
在传统图像编辑中,若想修改照片中的某个物体(如移动人物、更换背景、调整颜色),往往需要复杂的抠图、蒙版或手动重绘——操作繁琐,且容易破坏整体一致性。
由香港科技大学(广州)、阿里巴巴与香港科技大学联合提出的 Qwen-Image-Layered,提供了一种根本性新思路:让AI在生成或解析图像时,直接输出多个语义解耦的 RGBA 图层,每个图层包含独立的颜色(RGB)与透明度(Alpha)信息。
- 模型:https://modelscope.cn/models/Qwen/Qwen-Image-Layered
- Demo:https://modelscope.cn/studios/Qwen/Qwen-Image-Layered
这意味着,每张图像天生就是“分层”的,可像 Photoshop 文件一样被精准、无干扰地编辑。
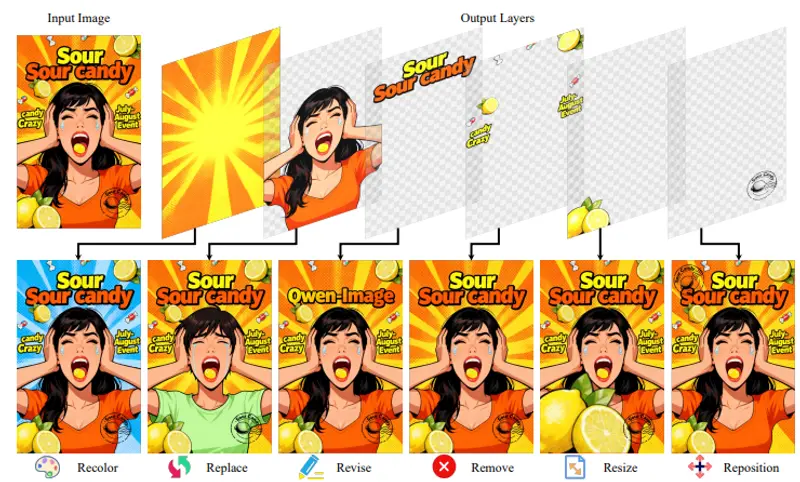
核心突破:从“像素图”到“可编程图层”
Qwen-Image-Layered 是一个端到端的扩散模型,其核心能力是将单张 RGB 输入图像自动分解为多个高质量 RGBA 图层,例如:
- 人物主体(含透明背景)
- 背景建筑
- 前景道具
- 阴影与光照层
每个图层彼此独立,支持单独调整位置、缩放、旋转、重新着色,而不会影响其他内容——从根本上避免了传统编辑中的语义漂移(如改色导致边缘模糊)或几何错位(如移动后出现空洞或重叠)。
✅ 关键优势:编辑一致性高、操作自由度大、无需人工标注或交互式分割。

技术实现:三层创新架构
1. RGBA-VAE:统一编码 RGB 与 RGBA
通过扩展传统 VAE 的通道结构,使其能同时处理输入 RGB 图像与输出多 RGBA 图层,显著缩小潜在空间分布差距,提升重建保真度。
2. VLD-MMDiT:可变层数的多模态解耦
提出 Variable Layers Decomposition MMDiT 架构,支持动态输出不同数量的图层,并通过多模态注意力机制建模层内细节与层间关系,确保语义与几何结构正确分离。
3. 多阶段渐进训练
训练过程分四阶段递进:
- 文本 → RGB 图像(基础生成)
- 文本 → 单 RGBA 图像(引入透明度)
- 文本 → 多 RGBA 图像(多图层生成)
- 图像 → 多 RGBA 图像(图层分解)
该策略使模型在迁移至复杂分解任务时更稳定、泛化更强。
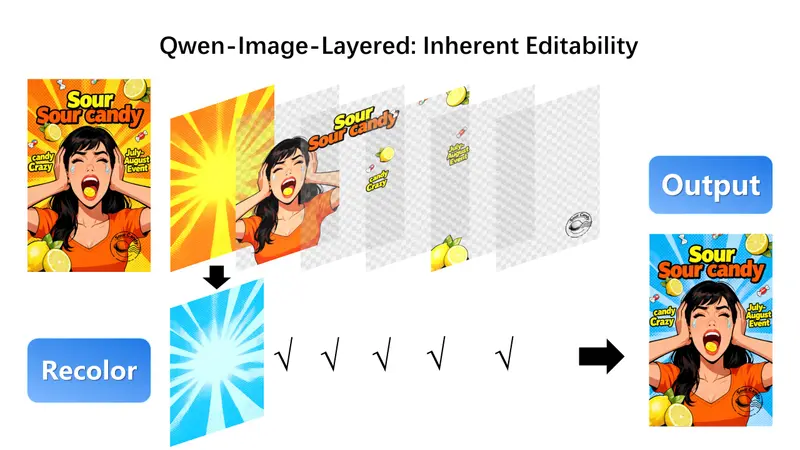
性能表现:全面超越现有方法
📊 定量评估
| 数据集 | 指标 | Qwen-Image-Layered | 之前最优 |
|---|---|---|---|
| Crello | RGB L1 ↓ | 0.021 | 0.028 |
| Crello | Alpha soft IoU ↑ | 0.892 | 0.831 |
| AIM-500 | PSNR / SSIM / rFID / LPIPS | 全指标最优 | — |
🖼️ 编辑一致性测试
在“移动人物”“缩放物体”“全局重着色”等任务中,Qwen-Image-Layered 显著优于 Qwen-Image-Edit-2509 等对比方法,无像素偏移、无边缘伪影、无内容断裂。
应用场景:从创意设计到动画制作
- 图形设计:快速生成海报、广告素材,各元素独立可调;
- 电商修图:一键分离商品与背景,批量换色或调整布局;
- 动画制作:将角色、道具、背景分层输出,便于逐帧动画控制;
- AI内容创作:基于文本生成多图层图像(如“一个穿红衣的女孩站在雪山前”),直接用于后期合成;
- 教育与科研:可视化图像结构,辅助计算机视觉教学或图像理解研究。
局限与未来
- 当前模型对高度重叠或透明物体(如玻璃、烟雾)的分层仍具挑战;
- 图层数量由模型自动决定,暂不支持用户指定;
- 未来或可结合用户交互提示(如框选区域)实现更精细控制。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











