
今日,字节跳动 Seed 团队正式发布了新一代图像编辑模型 SeedEdit 3.0。该模型基于文生图模型 Seedream 3.0,融合多样化的训练数据与奖励机制,在图像主体与背景一致性、指令理解能力等方面实现大幅提升,显著提高了图像编辑的可用性。
目前,SeedEdit 3.0 已在 即梦网页端 开启测试,后续将在 豆包 App 上线,为更多用户提供 AI 辅助图像编辑服务。

图像编辑痛点与 SeedEdit 3.0 的突破
图像编辑是视觉创意工作中的高频需求。然而,传统图像编辑模型在“哪些部分需要修改、哪些应保留”这一问题上常常表现不佳,导致生成结果不够自然、可用性较低。
SeedEdit 3.0 针对这一问题进行了深度优化:
- 提升了图像主体、背景及细节的保持能力;
- 在人像编辑、背景替换、视角与光线转换等场景表现尤为出色;
- 可处理并生成 4K 分辨率图像,在精细编辑区域的同时,高保真地保留其他信息。
例如,当用户希望去除图片中的行人时,SeedEdit 3.0 不仅能准确识别并移除人物,还能同步清除其影子,实现更自然的图像修复效果。

技术亮点解析
1. 多源数据融合与元信息嵌入策略
为了提升模型的泛化能力与任务适配性,Seed 团队构建了一个增强的数据管理流程,包括:
- 收集来自多个来源的数据:合成数据集、专家输入、传统编辑算子输出、视频帧与短视频片段;
- 引入多粒度标签策略,整合数据级任务标签、文本级重字幕(text-level recaption)和像素级标记;
- 使用元信息范式与嵌入策略,将视觉语言模型(VLMs)与扩散模型(Diffusion)有效连接。
这些方法使得模型能够更好地理解和执行复杂的图像编辑指令。
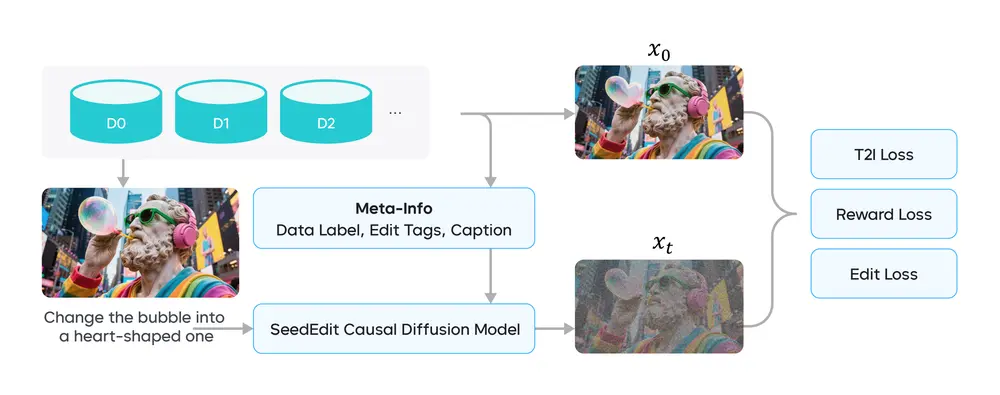
2. 联合学习流程优化
SeedEdit 3.0 引入了一种新的联合学习流程,结合扩散损失函数与奖励模型,进一步提升了模型在生成质量与编辑意图之间的平衡能力。
3. 模型架构设计
模型由两个核心组件构成:
| 组件 | 功能 |
|---|---|
| 视觉语言模型(VLM) | 推断图像高层语义信息 |
| 因果扩散网络(causal diffusion network) | 利用扩散过程作为图像编码器,捕捉图像细节 |
两者之间通过一个连接器模块进行信息对齐,确保编辑意图(如任务类型、标签信息)能被准确传递至扩散模型。
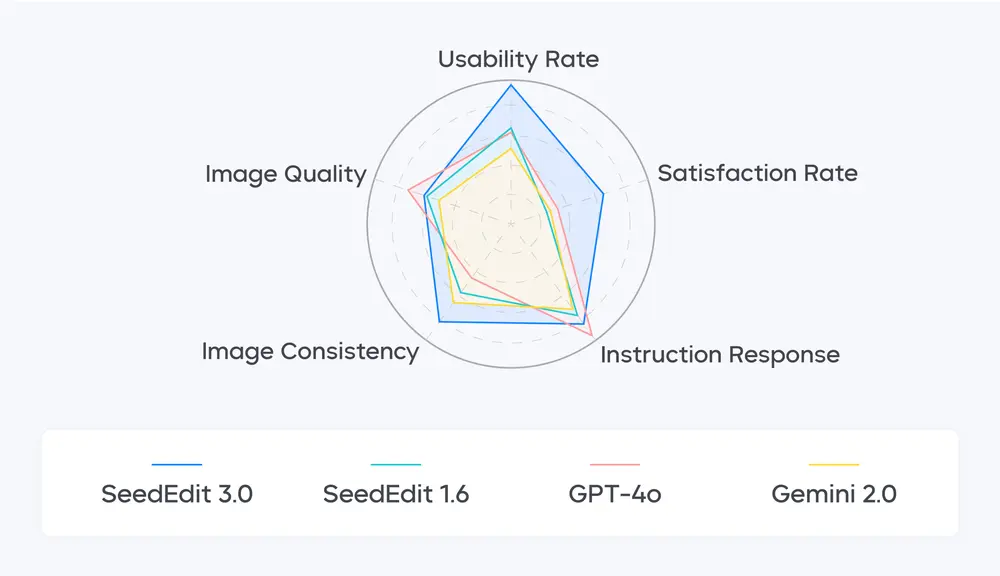
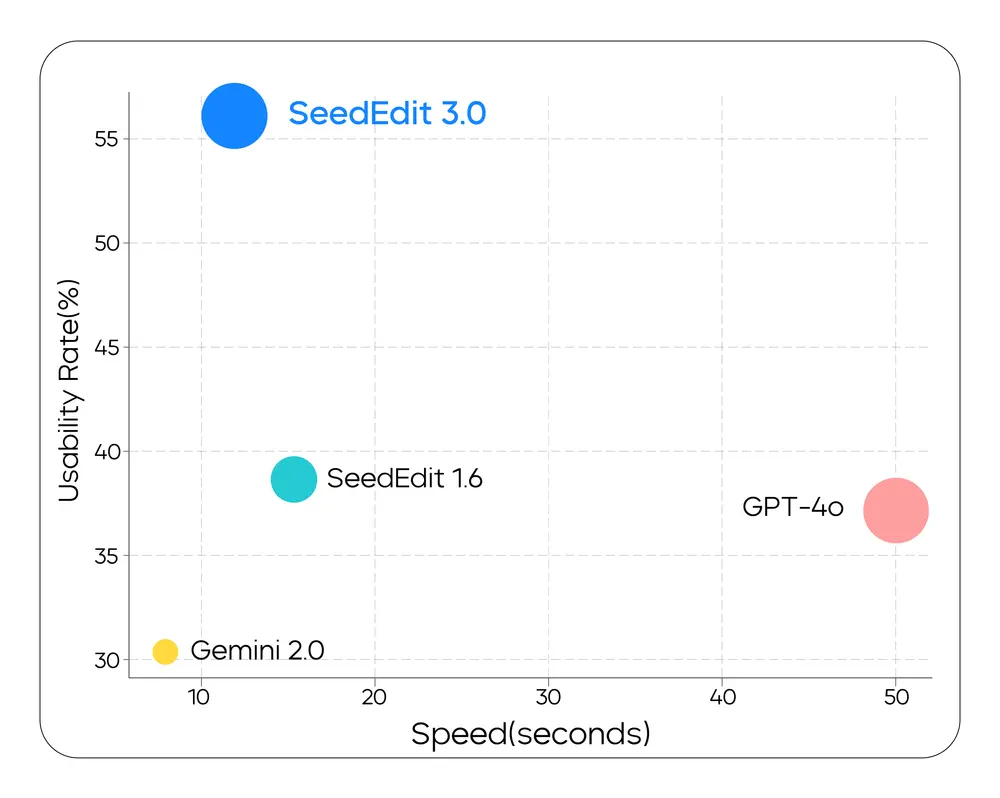
性能评估与对比
为了全面评估 SeedEdit 3.0 的表现,团队构建了一个包含数百张图像的挑战性测试集,涵盖真实照片与 AI 生成图像,并覆盖多种编辑操作:
- 常见操作:风格化、添加、替换、删除;
- 复杂操作:模拟相机移动、物体位移、场景变换等。
在该测试集上的表现表明:
- SeedEdit 3.0 在多项关键编辑指标间实现了最佳平衡;
- 相较于 SeedEdit 1.6、GPT-4o 和 Gemini 2.0 等模型,SeedEdit 3.0 在综合评分与实用性方面均表现最优。
未来规划
SeedEdit 3.0 是图像编辑领域的一次重要升级,但团队表示这只是一个开始。
未来,Seed 团队将继续推进以下方向:
- 进一步优化编辑性能,提升复杂场景下的稳定性;
- 探索更丰富的编辑功能,如:
- 连续多图生成
- 多张图像合成
- 故事性内容生成
- 构建更加完整的图像创作工具链,助力创作者高效完成视觉内容生产。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











