
苹果和瑞士洛桑联邦理工学院的研究人员推出新型图像编码器FlexTok,它能够将二维图像重新采样为长度可变的一维离散标记(token)序列。FlexTok 的核心思想是通过灵活的标记长度来适应图像的复杂性,从而实现高效的图像表示和生成。
- 项目主页:https://flextok.epfl.ch
- GitHub:https://github.com/apple/ml-flextok
- Demo:https://huggingface.co/spaces/EPFL-VILAB/FlexTok
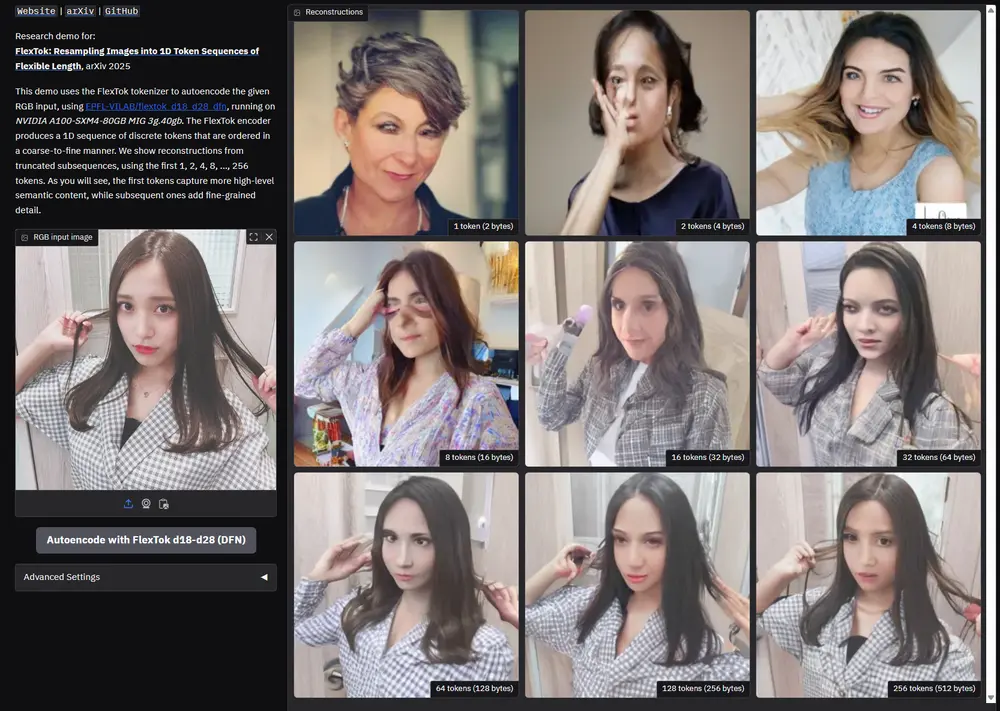
例如,对于简单图像(如单一物体),FlexTok 可以用很少的标记(如8个)进行有效表示;而对于复杂场景(如多人物、多细节的图像),则可以使用更多的标记(如256个)来捕捉细节。
主要功能
FlexTok 的主要功能包括:
- 图像压缩与表示:将二维图像转换为一维标记序列,实现高效的图像压缩。
- 自回归图像生成:支持基于条件(如类别标签或文本描述)的图像生成任务。
- 灵活的标记长度:根据图像复杂性动态调整标记数量,从1个标记到256个标记。
- 语义和几何信息的层次化表示:通过标记序列的顺序,从粗到细地描述图像内容。

主要特点
FlexTok 的主要特点如下:
- 灵活的标记长度:与传统固定长度的标记方法(如 TiTok)不同,FlexTok 可以根据图像的复杂性动态调整标记数量。
- 层次化表示:早期标记捕捉图像的高级语义和几何信息,后续标记逐步添加细节。
- 高效的解码器:使用基于修正流(rectified flow)的解码器,能够从少量标记中重建出高质量的图像。
- 适应性强:适用于多种图像生成任务,包括类别条件生成和文本条件生成。
工作原理
FlexTok 的工作原理可以分为以下几个关键步骤:
- 编码阶段:
- 使用一个基于 Vision Transformer(ViT)的编码器,将二维图像分割成小块(patches),并将其映射到一维标记序列。
- 使用有限标量量化(FSQ)技术将连续的标记离散化。
- 通过嵌套丢弃(nested dropout)和因果注意力掩码(causal attention masks)引入标记的顺序性,使标记从粗到细地表示图像内容。
- 解码阶段:
- 使用修正流模型作为解码器,将离散标记序列解码为图像。
- 修正流模型通过预测噪声流来逐步重建图像,能够在极端压缩率下保持高质量的重建效果。
- 自回归生成:
- 训练一个自回归 Transformer 模型,根据条件(如类别标签或文本描述)逐步生成标记序列。
- 生成的标记序列通过解码器重建为最终的图像。
应用场景
FlexTok 可以应用于以下具体场景:
- 图像生成:
- 类别条件生成:根据给定的类别标签生成图像。例如,生成“金毛猎犬”或“火山”的图像。
- 文本条件生成:根据详细的文本描述生成图像。例如,根据“一只蓝色保时捷356停在黄色砖墙前”的描述生成图像。
- 图像压缩:
- 通过将图像编码为少量标记,实现高效的图像压缩,适用于存储和传输。
- 多模态任务:
- 结合文本和其他模态信息,生成与文本描述相符的图像,支持多模态预训练和生成任务。
- 视频生成:
- FlexTok 的灵活标记长度和层次化表示方法可以扩展到视频生成任务,通过逐帧生成标记序列来构建视频内容。
总结
FlexTok 通过灵活的标记长度和层次化表示,为图像生成和压缩提供了一种高效且适应性强的解决方案。它不仅能够根据图像复杂性动态调整标记数量,还能通过修正流解码器实现高质量的图像重建。FlexTok 在自回归图像生成任务中表现出色,适用于多种应用场景,包括图像生成、压缩和多模态任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











