
来自俄罗斯的AI企业Sber AI,正式推出新一代扩散模型家族 Kandinsky 5.0,以“全场景覆盖+开源开放”为核心亮点,涵盖视频生成(T2V/I2V)、图像生成(T2I)、图像编辑三大核心能力,同时提供 Pro 专业版与 Lite 轻量版双系列模型,支持中俄双语提示词、最高 HD 分辨率输出,且通过硬件优化让 12GB 显存 GPU 即可运行,彻底降低前沿生成式AI的使用门槛。
- 项目主页:https://kandinskylab.ai
- GitHub:https://github.com/kandinskylab/kandinsky-5
- 模型:https://huggingface.co/kandinskylab

模型家族全景:Pro 级性能与 Lite 级便捷的双重选择
Kandinsky 5.0 构建了完整的模型生态,针对不同用户需求(专业创作、科研微调、日常试用)提供细分版本,核心分为四大系列:
1. Kandinsky 5.0 Video Pro:190亿参数的专业视频生成利器
作为家族旗舰级视频模型,190亿参数量确保了HD级生成质量,专为商业创作、专业内容生产设计:
- 核心能力:支持文本到视频(T2V)、图像到视频(I2V)双向生成,可输出 5 秒或 10 秒时长视频,提供 HD(高清)与 SD(标清)两种分辨率选项;
- 差异化优势:具备可控相机运动功能,配合 Qwen2.5-VL 与 CLIP 双文本嵌入模型,对中俄双语提示词的理解精准度行业领先;
- 模型变体:
- SFT 模型:主打最高生成质量,适合直接商用产出;
- 预训练模型:专为研究者、开发者提供,支持二次微调适配特定场景;
- 性能表现:在 NVIDIA H100 GPU 上,5 秒 SD 版本延迟仅 560 毫秒,HD 版本延迟 1241 毫秒(二次推理后测量,首次运行含编译过程)。
2. Kandinsky 5.0 Video Lite:20亿参数的开源轻量标杆
针对消费级用户与硬件资源有限的场景,Lite 版以 20 亿参数量实现“轻量化+高性能”平衡,在开源模型中排名同类第一:
- 核心能力:同样支持 T2V/I2V 生成,输出 5-10 秒视频,对俄语概念的理解能力在开源生态中处于领先水平,优于更大参数量的 Wan 模型(50 亿/140 亿参数);
- 速度优化:提供多种加速变体,CFG 蒸馏版运行速度快 2 倍,扩散蒸馏版快 6 倍且质量损失最小,5 秒蒸馏版延迟仅 35 秒(H100 GPU 环境);
- 模型变体:包含 SFT 版(高质量)、CFG-蒸馏版(高速)、扩散-蒸馏版(低延迟)、预训练版(可微调),满足不同速度与质量需求。
3. Kandinsky 5.0 Image Lite:60亿参数的高保真图像生成
聚焦图像生成场景,60亿参数量兼顾质量与效率:
- 核心能力:支持 1K 分辨率输出(1280x768、1024x1024 等主流比例),具备高视觉保真度与强大的文本书写功能,可精准还原复杂排版与多语言文字;
- 优势亮点:对俄语提示词的理解能力突出,适合俄语区创作者或多语言场景使用,延迟仅 13 秒(H100 GPU 环境),生成效率行业领先。
4. Kandinsky 5.0 Image Editing:60亿参数的精细化图像编辑
专为图像二次创作设计,完美承接生成后的优化需求:
- 核心能力:支持 1K 分辨率编辑,可基于文本提示对现有图像进行风格转换、细节优化、内容增补,同时保留原图核心特征;
- 协同优势:与 Image Lite 模型共享技术底座,文本书写与俄语理解能力一致,形成“生成-编辑”的完整工作流。
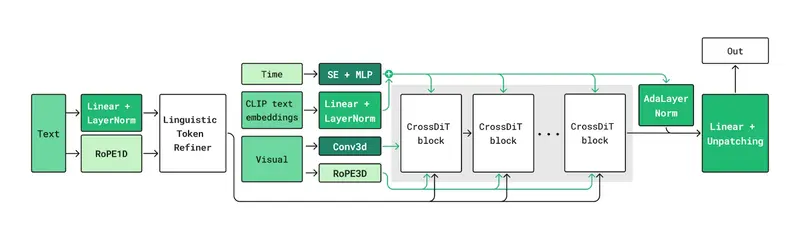
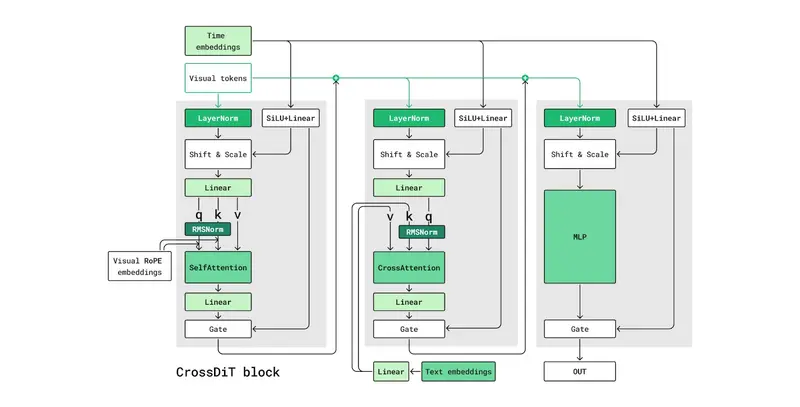
核心技术架构:兼顾质量与效率的底层创新
Kandinsky 5.0 系列模型基于先进的扩散模型技术栈,实现性能突破:
- 生成主干:采用扩散 Transformer(DiT)架构,通过交叉注意力机制深度绑定文本嵌入与视觉生成,提升提示词遵循度;
- 潜在空间优化:集成 HunyuanVideo 3D VAE 进行视频编码/解码,在压缩率与质量之间实现最优平衡;
- 注意力引擎灵活选择:支持 Flash Attention 2/3、Sage Attention、SDPA 多种注意力计算方式,用户可根据硬件配置灵活切换,最大化性能;
- 内存优化:通过 VAE 平铺优化、Bitsandbytes NF4 量化支持,将整体显存需求降低,让 12GB 显存 GPU 即可运行核心模型。
关键更新与硬件适配:从科研到落地的全流程支持
自 2025 年 9 月以来,Kandinsky 5.0 持续迭代核心功能,逐步降低使用门槛:
- 重要更新节点:
- 2025/11/26:简化 LoRa 训练工具开源,降低模型微调难度;
- 2025/11/24:相机控制 LoRa(Lite/Pro 版本)开源,提供完整推理代码;
- 2025/11/20:Kandinsky 5.0 Video Pro 全量开源,T2V/I2V 模型同步上线;
- 2025/10/19:支持 12GB GPU 运行,新增 SDPA 注意力支持,无需 Flash Attention 即可部署;
- 硬件适配要求:
- 专业级部署:推荐 NVIDIA H100 GPU(80GB 显存),适配 CUDA 12.8.1 与 PyTorch 2.8,实现低延迟批量生成;
- 消费级部署:12GB 显存 GPU 可运行 Lite 系列模型,24GB 显存 GPU 可通过内存卸载功能流畅运行 Pro 系列模型;
- 快速上手渠道:所有模型检查点均已在 Hugging Face 开源,支持 ComfyUI 部署(README 已更新适配教程),同时提供完整的配置文件与推理示例代码(examples 目录下)。
差异化优势:中俄双语+全场景开源的独特价值
在当前生成式AI赛道中,Kandinsky 5.0 凭借三大差异化优势脱颖而出:
- 语言适配领先:深耕俄语市场,对俄语概念的理解精准度远超同类开源模型,同时完美支持英语提示词,满足多语言创作需求;
- 全栈功能覆盖:从视频生成(Pro/Lite)、图像生成到图像编辑,形成完整的创作闭环,无需切换多个工具即可完成全流程工作;
- 开源生态友好:所有核心模型均开放权重,提供预训练、SFT、蒸馏等多种变体,支持研究者微调与开发者二次开发,同时降低商业使用门槛。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











