
在多模态 AI 应用日益普及的今天,如何高效检索混合了文本、图像、截图甚至视频的内容,仍是技术难点。传统方案往往依赖多个专用模型,导致系统复杂、语义割裂。
- 官方说明:https://qwen.ai/blog?id=qwen3-vl-embedding
- Qwen3-Embedding:https://huggingface.co/collections/Qwen/qwen3-embedding
- Qwen3-ReRanker:https://huggingface.co/collections/Qwen/qwen3-reranker
阿里通义实验室最新开源的 Qwen3-VL-Embedding 与 Qwen3-VL-Reranker 系列模型,首次在一个统一框架下,实现了跨模态语义对齐与高精度相关性排序,为构建下一代多模态搜索引擎、内容推荐系统和知识库问答提供了开箱即用的解决方案。
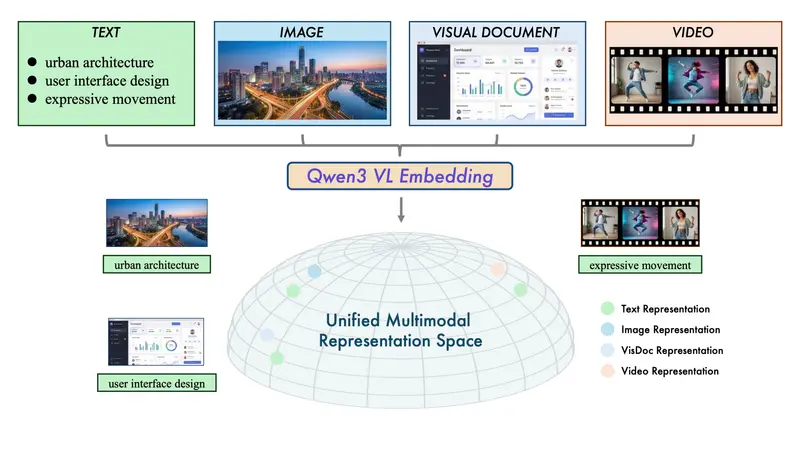
核心能力:一个框架,四种模态
两个模型系列均基于 Qwen3-VL 多模态基座,支持以下输入类型:
- 纯文本
- 单张图像或截图
- 视频(通过关键帧或时序建模)
- 文本+图像混合内容(如网页截图、带图文档)
💡 示例场景:
- 用户上传一张“商品截图”,系统返回相似商品(图像→图像)
- 用户输入“红色连衣裙”,返回匹配图片与视频(文本→图像/视频)
- 用户搜索“如何更换轮胎”,返回教学视频与图文指南(文本→多模态)
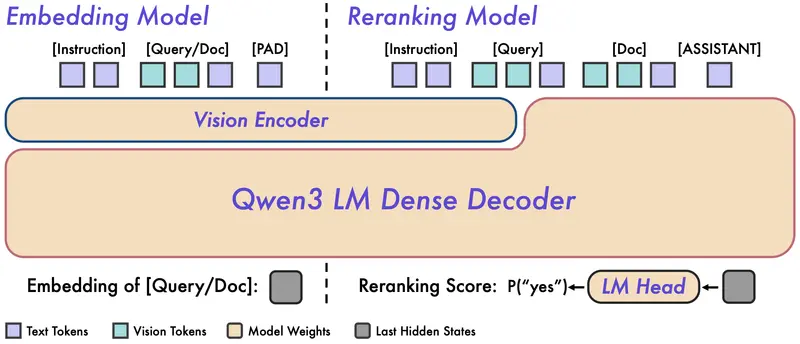
双模型协同:两阶段检索架构
系统采用工业界验证有效的 “召回 + 重排序” 两阶段流程:
- 召回阶段:Qwen3-VL-Embedding
- 双塔架构:Query 与 Document 独立编码,生成统一语义向量
- 输出维度可选(2B 模型 2048D,8B 模型 4096D),支持 MRL(多分辨率嵌入),允许运行时指定维度
- 支持向量量化,大幅降低存储与检索成本
- 支持指令感知,可通过提示词定制向量语义(如“聚焦颜色”“关注品牌”)
- 重排序阶段:Qwen3-VL-Reranker
- 单塔交叉注意力架构:对 (Query, Document) 对进行联合编码,深度交互
- 输出精细相关性分数(基于
yes/notoken 概率) - 同样支持混合模态输入对(如“文本查询 + 视频文档”)
📊 评测显示:8B Reranker 在 MMEB-v2 视觉文档检索(VisDoc)上达 86.3 分,显著优于 Embedding 单独使用(79.2)及其他开源 reranker。
技术亮点
- 统一语义空间:文本、图像、视频被映射到同一向量空间,支持任意模态间相似度计算
- 长上下文支持:最大序列长度 32K tokens,可处理长图文或视频描述
- 多语言能力:继承 Qwen3-VL 的 30+ 语言支持,适合全球化部署
- 高效部署:Embedding 模型支持量化,Reranker 可用于小批量高精度排序
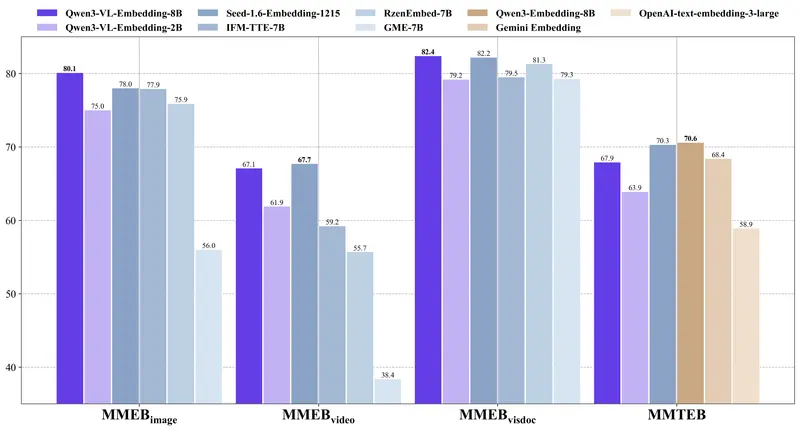
性能表现:多项 SOTA
- Qwen3-VL-Embedding-8B 在 MMEB-v2 多模态检索基准上全面领先,在图像、视频、视觉文档子任务均达 SOTA
- 在纯文本 MMTEB 基准上,虽略低于纯文本 Qwen3-Embedding(因多模态通用性权衡),但仍优于同等规模多模态模型
- Qwen3-VL-Reranker-8B 在 JinaVDR(视觉文档检索)和 ViDoRe v3 上显著超越基线,验证其跨模态交互能力
使用建议
- 快速部署:
- 对海量数据:用 Embedding 构建向量库(如 FAISS、Milvus)
- 对 Top-K 候选:用 Reranker 精排
- 成本优化:
- 使用 2B 模型 + 量化满足轻量场景
- 8B 模型用于高精度核心业务
- 场景定制:
- 通过指令微调或 prompt engineering 调整语义重心(如“电商场景强调商品属性”)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











