
英伟达、麻省理工学院、清华大学、Playground和北京大学的研究团队推出了SANA模型的升级版SANA 1.5,这是一款高效的DiT架构模型,通过创新的训练和推理策略,实现文本到图像生成任务中的高效扩展。
- GitHub:https://github.com/NVlabs/Sana
- 模型:https://huggingface.co/collections/Efficient-Large-Model/sana-15-67d6803867cb21c230b780e4
- ComfyUI插件:https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels
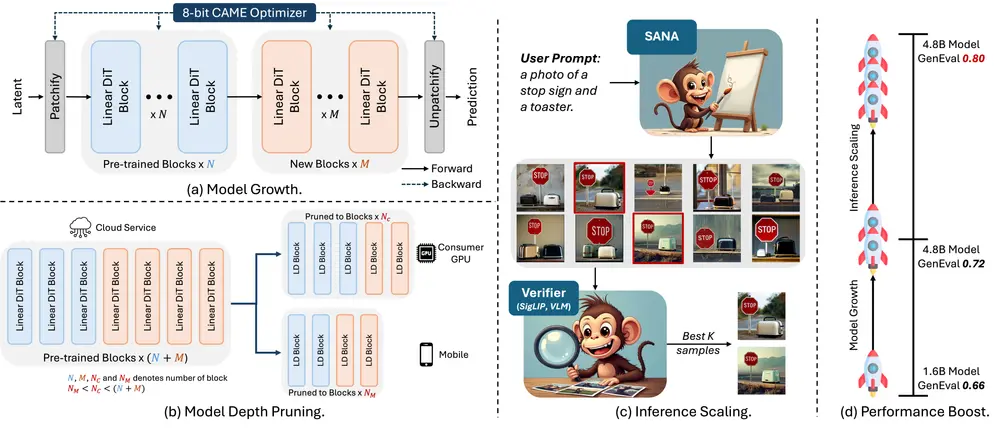
它在 SANA 1.0 的基础上引入了三项关键创新:高效的训练扩展策略、模型深度剪枝技术以及推理时扩展策略。这些创新使得 SANA 1.5 能够在不同的计算预算下实现高质量的图像生成,同时显著降低了训练和推理成本。

主要功能
- 高效的训练扩展:SANA 1.5 提出了一种深度增长范式,能够将模型从 16 亿参数扩展到 48 亿参数,同时显著减少计算资源需求。结合内存高效的 8 位优化器,该策略使训练时间减少了 60%。
- 模型深度剪枝:通过分析扩散变换器中输入输出的相似性模式,SANA 1.5 能够高效地压缩模型,将 60 层模型剪枝到不同配置(40 层、30 层、20 层),同时保持竞争力的生成质量。
- 推理时扩展:通过重复采样和基于视觉语言模型(VLM)的选择机制,SANA 1.5 能够在推理时通过计算资源换取模型容量,使较小模型的生成质量能够与较大模型相匹配。
主要特点
- 高效的模型扩展策略:SANA 1.5 通过部分保留初始化策略,保留预训练模型的知识,同时引入新层进行扩展。这种方法不仅减少了训练时间,还提高了模型的最终性能。
- 内存高效的优化器:CAME-8bit 优化器通过块量化技术,将优化器的内存占用减少到 AdamW 的 1/8,使得在消费级 GPU 上训练数十亿参数的模型成为可能。
- 灵活的模型部署:通过模型深度剪枝,SANA 1.5 能够灵活调整模型大小,以适应不同的计算预算,同时保持高质量的生成结果。
- 推理时质量提升:通过重复采样和 VLM 选择机制,SANA 1.5 在推理时能够显著提升生成质量,甚至超过传统意义上更大的模型。
工作原理
- 高效的训练扩展:SANA 1.5 通过部分保留初始化策略,将预训练的 20 层模型扩展到 60 层。新层通过随机初始化和身份映射初始化,确保训练的稳定性和效率。结合 CAME-8bit 优化器,该策略显著减少了训练时间和内存占用。
- 模型深度剪枝:通过分析扩散变换器中输入输出的相似性模式,SANA 1.5 确定并剪枝不重要的块。剪枝后,通过少量微调(如单 GPU 上的 100 步)恢复模型质量。
- 推理时扩展:SANA 1.5 在推理时通过重复采样生成多个样本,并使用 VLM 作为“裁判”选择与提示最匹配的图像。这种方法通过计算资源换取模型容量,显著提升了生成质量。
应用场景
- 高质量图像生成:SANA 1.5 能够生成高质量的图像,适用于广告、设计、内容创作等领域。例如,根据用户提供的文本描述生成逼真的图像。
- 多语言图像生成:通过多语言提示翻译和微调,SANA 1.5 支持多种语言的图像生成,适用于国际化的内容创作和本地化服务。
- 资源受限环境下的部署:通过模型剪枝和高效的优化器,SANA 1.5 能够在资源受限的设备(如移动设备或消费级 GPU)上高效运行,适用于边缘计算和实时应用。
- 推理时质量提升:在需要高质量生成但计算资源有限的情况下,SANA 1.5 的推理时扩展策略可以通过重复采样和 VLM 选择机制提升生成质量,适用于对生成质量要求较高的场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











