
字节跳动Seed研究团队发布了一项名为 VAPO 的强化学习训练框架。这一框架专为提升大语言模型(LLM)在复杂、冗长任务中的推理能力而设计,特别是在数学推理和长链推理(Long Chain-of-Thought, CoT)任务中表现突出。通过一系列技术创新,VAPO不仅解决了现有方法的关键挑战,还显著提升了模型的性能和稳定性。

为什么需要VAPO?
在大语言模型的强化学习训练中,基于价值的方法(Value-based,RL)因其能够精确追溯每个动作对后续回报的影响而备受关注。然而,在处理复杂的长链推理任务时,这种方法面临三大核心问题:
价值模型初始化偏差:初始阶段的价值估计可能不准确,导致优化过程偏离目标。 异构序列长度:不同任务的推理链条长度差异巨大,传统方法难以动态适应。 奖励信号稀疏性:复杂任务中的奖励信号稀少,增加了探索与利用之间的权衡难度。
这些问题限制了基于价值方法的实际效果,而VAPO正是为此而生。
VAPO的核心创新
VAPO基于经典的PPO(Proximal Policy Optimization)算法,并引入了三项关键改进,以应对上述挑战:
1. 细致的价值训练框架
VAPO构建了一个更加精细的价值训练机制,增强了模型对复杂任务的理解能力。通过预训练价值模型(Value-Pretraining),有效减少了初始化偏差,避免了训练崩溃的风险。
2. 长度自适应广义优势估计(GAE)
传统的GAE方法难以适应不同长度的推理链条。VAPO引入了长度自适应GAE,能够根据响应长度动态调整参数λ,从而在长短序列之间找到最佳的偏差-方差平衡点。
3. 集成多种技术协同增效
VAPO整合了多项前沿技术,包括:
Clip-Higher:通过剪裁策略鼓励探索,避免模型过早收敛。 Token-level Loss:增加对长回答的权重,确保复杂任务得到充分优化。 Positive Example LM Loss:通过正例语言模型损失提升模型的表现。 分组采样(Group-Sampling):提高样本多样性,增强模型的泛化能力。
这些技术通过消融研究验证了其必要性,共同构成了VAPO的强大功能。
VAPO的实际表现
1. 高效训练与稳定性
VAPO在训练过程中表现出色,仅需5000步即可达到最先进的性能水平。同时,其训练过程极为稳定,多次独立运行均未出现崩溃现象。
2. 显著的性能提升
测试结果显示,使用VAPO优化后的Qwen2.5-32B模型在AIME24基准测试中取得了60.4分的高分,远超此前的最佳方法DAPO(50分)和DeepSeek R1(47分)。此外,VAPO仅用60%的更新步骤便达到了业界领先水平。
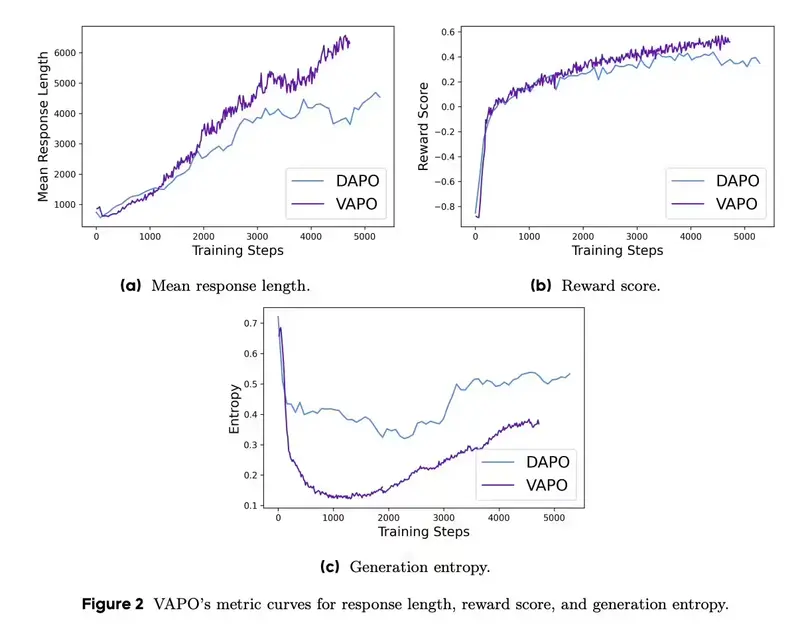
3. 长链推理优化
在长链推理任务中,VAPO通过系统设计有效解决了价值模型偏差、异构序列长度和奖励信号稀疏性等关键挑战,展现出卓越的性能。
工作原理解析
VAPO将语言生成任务建模为马尔可夫决策过程(MDP),并结合以下技术实现优化:
KL正则化强化学习目标
在最大化累积奖励的同时,通过KL散度正则化控制策略更新幅度,确保训练过程的稳定性。近端策略优化(PPO)
使用PPO算法更新策略,通过剪切目标函数限制策略更新幅度,防止训练过程中的不稳定行为。广义优势估计(GAE)
采用GAE技术更准确地估计优势函数,通过多步引导减少方差,提升优化效率。解决长链推理挑战 价值模型偏差:通过Value-Pretraining和Decoupled-GAE减少偏差。 异构序列长度:通过Length-Adaptive GAE动态调整参数λ。 奖励信号稀疏性:通过Clip-Higher、Positive Example LM Loss和Group-Sampling提高探索效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











