
Physion Labs 正式推出了 Galileo-0,这是首个专为世界模型(World Models)设计的自动化评判器。它不再仅仅给生成视频打一个模糊的分数,而是通过结构化的时空推理,精准诊断视频中出现的物理故障:什么错了、何时开始、在哪里发生,以及为什么违反物理规则。
- 官方介绍:https://physionlabs.ai/blog/galileo-0
这一突破旨在解决当前视频生成领域的一个核心矛盾:视觉上越来越逼真,但物理上却漏洞百出。
背景:视觉欺骗 vs. 物理真相
在 Physion Labs 之前的研究(Physion-Eval)中,团队提出了一个尖锐的问题:随着视频生成器在视觉上变得令人信服,它们是否也成为了更好的物理世界模型?
答案是否定的。
对五个最先进模型(包括 Sora, Kling, Veo 等)的测试显示:
- 83.3% 的外部视角视频包含至少一个人眼可识别的物理故障。
- 93.5% 的第一人称视角视频存在物理瑕疵。
这些故障包括物体突然消失、穿模、重力异常、手部结构错误等。为了系统性地解决这一问题,团队构建了包含 10,990 条专家推理轨迹 的基准测试,涵盖 22 个细粒度物理类别,每条数据都附带精确的时间戳、结构化标签和自然语言解释。
为什么我们需要“世界评判器”?
现有的评估方法主要依赖标量偏好分数(即“哪个视频更好看”),但这对于训练世界模型远远不够:
- 缺乏诊断信息:一个分数无法告诉模型哪里出了问题,无法指导模型进行针对性优化。
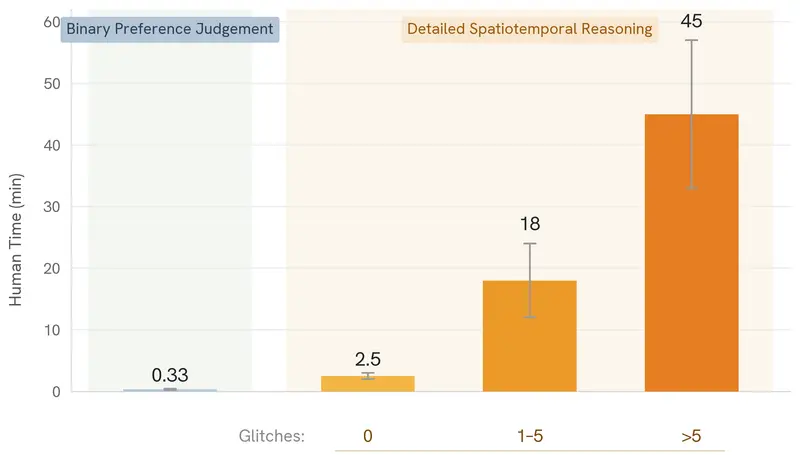
- 人类评判不可扩展:
- 人类专家进行细粒度时空标注极其耗时。
- 判断一个无故障视频需 2.5 分钟;含 1-5 个故障的视频需 18 分钟;复杂案例甚至超过 45 分钟。
- 未经训练的普通人往往无法发现或准确描述细微的物理违规。
Galileo-0 的目标:以自动化的方式,重现人类专家的结构化诊断能力,为模型提供高密度的对齐信号(Alignment Signal)和迭代优化依据。
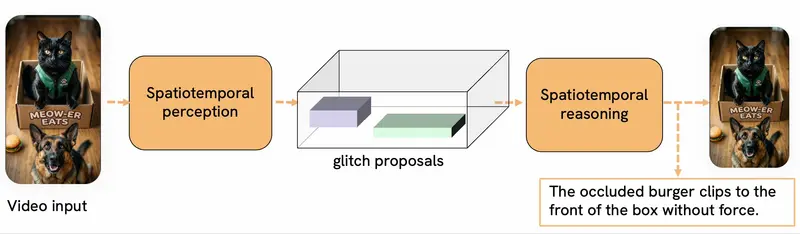
核心架构:两阶段时空推理流程
Galileo-0 的设计灵感来源于目标检测和时序动作定位(如 Fast R-CNN),采用独特的两阶段流程:
第一阶段:时空感知 (Spatio-Temporal Perception)
- 任务:提出故障候选区域(Proposals)。
- 机制:模型扫描整个视频,在空间和时间维度上锁定可能出现物理不一致的“可疑片段”。这将搜索范围从全视频缩小到具体的事件窗口。
第二阶段:时空推理 (Spatio-Temporal Reasoning)
- 任务:深度验证与诊断。
- 机制:对每个候选区域进行精细化分析。模型结合上下文,推理所提出的区域是否真的违反了物理预期。
- 例如:猫消失在遮挡物后 $\rightarrow$ 合理(非故障)。
- 例如:车轮旋转但车身静止 $\rightarrow$ 违规(物理故障)。
- 输出:生成详细的自然语言解释、精确的时间段和空间位置。
训练数据:利用专有的多模态大语言模型,以 10,990 条人类专家推理轨迹 作为监督信号进行训练。
性能表现:碾压通用多模态模型
在提出的故障级别微观 F1 指标下,Galileo-0 展现了压倒性的优势。测试涵盖了 Veo3, Kling, Sora2, Wan2.6, Seedance 等生成的视频。
| 模型 | 整体 F1 | 文本相关故障 F1 | 物体相关故障 F1 |
|---|---|---|---|
| Galileo-0 | 63.26% | 84.10% | 37.17% |
| GPT-5.4 | 38.89% | 53.20% | - |
| Gemini 3.1 Pro | 36.48% | - | - |
| Qwen3.5-Plus | 35.15% | - | - |
| GLM-5V Turbo | 25.42% | - | - |
| Pegasus 1.2 | 3.40% | - | - |
关键洞察:
- 全面领先:Galileo-0 在所有设置中均取得最高 F1 分数,特别是在文本一致性检测上,比最强的基线(GPT-5.4)高出 30 个百分点。
- 局部定位能力:Galileo-0 能够精准定位到极小的空间区域(如一个单词、一只手、斧头头部)和短暂的时间窗口,这是通用多模态大模型(MLLMs)难以做到的。
- 挑战犹存:物体相关故障(如物体消失、结构错误)由于变化多样且微妙,检测难度依然较大(F1 37.17%),这也是未来迭代的重点。
意义与未来:从“看起来像”到“动起来对”
Galileo-0 不仅仅是一个评估工具,它是下一代视频生成工作流的核心组件:
- 强化学习对齐 (RLHF for Video):提供结构化的奖励信号,引导模型不仅优化像素分布,更优化物理合理性。
- 推理时优化 (Inference-time Optimization):在生成过程中,利用 Galileo-0 的反馈进行迭代修正(类似智能体式的图像精炼),实时纠正物理错误。
- 可扩展的基准测试:摆脱了对昂贵人工标注的依赖,使得大规模、高频次的模型评估成为可能。
未来展望:
- 更广泛的故障覆盖:从当前的四大类(物体存在性、属性漂移、结构不一致、文本不一致)扩展到更多复杂的物理交互场景。
- 自定义物理规则:支持非现实世界的物理逻辑(如游戏世界、科幻场景),让评判器适应不同的“世界设定”。
- 长程推理:提升对长时间跨度、因果链条复杂的故障的检测能力。
Galileo-0 标志着视频 AI 从“视觉生成”迈向了真正的“世界模拟”。 只有当模型不仅能画出逼真的画面,还能理解并遵循物理定律时,我们才拥有了真正的世界模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











