
在视觉AI领域,能够真正适配现实世界创意工作流的工具,往往比单纯的“演示级模型”更具价值。近日,黑森林实验室正式推出新一代视觉智能系统 FLUX.2,不仅在图像生成质量、细节还原度上实现突破,更以多参考一致性、精准文本渲染、开放权重等核心优势,重新定义了视觉AI在创意生产中的应用边界。
- 官方地址:https://playground.bfl.ai
- GitHub:https://github.com/black-forest-labs/flux2
- 模型:https://huggingface.co/black-forest-labs/FLUX.2-dev

开放核心战略:让视觉智能惠及更多创作者
黑森林实验室自2024年成立以来,始终坚持“开放核心”理念——相信视觉智能不应被少数机构垄断,而应由全球研究人员、创意人士和开发者共同塑造。这一理念贯穿于 FLUX 系列的迭代:
- 既推出面向普通用户和开发者的 开放权重模型(如 FLUX.1 [dev],全球最受欢迎的开放图像模型),降低技术使用门槛;
- 也提供满足企业级需求的 生产就绪端点(如 FLUX.1 Kontext [pro]),为 Adobe、Meta 等公司的创意工作流提供动力。
这种“开放+专业”并行的模式,既驱动了社区实验与技术审查,又通过商业化支撑持续创新,让来自黑森林和湾区的前沿技术能够持续惠及全球用户。

从 FLUX.1 到 FLUX.2:不止于升级,更是工作流革新
如果说 FLUX.1 证明了媒体模型作为“强大创意工具”的潜力,那么 FLUX.2 则真正实现了“前沿能力与生产工作流的深度融合”。通过重构生成逻辑、优化模型架构,FLUX.2 在 精确性、效率、控制力、真实感 四大维度实现全面升级,彻底改变了视觉AI的应用经济性。
其核心新增功能,精准命中了创意生产中的痛点:
- 多参考支持(最多10张图):解决了以往模型“单图生成强,多图一致弱”的问题,能够在多张参考图间保持角色、产品、风格的高度统一,适配系列化创作、品牌视觉一致性设计等场景;
- 极致图像真实感:细节更丰富、纹理更锐利、光照更稳定,完全满足产品拍摄、场景可视化等“类摄影”级别的需求,无需后期大量修图;
- 可靠文本渲染:复杂排版、信息图、表情包、UI原型等场景中,精细文本清晰可读,彻底告别以往模型“文本错乱、无法识别”的尴尬,让视觉AI能够直接产出可用的文字类设计;
- 增强的提示词遵循:能够精准理解复杂、结构化的指令,包括多部分构图要求、风格约束等,减少“生成结果与预期不符”的反复调试;
- 强化世界知识:基于现实世界的光照规律、空间逻辑和物理常识,生成的场景更连贯、行为更合理,避免出现“悬浮物体”“光照矛盾”等违和感;
- 更高分辨率与灵活比例:支持高达400万像素的图像编辑,同时适配多样的输入/输出比例,满足从社交媒体配图到大型海报的全场景需求。

FLUX.2 产品矩阵:覆盖从开源到商用的全场景需求
FLUX.2 推出了完整的模型家族,不同层级的产品精准匹配不同用户的需求,兼顾性能、控制力与成本:
| 模型版本 | 核心定位 | 关键特性 | 获取方式 |
|---|---|---|---|
| FLUX.2 [pro] | 尖端商用级模型 | 媲美闭源模型的图像质量,快速度、低成本,无需妥协 | BFL Playground、BFL API 及合作渠道 |
| FLUX.2 [flex] | 开发者可控型模型 | 可调节步骤数、引导尺度,擅长文本与精细细节渲染 | BFL Playground、BFL API 及合作渠道 |
| FLUX.2 [dev] | 开放权重旗舰模型(320亿参数) | 文生图+多图编辑一体,消费级GPU可运行 | Hugging Face 开放权重,支持本地部署;第三方API(FAL、Replicate等) |
| FLUX.2 [klein] | 轻量开源模型(即将推出) | Apache 2.0许可,尺寸小巧,开发者友好 | 测试版申请,后续将开源发布 |
| FLUX.2 - VAE | 基础潜在表示模型 | 优化“可学习性-质量-压缩”平衡 | Hugging Face (Apache 2.0许可) |
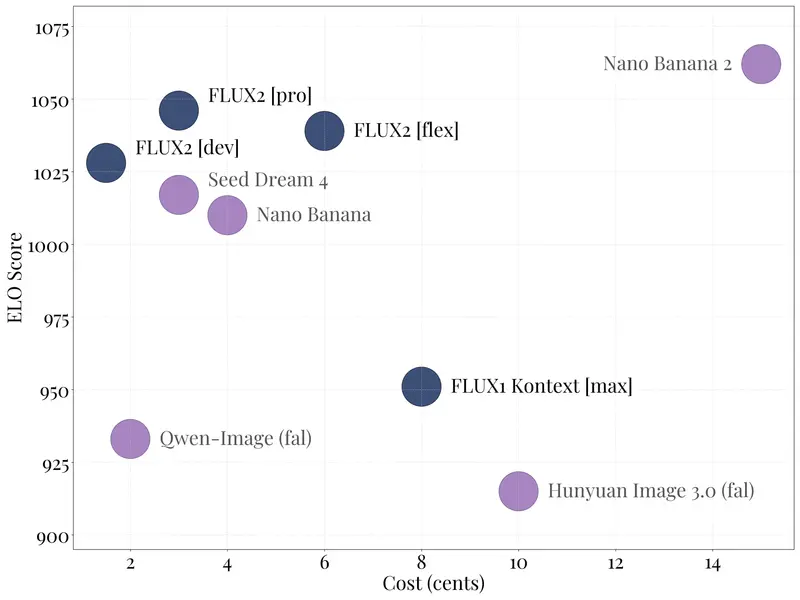
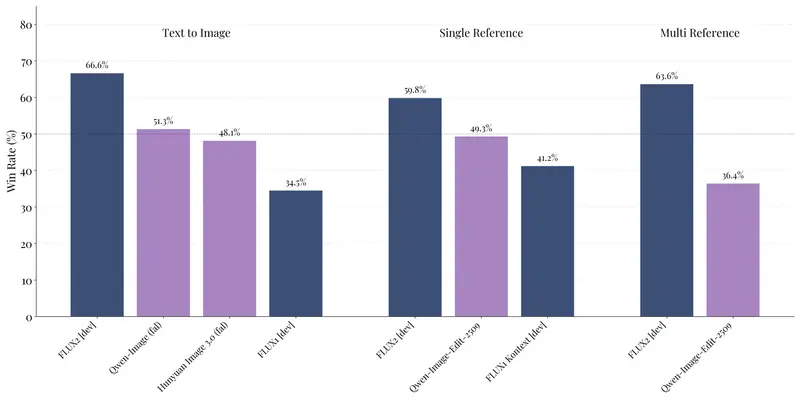
其中,FLUX.2 [dev] 作为当前最强大的开放权重图像生成与编辑模型,在文生图、单参考图编辑、多参考图编辑等核心场景中,显著超越同类开放模型,为开发者提供了“低成本、高能力”的技术底座;而 FLUX.2 [pro] 则通过“性能与成本的最优解”,成为企业级创意生产的首选工具。

技术内核:潜在流匹配架构的革新
FLUX.2 的强大性能,源于其创新的技术架构:
- 基于 潜在流匹配架构,在单一架构中同时实现图像生成与编辑,避免了多模块拼接带来的效率损耗;
- 耦合 Mistral-3 240亿参数视觉语言模型(VLM) 与 修正流Transformer:VLM 提供强大的现实世界知识和上下文理解能力,Transformer 则精准捕捉空间关系、材质属性和构图逻辑,解决了早期模型无法渲染复杂场景的痛点;
- 重新训练的 潜在空间:从根本上优化了“可学习性、图像质量、压缩率”的三重困境,为所有 FLUX.2 模型提供了更高效、更高质量的基础支持(技术细节可参考官方 VAE 博客)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











