
北京大学深圳研究生院、鹏城实验室、兔展AI的研究人员推出统一视觉理解与生成框架UniWorld,它基于强大的视觉-语言模型和对比语义编码器,能够同时处理图像感知和图像操控任务。
- GitHub:https://github.com/PKU-YuanGroup/UniWorld-V1
- 模型:https://huggingface.co/LanguageBind/UniWorld-V1
- Demo:http://8.130.165.159:8800
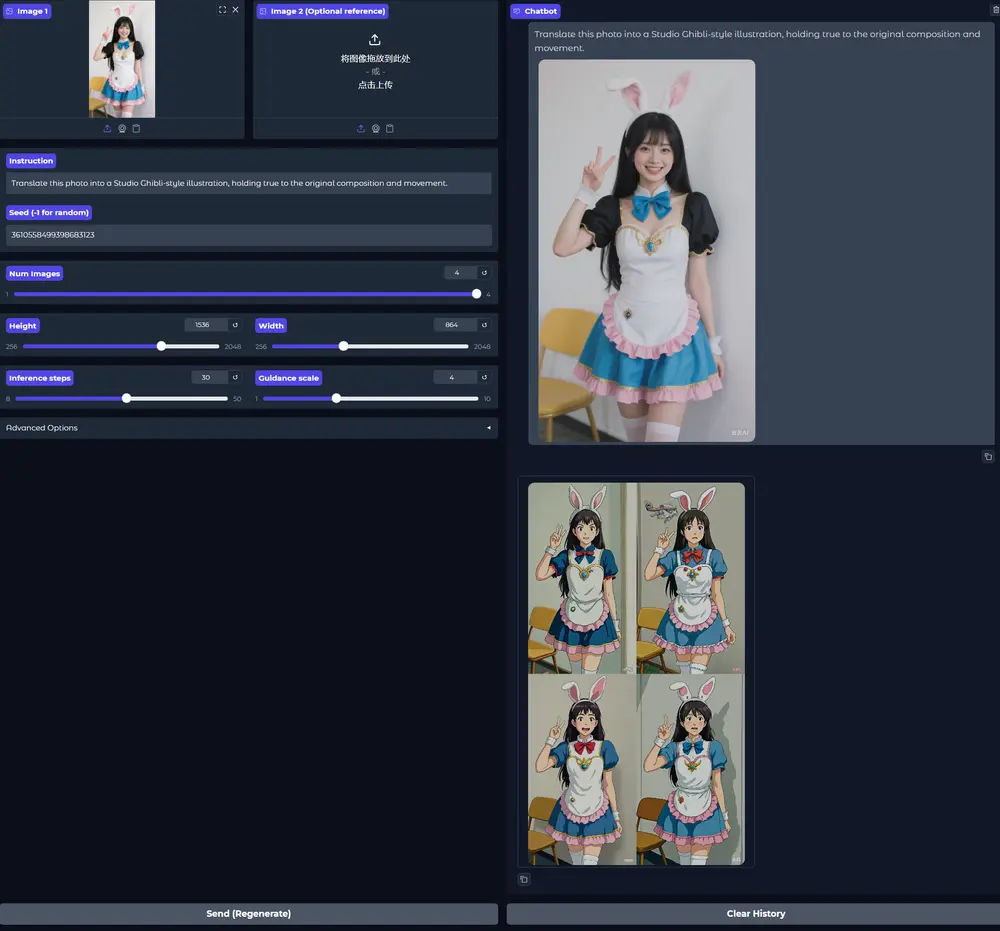
例如,UniWorld可以执行图像编辑任务,如添加、移除或替换图像中的元素,还能进行图像理解任务,如目标检测和分割。
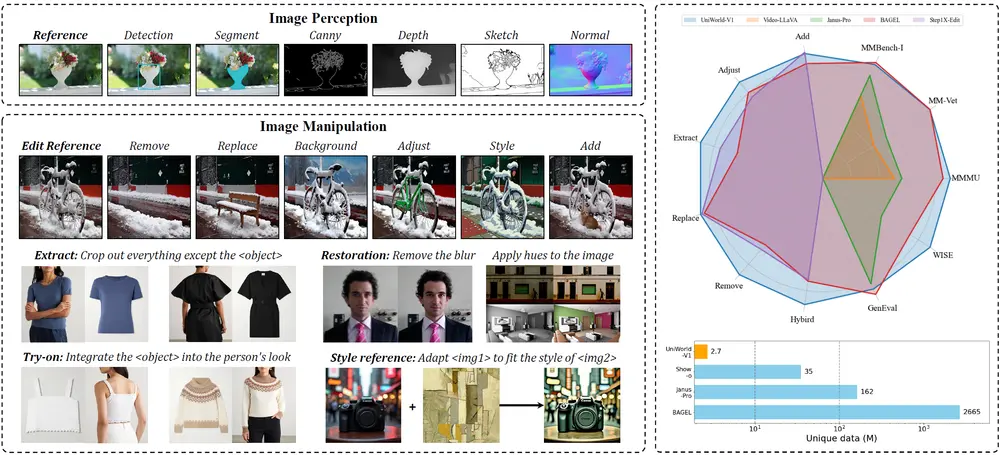
主要功能
- 图像感知:包括目标检测、分割、深度预测等任务,能够理解图像内容。
- 图像操控:支持图像编辑任务,如添加、调整、提取、替换、移除元素等,还能进行风格迁移和虚拟试穿。
- 文本到图像生成:根据文本描述生成相应的图像。
主要特点
- 高效性:仅使用2.7M训练样本,就达到了与使用2665M样本的BAGEL相当的性能。
- 多功能性:首次在一个模型中集成了图像理解、图像感知和图像操控能力。
- 开源性:模型权重、训练和评估脚本以及数据集全部开源,便于社区使用和进一步研究。
工作原理
UniWorld的工作原理基于以下关键部分:
- 语义编码器:使用SigLIP编码器提取图像的语义特征,这些特征既包含像素级别的局部信息,也包含语义级别的全局概念。
- 多模态大模型:利用预训练的Qwen2.5-VL-7B模型提供自回归理解标记,帮助模型理解文本和图像内容。
- 训练过程:分为两个阶段,第一阶段对语义特征进行对齐,第二阶段进行微调以实现一致的图像生成。
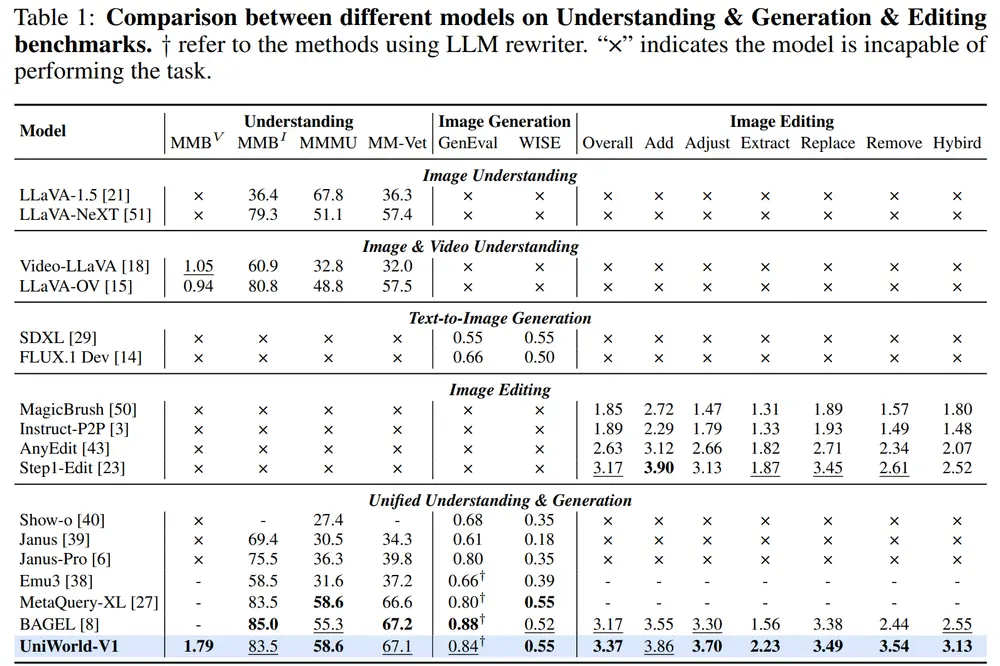
测试结果
- 文本到图像生成:在GenEval基准测试中,UniWorld-V1达到了0.80的总体分数,接近BAGEL的0.88,且在WISE基准测试中,其0.55的总体分数显示了强大的世界知识推理能力。
- 图像编辑:在ImgEdit-Bench基准测试中,UniWorld-V1的总得分为3.37,超过了其他开源模型,如Step1X-Edit(3.17)和BAGEL(3.17)。
- 视觉理解:在多个视觉理解基准测试中,UniWorld-V1的表现超过了Janus、Show-o和Emu3等模型,与BAGEL相当。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











