
CLIP(对比语言-图像预训练)是 OpenAI 开发的一种多模态模型,通过对比学习在大量图像-文本对上训练,将图像和文本嵌入到同一个共享空间中,便于零样本任务。然而,CLIP 在处理全局信息时存在一个关键问题:它倾向于将全局信息存储在局部视觉补丁中,导致热图误导性强,影响某些任务的性能。

为了解决这一问题,开发者zer0int提出了一种新的架构改进方案 CLIP-fine-tune-registers-gated。通过添加寄存器令牌和门控机制,该项目显著降低了 CLIP 的模式差距(从 0.8276 降至 0.4740),并提升了模型在多模态任务中的表现。
- GitHub:https://github.com/zer0int/CLIP-fine-tune-registers-gated
- 模型:https://huggingface.co/zer0int/CLIP-Registers-Gated_MLP-ViT-L-14
- 模型备份:https://www.123865.com/s/hyQyTd-auhDv 提取码:afBJ
技术细节与改进
项目基于 OpenAI 的 ViT-L/14 模型(视觉变换器,大型,补丁大小 14),进行了以下关键修改:
- 寄存器令牌
添加了 4 个寄存器令牌,用于捕获全局信息,从而减轻局部补丁的负担。这些寄存器令牌的范数远大于普通补丁令牌(普通补丁范数通常 <80,而寄存器令牌 >100),能够有效区分全局和局部信息。 - 门控机制
在每层加入了带 ReLU 激活的 MLP,作为门控机制,控制信息流。这允许模型选择性地整合来自不同来源的信息。 - 最终融合 MLP
在模型输出前加入一个融合 MLP,整合寄存器令牌和补丁令牌的特征。
这些改进使总参数量从约 4.3 亿增加到 4.5 亿,但性能提升显著。

性能提升
项目提供了详细的性能指标,比较了修改后的模型(REG-XGATED)与原版 CLIP(ViT-L/14 OpenAI)在多个任务上的表现。以下是关键结果:
| 任务 / 数据集 | 指标 | ViT-L/14 OpenAI | X-GATED (ckpt20 xtreme) | X-GATED (ckpt12 balanced) | X-GATED (ckpt12 balanced, ablated) |
|---|---|---|---|---|---|
| VoC-2007 (多标签) | mAP | 0.7615 | 0.8140 | 0.8471 | 0.8247 |
| MSCOCO 检索 | 图像 Recall@5 | 0.2194 | 0.3565 | 0.3532 | 0.3349 |
| 文本 Recall@5 | 0.3034 | 0.5425 | 0.5278 | 0.5086 | |
| 线性探针 CIFAR-10 | Acc@1 | 0.9535 | 0.9813 | 0.9813 | 0.9811 |
| Acc@5 | 0.9966 | 0.9997 | 0.9997 | 0.9997 | |
| MVT ImageNet/ObjectNet (零样本) | 准确率 | 0.8453 | 0.8686 | 0.8830 | 0.8815 |
| 线性探针 ILSVRC2012 | Top-1 | 69.86% | 66.43% | 67.10% | 68.99% |
| Top-5 | 92.70% | 91.52% | 91.83% | 92.64% | |
| 模式差距指标 | 欧几里得差距 ↓ | 0.8276 | 0.4740 | 0.5395 | 0.7486 |
从表中可以看出,REG-XGATED 模型在多标签分类、图像-文本检索和零样本分类任务上表现优于原版 CLIP,尤其是在模式差距指标上显著改善。然而,在 ILSVRC2012 的线性探针任务上,Top-1 准确性略有下降,这可能是由于模型在某些特定任务上对局部特征的依赖减少。
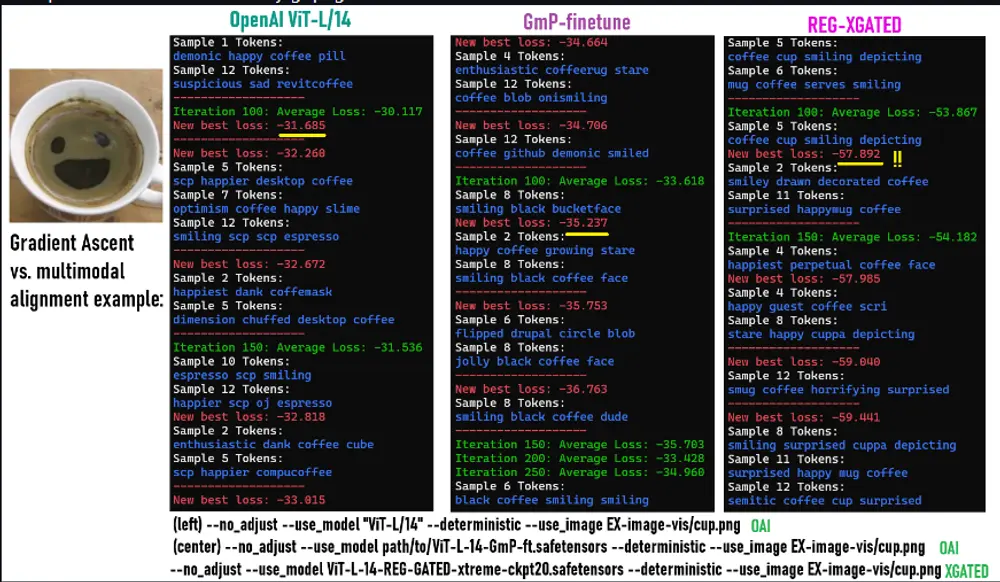
模式差距的意义
模式差距(modality gap)衡量图像和文本嵌入分布的差异。较低的模式差距意味着两种模态的表示更一致,有助于提升零样本学习和跨模态检索的性能。项目报告的欧几里得差距从 0.8276 降至 0.4740(ckpt20),JSD 和瓦瑟斯坦距离也有显著降低,表明改进方案非常有效。
实用资源与应用
项目提供了两个检查点(checkpoint)的文本编码器下载:
- 推荐平衡版本 ckpt12:ViT-L-14-REG-TE-only-balanced-HF-format-ckpt12
- 更低模式差距 ckpt20:ViT-L-14-REG-TE-only-xtreme-HF-format-ckpt20
这些文本编码器可以直接用于文本到图像/视频的 AI 应用,用户还可以使用项目提供的工具自定义细调模型,从初始寄存器令牌设置开始。
兼容性与局限性
需要注意的是,全模型不完全兼容 Hugging Face Transformers 库,建议使用 OpenAI 的 import clip 结构。文本编码器则为标准 CLIP 文本编码器,易于集成。
尽管性能在大多数任务上提升,但在线性探针任务(如 ILSVRC2012)上略有下降。这可能反映了模型在某些特定任务上的权衡,值得用户在选择时考虑。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











