近日,阿里巴巴通义实验室Ovis团队正式发布了新一代统一多模态大模型——Ovis-U1。该模型以30亿参数为基础,实现了对多模态任务的全面覆盖,涵盖图像理解、文本到图像生成以及图像编辑三大核心能力。
- GitHub:https://github.com/AIDC-AI/Ovis-U1
- 模型:https://huggingface.co/AIDC-AI/Ovis-U1-3B
- Demo:https://huggingface.co/spaces/AIDC-AI/Ovis-U1-3B
不同于以往需要多个独立模型分别完成不同任务的方式,Ovis-U1在一个统一框架中整合了多项功能,显著提升了模型在复杂场景下的适应性和泛化能力。
什么是Ovis-U1?
Ovis-U1是基于Ovis系列迭代而来的统一多模态模型,拥有30亿参数规模。它由阿里Ovis团队研发,在一个模型中集成了三项关键能力:
- 多模态理解(图像识别与描述)
- 文本到图像生成
- 图像编辑(局部或整体修改)
这种统一架构的设计理念,标志着多模态AI系统向“多功能一体化”迈出的重要一步。
核心亮点
1. 统一模型,三重能力
Ovis-U1无需依赖多个子模型即可完成理解、生成和编辑任务。这不仅降低了部署成本,也提升了响应效率。
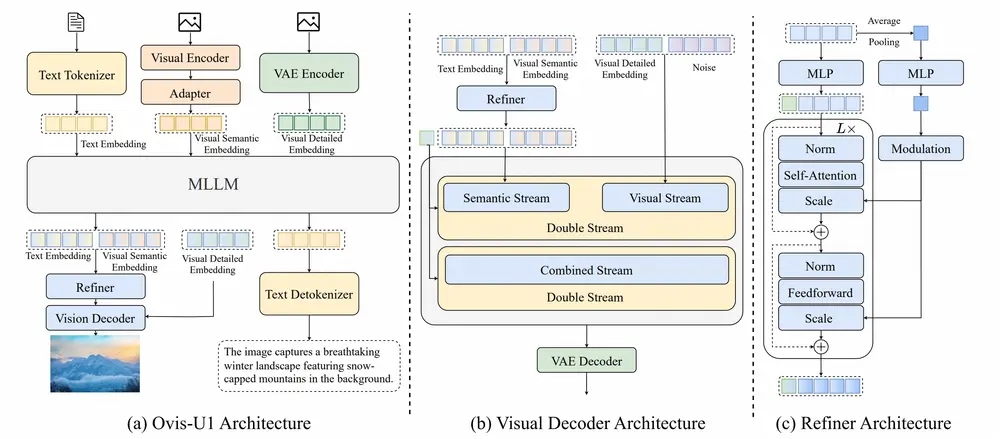
2. 先进架构设计
- 视觉解码器:采用基于扩散机制的MMDiT模块,支持高质量图像合成。
- 双向标记优化器:提升文本与视觉嵌入之间的交互质量,增强语义一致性。
- 适配器机制:有效连接视觉编码器与多模态语言模型,实现信息融合。
3. 协同训练策略
与传统单任务训练方式不同,Ovis-U1在理解、生成和编辑数据上进行联合训练,使模型具备更强的跨任务迁移能力。
4. 高性能表现
尽管参数规模仅为30亿,但Ovis-U1在多个权威基准测试中表现出色,甚至超越了一些更大参数量的模型。
实际应用示例
1. 多模态理解
输入一张厨房台面的图片,Ovis-U1可以准确描述:“图中展示了一个厨房台面,上面有刚炸好的薯条。背景中有一个炸锅,一个装薯条的碗、一个番茄酱罐子和一个西红柿。台面由带有斑点图案的花岗岩制成。”

2. 文本到图像生成
用户输入:“在森林边缘的右边添加一个小木屋,带有烟囱。”模型可据此生成符合描述的图像。
3. 图像编辑
对于一张包含游艇的图像,用户要求“将图像中的游艇替换为漂浮在海面上的热气球”,Ovis-U1能精准执行该指令。
关键技术组成
| 模块 | 功能说明 |
|---|---|
| 文本分词器 | 将输入文本转化为模型可处理的嵌入表示 |
| 多模态大语言模型(MLLM) | 融合文本与视觉信息,进行推理与决策 |
| 视觉编码器 | 提取图像特征,用于理解和编辑 |
| 视觉解码器(MMDiT) | 生成高分辨率图像,支持多种风格 |
| 双向令牌细化器 | 提升文本与图像嵌入的匹配精度 |
训练流程详解
Ovis-U1的训练分为六个阶段,逐步引入各个模块并优化整体性能:
- 预训练视觉解码器:构建基础图像生成能力;
- 训练适配器与编码器:实现图文信息的初步融合;
- 微调MLLM部分:增强多模态推理能力;
- 联合训练理解与生成模块;
- 加入图像编辑能力训练;
- 整体微调优化:提升模型在真实场景下的表现。
性能评估结果
Ovis-U1在多个权威多模态评测基准中表现优异:
| 基准测试 | 得分 | 对比模型 |
|---|---|---|
| OpenCompass(多模态理解) | 69.6 | 超越Ristretto-3B、SAIL-VL-1.5-2B |
| DPG-Bench(图像生成) | 83.72 | 表现优于多数主流模型 |
| ImgEdit-Bench(图像编辑) | 4.00 | 在编辑准确性方面领先 |
| GEdit-Bench-EN | 6.42 | 展现出强大的编辑泛化能力 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











