
文本到图像(T2I)生成技术的进步,离不开强化学习方法的优化与基准测试的支撑。但当前领域存在两大核心问题:一是传统强化学习依赖“点式奖励模型”打分,易出现“分数涨而质量降”的奖励操控现象;二是现有基准测试标准粗糙、覆盖维度窄,难以全面评估模型性能。
- 项目主页:https://codegoat24.github.io/UnifiedReward/Pref-GRPO
- GitHub:https://github.com/CodeGoat24/Pref-GRPO
- 模型:https://huggingface.co/CodeGoat24/FLUX.1-dev-PrefGRPO
针对这两大痛点,复旦大学、上海创新研究院、上海人工智能实验室、腾讯混元及上海交通大学的研究团队联合提出解决方案:一方面,研发出首个基于人工智能偏好奖励的GRPO方法(Pref-GRPO),重构T2I模型的优化目标;另一方面,构建统一的T2I生成基准(UniGenBench),实现细粒度的语义一致性评估。两者协同,既解决了训练稳定性问题,又补上了评估体系的短板。
行业痛点:T2I生成的“训练”与“评估”双瓶颈
在Pref-GRPO与UniGenBench提出前,T2I生成领域的两大问题长期制约技术落地,具体可拆解为以下两点:
1. 训练端:点式奖励模型引发“奖励操控”,质量与分数脱节
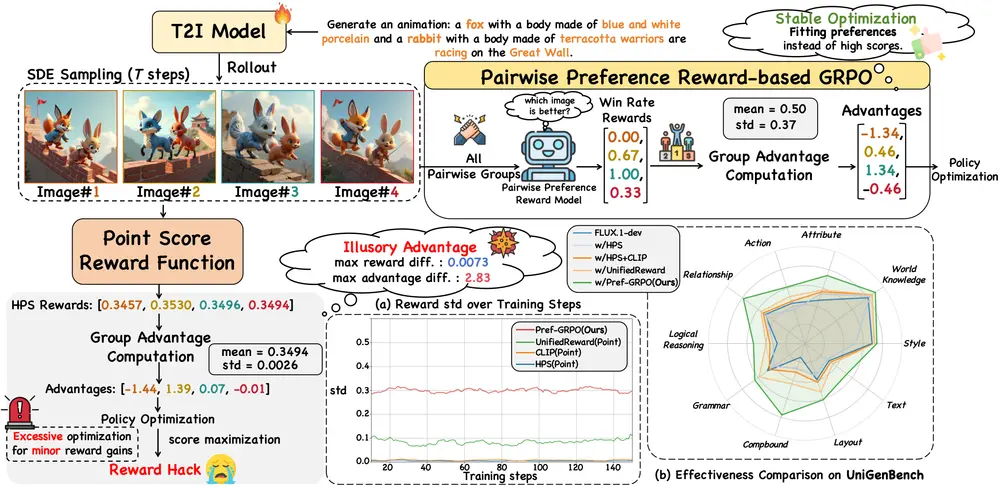
传统T2I强化学习采用“点式奖励模型(RM)”——对生成的一组图像逐一打绝对分数,再通过分数归一化计算“优势值”,指导模型优化策略。这种“以分数最大化为目标”的范式看似直接,却存在致命缺陷:
- 生成图像间的奖励分数差异往往微小(比如A图8.1分、B图8.2分),但经过群体归一化后,这些微小差异会被不成比例地放大;
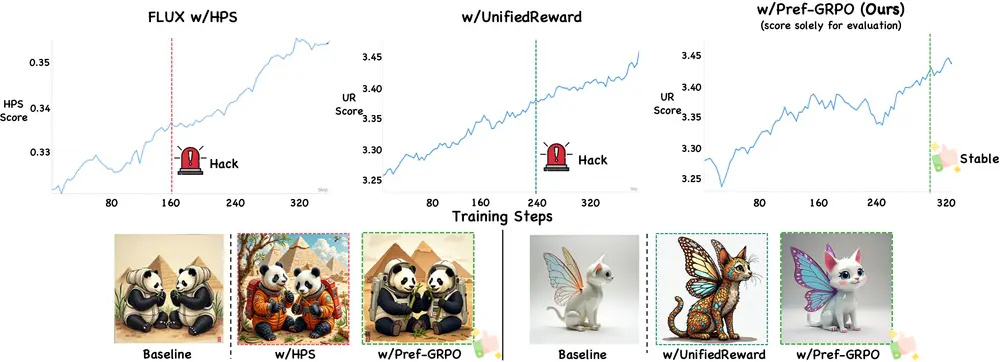
- 模型会“钻空子”过度优化这些“微不足道的分数增益”,导致最终生成的图像“分数上涨但实际质量下降”(即奖励操控),训练过程也因此变得不稳定。
研究团队指出,问题的根源在于“绝对分数”无法真实反映图像质量差异,微小的分数波动被放大后,反而误导了模型的优化方向。
2. 评估端:现有基准覆盖窄、标准粗,难测模型真实能力
当前T2I基准测试存在明显局限:
- 评估标准粗糙:多聚焦“整体观感”等模糊维度,缺乏对“语义一致性”“逻辑合理性”等关键子维度的细分;
- 覆盖范围狭窄:提示词(Prompt)数量少、主题单一,无法覆盖艺术、插图、创意发散等多样化场景;
- 评估颗粒度低:每个提示词仅对应少量测试点,难以精准定位模型在“风格还原”“世界知识匹配”等具体能力上的强弱。
这些问题导致开发者无法全面掌握模型的优势与短板,也难以针对性地进行迭代优化。
核心解决方案:Pref-GRPO与UniGenBench的协同突破
针对上述痛点,研究团队从“训练方法”和“评估基准”两端同时发力,提出Pref-GRPO与UniGenBench,形成“优化-评估”的闭环。
1. Pref-GRPO:用“成对偏好”替代“绝对分数”,终结奖励操控
Pref-GRPO的核心思路是“变‘打分’为‘比优劣’”——将优化目标从“最大化绝对奖励分数”转变为“拟合人类(或AI)的成对偏好”,具体实现逻辑如下:
(1)核心设计:成对偏好奖励模型(PPRM)
- 不再对单张图像打绝对分,而是在每一步训练中,将生成的图像组成“图像对”;
- 通过成对偏好奖励模型(PPRM)对每一组图像对进行比较,判断“哪张图像更符合文本提示、质量更高”;
- 计算每张图像在所有对比中的“胜率”(比如一张图像与10张图像对比,赢了7次,胜率即为70%),并以“胜率”作为模型优化的奖励信号。
(2)解决奖励操控的关键逻辑
- 相比“微小分数差异被放大”的点式奖励,“胜率”能更真实地反映图像质量的相对差异——即使两张图像质量接近,PPRM也能通过细粒度对比区分优劣,避免“为涨分而优化”;
- 奖励信号从“绝对数值”变为“相对胜率”,减少了“分数归一化”带来的波动,让模型优化方向更稳定,最终缓解“分数涨而质量降”的问题。
2. UniGenBench:600个提示、27个子维度,构建T2I评估“全景图”
为填补评估体系的空白,团队构建了统一的T2I生成基准UniGenBench,其核心特点是“覆盖广、颗粒细、评估准”,具体设计如下:
(1)多维度提示词体系
- 包含600个精心设计的提示词,覆盖5个主要主题(艺术创作、场景插图、创意发散、日常物品生成、逻辑场景还原)和20个子主题(如“印象派风景”“赛博朋克城市”“拟人化动物”等);
- 每个提示词对应多个“测试点”,确保能精准考察模型在不同场景下的表现(比如“生成一只戴帽子的猫”,会同时测试“动物形态还原”“配饰细节呈现”“风格一致性”等测试点)。
(2)细粒度评估维度
- 建立“10个主要维度+27个子维度”的评估框架,主要维度包括“语义一致性”“风格还原度”“世界知识匹配”“逻辑推理”“细节丰富度”等;
- 子维度进一步细分(如“世界知识匹配”下分为“物体比例正确性”“场景合理性”“常识逻辑”),确保能定位模型在具体能力上的短板。
(3)高效自动化评估流程
- 借助多模态大语言模型(MLLM)的“通用世界知识”与“细粒度图像理解能力”,实现提示词的自动化生成与模型结果的自动化评估;
- 无需人工逐一打分,既保证了评估效率,又通过MLLM的一致性判断减少了人工主观偏差。
实测效果:性能与稳定性双提升
通过在UniGenBench上的测试,Pref-GRPO与现有方法相比,展现出显著优势,具体结果可从“语义一致性”“图像质量”“训练稳定性”三方面体现:
1. 语义一致性:显著超越基线方法
Pref-GRPO在UniGenBench的“总体语义一致性”评分中达到69.46%,相比基于“统一奖励(UnifiedReward)”的传统方法,提升了5.84个百分点——这意味着模型生成的图像与文本提示的匹配度更高,更少出现“文不对图”的情况。
2. 图像质量:分数与质量真正挂钩
在UnifiedReward的图像质量评估中,Pref-GRPO得分为3.26(满分5分),显著高于基线方法;更关键的是,其质量提升并非“靠分数操控实现”,而是通过PPRM的成对偏好判断,确保“高分对应高真实质量”。
3. 训练稳定性:有效抑制奖励操控
在持续训练过程中,Pref-GRPO生成的图像质量始终保持稳定,未出现“分数上涨但质量下降”的奖励操控现象;而传统点式奖励模型在训练后期,会明显出现“图像细节失真”“语义偏离”等问题。
行业价值:为T2I生成提供“优化-评估”新范式
Pref-GRPO与UniGenBench的联合提出,不仅解决了当前T2I领域的两大痛点,更为行业提供了“训练方法-评估基准”的协同范式:
- 对开发者而言:Pref-GRPO提供了更稳定的训练路径,无需担心“奖励操控”;UniGenBench则能精准定位模型短板,让迭代更有方向;
- 对行业而言:填补了“细粒度T2I评估”的空白,为不同T2I模型的性能对比提供了统一标准,避免“各说各话”的评估乱象;
- 对应用端而言:更稳定的训练与更全面的评估,能推动T2I模型在设计、广告、创意等领域的落地——生成的图像不仅“好看”,更能“精准匹配需求”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











