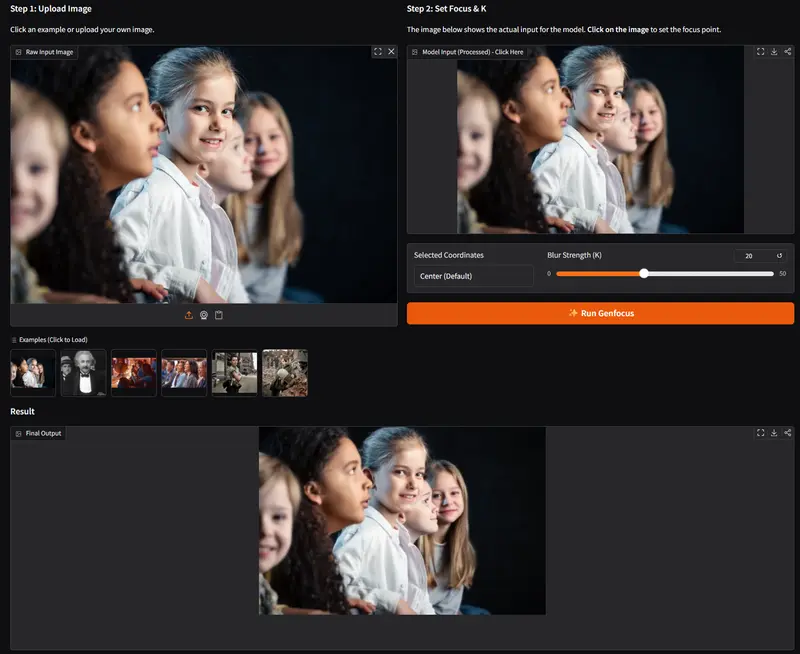
Generative Refocusing 是一种基于单张输入图像的生成式重聚焦方法,能够将任意照片转化为一个“虚拟相机”,在拍摄后灵活调整焦点位置、焦外虚化强度、光圈形状等光学属性。该方法不仅支持从模糊图像中恢复全焦点内容,还能合成高度逼真的定制化 bokeh 效果,为摄影后期与创意成像提供强大工具。
- 项目主页:https://generative-refocusing.github.io
- GitHub:https://github.com/rayray9999/Genfocus
- 模型:https://huggingface.co/nycu-cplab/Genfocus-Model
- Demo:https://huggingface.co/spaces/nycu-cplab/Genfocus-Demo
核心能力
- 散焦去模糊(Defocus Deblurring)
从部分模糊的输入图像中恢复出高质量的全焦点(all-in-focus)图像,无需原始多帧或全清晰参考图。 - 焦外虚化合成(Bokeh Synthesis)
基于用户指定的焦点平面、虚化强度(f-number)与光圈形状,生成物理合理的景深效果。 - 焦点重定位(Refocus Control)
允许将焦点从图像中任意区域(如背景)移至目标主体(如人物),实现“拍后对焦”。 - 光圈形状自定义
支持心形、星形、多边形等非圆形光圈,生成具有艺术风格的虚化高光。 - 文本引导修复(Text-Guided Recovery)
针对严重模糊的文本区域,通过文本提示引导模型精准恢复可读内容。
技术创新
🧩 两阶段生成架构
- 阶段一:DeblurNet(去模糊网络)
以模糊图像为输入,通过扩散模型引导的重建机制生成全焦点图像。
引入 位置解耦(position disentanglement) 与 预去模糊丢弃(pre-deblur dropping) 策略,有效抑制伪影传播。 - 阶段二:BokehNet(虚化合成网络)
以全焦点图像 + 深度图 + 用户参数为条件,合成最终输出。
支持通过光圈形状示例图进行条件控制,实现形状精确映射。
📊 半监督训练策略
- 合成数据预训练:使用光学模型生成配对数据(模糊↔全焦)
- 真实数据微调:利用带 EXIF 元数据的真实虚化图像(如 DPDD、REALDOF),学习真实镜头的散焦特性
- 避免纯仿真带来的“域偏移”问题,显著提升真实场景泛化能力
🔄 灵活输入假设
- 不依赖全焦点输入:可处理任意散焦状态的图像(全模糊、部分清晰、多焦点等)
- 无需深度传感器:深度图由内部模块估计或从单图推断
实验结果
| 任务 | 数据集 | 优势 |
|---|---|---|
| 去模糊 | DPDD, REALDOF | 在 PSNR、LPIPS、NIQE 等指标上超越 SOTA,细节恢复更自然 |
| 虚化合成 | LF-BOKEH | LPIPS ↓、DISTS ↓、CLIP-IQA ↑,生成结果更接近真实光学虚化 |
| 重聚焦 | LF-REFOCUS | 相比传统“去模糊 + 虚化”流水线,端到端性能提升显著,焦点过渡更平滑 |
应用场景
- 摄影后期:修正对焦失误,无需重拍即可重设焦点
- 创意成像:通过自定义光圈形状打造独特视觉风格(如婚礼照用心形 bokeh)
- 视频制作:对关键帧进行动态焦点调整,实现电影级景深过渡
- AR/VR:根据用户视线实时调整虚拟场景的焦点与虚化,增强沉浸感
- 文档增强:恢复模糊文本(如老照片中的文字、低清扫描件)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











