
大语言模型(LLMs)凭借其在原生数据格式上训练的能力,能够高效处理可变长度文本。这种灵活的适应性启发我们思考一个关键问题:
扩散模型能否也具备类似的灵活性,在任意分辨率和宽高比下直接学习生成图像?
传统扩散模型在面对超出训练范围的分辨率时往往表现不佳,主要受限于以下三大挑战:
- 卷积架构中感受野与特征尺度的强耦合;
- Transformer 中位置编码对空间坐标的依赖性较强;
- 不同分辨率输入导致训练动态不稳定且效率低下。
为突破这些限制,来自香港中文大学与上海人工智能实验室的研究团队提出了一种全新的扩散模型架构 —— NiT(Native-resolution diffusion Transformer),首次实现了在任意分辨率和宽高比下高质量图像生成的能力。
- 项目主页:https://wzdthu.github.io/NiT
- GitHub:https://github.com/WZDTHU/NiT
- 模型:https://huggingface.co/GoodEnough/NiT-XL-Models

🎯 核心目标:原生分辨率图像合成(Native-Resolution Image Synthesis)
“原生分辨率图像合成”是一种新的图像生成范式,旨在摆脱传统固定分辨率和统一宽高比的限制,直接在原始尺寸上建模图像生成过程。
与以往将图像统一缩放至 256×256 或 512×512 不同,该方法支持从低到高、从正方到极端比例的多种图像尺寸生成,例如:
- 分辨率跨度:从 256×256 到 2048×2048
- 宽高比范围:从 1:5 到 3:1
这不仅提升了视觉质量,还显著减少了因图像裁剪或填充造成的语义丢失。
🔬 模型创新:NiT 的三大关键技术
NiT 在扩散模型基础上引入了三项关键架构改进,使其能够有效应对原生分辨率下的图像生成挑战:
✅ 1. 动态分词(Dynamic Tokenization)
将图像划分为不等长的小块,并转换为可变长度标记序列,同时记录其高度和宽度信息。
优势:
- 避免传统填充操作带来的冗余计算;
- 支持真正意义上的任意分辨率输入。
✅ 2. 可变长度序列处理
使用 FlashAttention-2 技术,结合累积序列长度和内存分块策略,原生支持异构、未填充的标记序列。
优势:
- 提升显存利用效率;
- 加快训练速度;
- 减少无效注意力计算。
✅ 3. 二维结构先验注入
引入轴向二维旋转位置嵌入(2D Rotary Positional Embedding, RoPE),分别建模高度和宽度方向的位置关系。
优势:
- 强化模型对二维空间结构的理解;
- 提高在不同分辨率下的泛化能力;
- 增强图像整体布局的一致性。
⚙️ 工作机制详解
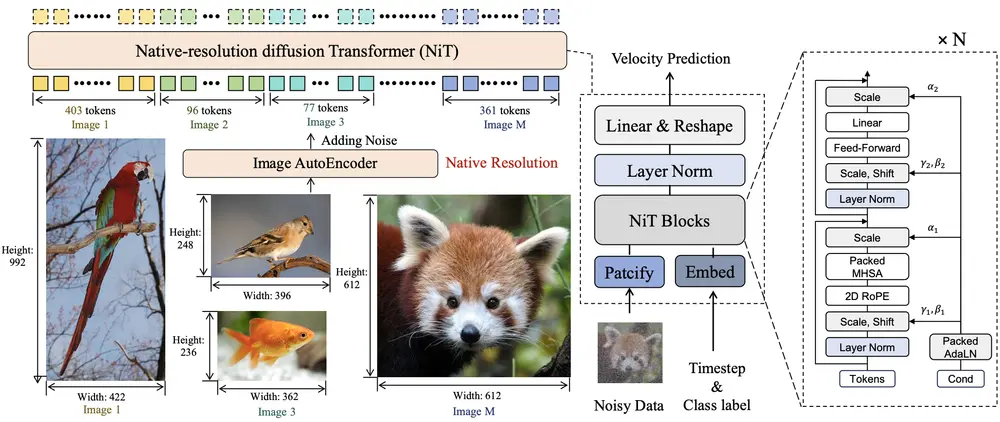
NiT 的核心流程包括以下几个关键步骤:
| 步骤 | 描述 |
|---|---|
| 1. 动态分词 | 将原生分辨率图像划分为小块并转化为可变长度标记序列 |
| 2. 注入结构先验 | 使用 2D RoPE 编码高度与宽度方向的相对位置信息 |
| 3. 序列注意力处理 | 利用 FlashAttention-2 处理打包的异构序列,避免显式掩码 |
| 4. 条件归一化 | 通过广播机制统一子序列的条件向量,确保归一化一致性 |
这一流程使得模型在不牺牲性能的前提下,能高效处理各种复杂输入。
📊 性能测试结果
NiT 在多个标准图像生成任务中展现出卓越性能:
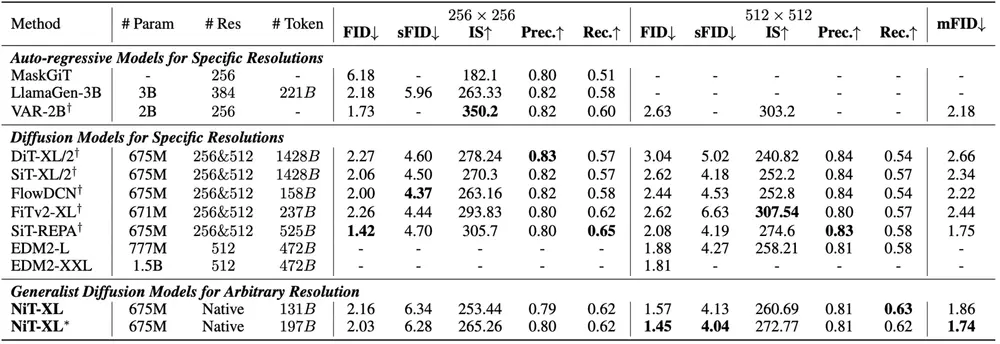
📈 标准分辨率测试(ImageNet)
| 分辨率 | FID Score |
|---|---|
| 256×256 | 2.03 |
| 512×512 | 1.45 |
📹 高分辨率泛化能力
| 分辨率 | FID Score |
|---|---|
| 1024×1024 | 4.52 |
| 1536×1536 | 6.51 |
| 2048×2048 | 24.76 |
📐 宽高比泛化能力
| 宽高比 | FID Score |
|---|---|
| 1:3 | 16.85 |
| 9:16 | 4.11 |
| 3:4 | 3.72 |
| 4:3 | 3.41 |
| 16:9 | 5.27 |
| 3:1 | 9.90 |
NiT 在各类指标上均优于现有方法,展现出强大的跨分辨率与跨宽高比泛化能力。
✅ 核心优势总结
| 特性 | 描述 |
|---|---|
| 任意分辨率生成 | 支持从低分辨率到超高清(如2K)的图像生成 |
| 宽高比灵活性 | 兼容从竖版短视频到横幅广告等多种格式需求 |
| 高质量图像合成 | 在标准基准测试中达到甚至超越当前最佳模型 |
| 原生分辨率处理 | 直接建模原始图像尺寸,减少信息损失 |
| 动态分词机制 | 避免填充,降低计算开销 |
| 结构先验注入 | 提升模型对空间结构的理解与生成稳定性 |
| 高效注意力机制 | 利用 FlashAttention 实现快速、低资源消耗推理 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











