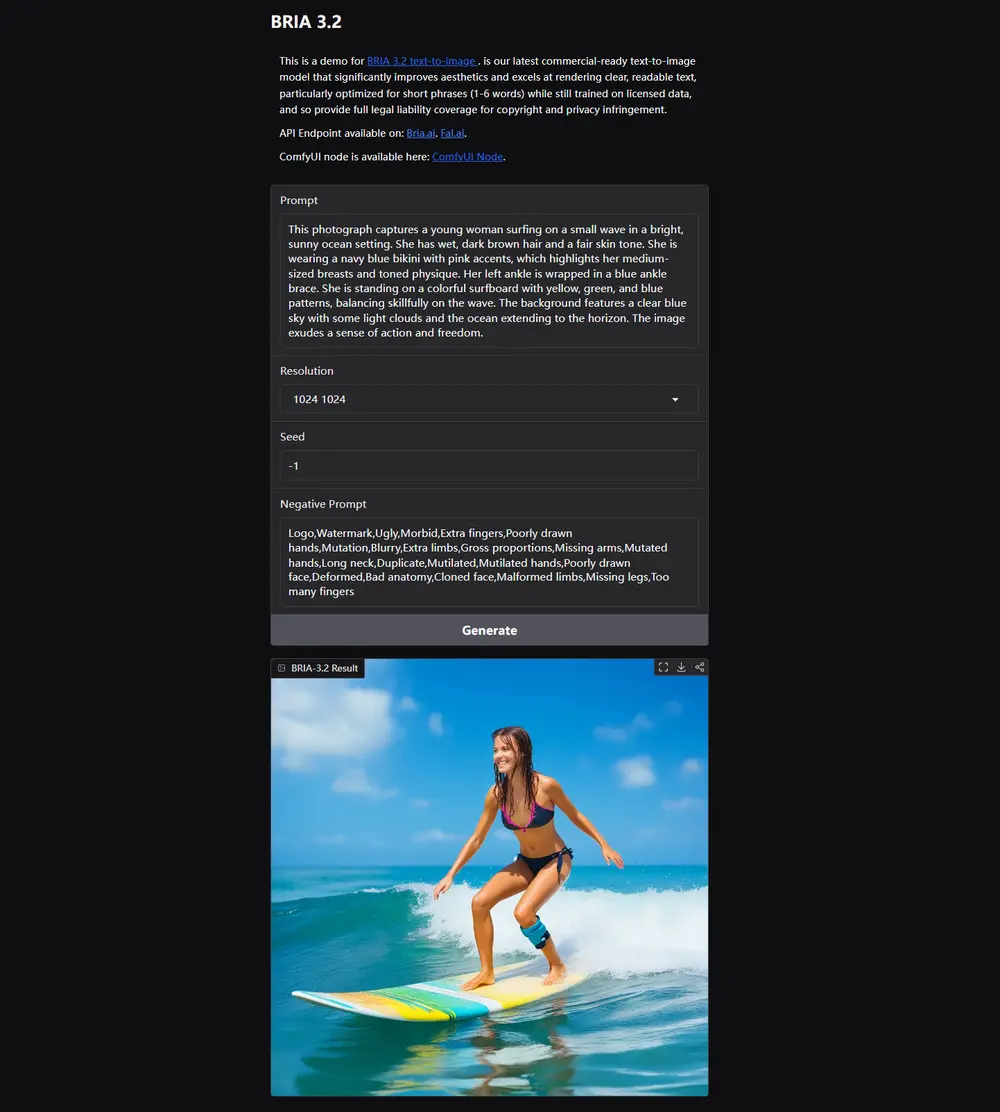
BRIA AI 正式发布其最新文本到图像模型 Bria 3.2。作为一款专为企业和商业应用打造的生成模型,Bria 3.2 凭借仅 40 亿参数 的轻量架构,在美学效果与文本渲染能力方面表现优异,经评估与主流开源模型相当,甚至优于其他商业许可模型。
- 官网:https://bria.ai
- 模型:https://huggingface.co/briaai/BRIA-3.2
- Demo:https://huggingface.co/spaces/briaai/BRIA-3.2
除了完全基于 100% 许可数据训练 外,Bria 3.2 在企业级部署和商业使用场景中展现出显著优势。
核心优势一览
✅ 高效计算
Bria 3.2 模型体积仅为市场上同类模型的三分之一(对比 120 亿参数模型),显著降低硬件资源消耗,提升推理效率。
✅ 架构一致性
延续 Bria 3.1 的架构设计,便于已有用户实现无缝升级,无需重构工作流。
✅ 微调加速
在 L40S 和 A100 等主流 GPU 上,微调速度较前代提升 2 倍,大幅提升定制化开发效率。
训练数据与法律合规性
Bria 3.2 是目前市面上少数真正做到 100% 使用合法授权数据训练 的文本到图像模型之一。其训练数据不包含任何受版权保护的内容,如虚构角色、商标、公众人物、有害或隐私信息,确保输出内容在商业使用中的安全性。

此外,Bria AI 还为其基础模型提供 全面法律责任覆盖,从源头保障用户在商业项目中的合规使用。
与前代模型相比的新特性
🎨 美学表现更佳
- 65% 用户偏好度 提升于 Bria 3.1
- 76% 用户偏好度 提升于 Bria 2.3
📝 卓越的文本渲染能力
特别优化了对 1-6 字短文本 的生成能力,OCR 分数由 3.1 的 5% 显著提升至 3.2 的 70%。
🔄 更强的提示对齐能力
保持高质量的文本描述理解与执行能力,确保生成结果与输入提示高度一致。
获取方式与使用支持
Bria 3.2 支持多种集成方式,满足不同开发者和企业的技术需求:
主要技术特性
- 模型架构:基于 40 亿参数的整流流变压器(Rectified Flow Transformer)模型,搭配 T5 文本编码器。
- 法律合规性:100% 合法授权数据训练,提供版权与隐私侵权的全面法律责任保障。
- 专利归因引擎:通过专有算法为数据合作伙伴提供补偿机制,确保数据使用的道德性和可持续性。
- 企业级适用性:专为商业用途设计,适用于广告、电商、游戏、媒体等多个行业。
- 可定制性强:提供源码与权重访问权限,支持根据具体业务需求进行个性化调整与优化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...