型专注于生成逼真的肖像,而另一些则擅长动漫风格或插画风格的图像。然而,这种做法导致了大量专用模型的涌现,每个模型都包含数十亿参数,带来了显著的参数冗余和存储成本问题。

为了解决这一问题,南京大学、阿里巴巴和上海AI实验室的研究团队提出了一种全新的方法——基于评分蒸馏的模型融合范式(Distilled Model Merging, DMM)。DMM的核心目标是将多个预训练的T2I模型的能力整合到一个单一的多功能模型中,从而大幅减少参数冗余和存储开销,同时支持灵活的风格控制。
- GitHub:https://github.com/MCG-NJU/DMM
- 模型:https://huggingface.co/MCG-NJU/DMM
- Demo:https://huggingface.co/spaces/MCG-NJU/DMM
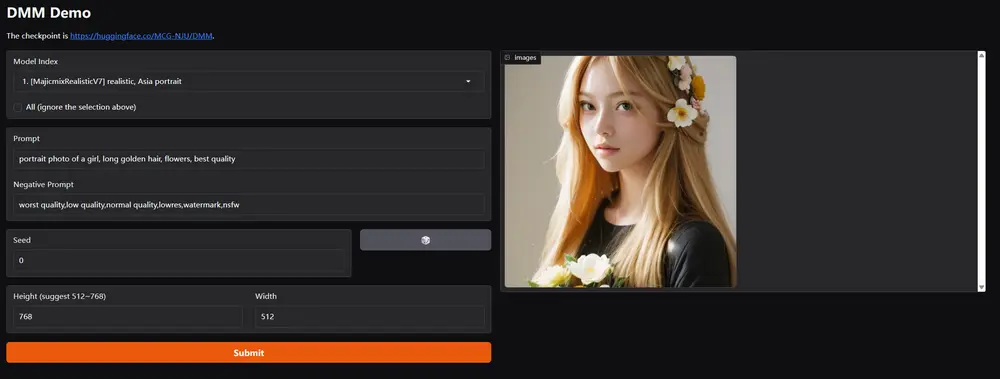
开发团队释出的模型合并了来自多个不同领域的SD1.5模型,包括写实风格、亚洲肖像、动漫风格、插图等。具体来说,是以下这些模型:
- JuggernautReborn
- MajicmixRealisticV7
- EpicRealismV5
- RealisticVisionV5
- MajicmixFantasyV3
- MinimalismV2
- RealCartoon3dV17
- AWPaintingV1.4
DMM的主要功能与特点
1. 多功能图像生成
DMM能够生成多种风格的高质量图像,包括但不限于:
逼真的照片 动漫风格的图像 插画风格的艺术作品
用户无需部署多个独立模型,只需使用DMM即可满足多样化的生成需求。
2. 灵活的风格控制
DMM引入了一种基于嵌入的风格提示机制,允许用户通过简单的风格提示(style prompts)在推理时灵活控制生成图像的风格。无论是生成单一风格的图像,还是混合不同风格,DMM都能轻松应对。
3. 高效的模型合并
DMM采用知识蒸馏技术,将多个教师模型的知识转移到一个学生模型中,从而显著减少了参数冗余和存储成本。这种方法不仅提升了模型的效率,还保留了各源模型的核心能力。
4. 增量学习与正则化
DMM支持增量学习,可以逐步合并新的模型,同时通过正则化策略避免灾难性遗忘,确保模型在学习新风格时不会丢失已掌握的能力。
5. 兼容性与扩展性
DMM与各种下游插件(如ControlNet、LoRA、IP-Adapter)完全兼容,无需额外训练即可无缝集成到现有工作流中。
DMM的工作原理
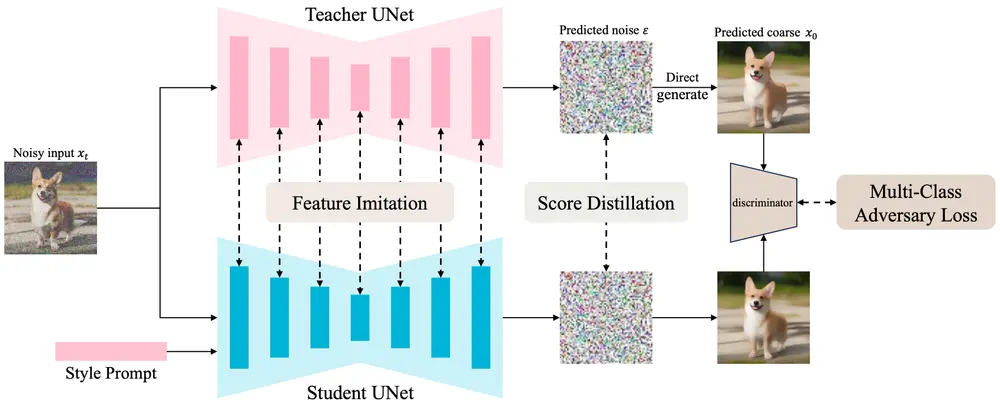
1. 分数蒸馏
DMM通过最小化学生模型和教师模型之间的分数函数差异来实现知识转移。分数函数是数据分布的梯度对数概率密度函数,通过最小化分数函数的均方误差来训练学生模型。这一过程确保学生模型能够继承教师模型的核心能力。
2. 特征模仿
DMM利用中间特征图的监督来促进知识转移和风格学习。具体而言,通过最小化学生模型和教师模型中间层特征图的差异,增强模型对不同风格的学习能力。这种机制使得DMM能够更精确地捕捉不同风格的细节。
3. 多类别对抗损失
为了进一步提升模型对不同风格的区分能力,DMM引入了一个多类别对抗损失,训练一个生成对抗网络(GAN)来区分不同风格的图像。这种方法不仅提高了生成图像的质量,还增强了模型对复杂风格的理解。
4. 风格提示机制
DMM将不同风格的先验表示为一个可训练的嵌入代码本(style prompts)。这些嵌入在训练过程中被优化,并在推理时用于控制生成图像的风格。用户可以通过调整风格提示轻松切换或混合不同风格。
5. 增量学习
DMM支持增量学习,允许在训练过程中冻结预训练的学生模型,并使用新的风格提示进行微调。这种方法使得DMM能够逐步合并新的模型,同时保持已有风格的稳定性。
实验结果与性能表现
研究团队的实验表明,DMM在以下几个方面表现出色:
紧凑性:DMM能够高效地重组来自多个教师模型的知识,显著减少了参数规模和存储需求。 可控性:通过风格提示机制,DMM能够实现精准的风格控制,生成符合用户需求的任意风格图像。 兼容性:DMM与主流插件和工具链高度兼容,能够无缝集成到现有的工作流中。
例如,DMM可以生成逼真的肖像、动漫风格的图像,甚至将这两种风格混合在一起,而无需单独部署多个模型。此外,DMM在多个基准测试中表现优异,超越了许多单一风格的专用模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











