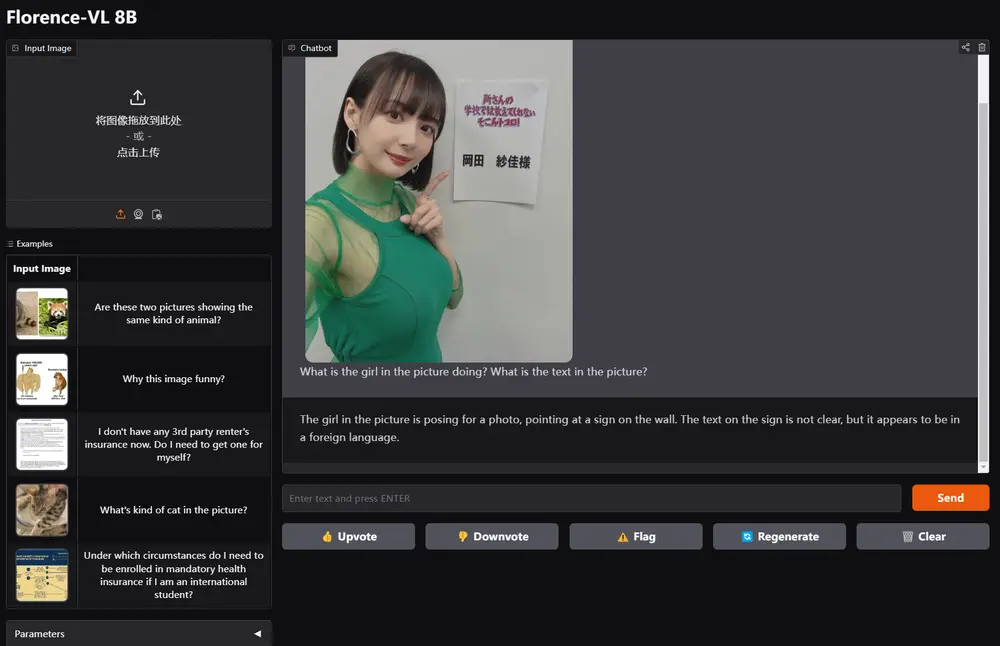
想象一下:你上传一张街景照片,或输入一句描述——“一个穿风衣的男人走在雨夜的东京街头,霓虹灯闪烁,远处有全息广告”——模型随即生成一个可自由行走、视角可调、事件可触发的动态 3D 世界。你用键盘控制角色前进、转向,甚至输入“突然出现一只黑猫”,世界便实时响应。
由 上海市人工智能实验室、复旦大学与上海创智学院 联合推出的 Yume1.5,是一款交互式虚拟世界生成模型,支持从单张图片或文本提示生成无限长度、高一致性、可实时交互的动态虚拟环境。其效果与李飞飞团队提出的“世界模型”(World Model)理念高度相似,但更强调用户控制与实时响应。

核心功能:不只是生成视频,而是构建可操作的世界
Yume1.5 超越了传统“图生视频”模型的局限,提供四类关键能力:
- 文本到世界(Text-to-World)
输入自然语言描述,生成完整虚拟场景。例如:“中世纪城堡庭院,士兵巡逻,鸽子飞过”。 - 图片到世界(Image-to-World)
上传一张静态图(如风景照、建筑渲染图),模型将其“激活”为动态世界,保留原图风格与布局。 - 事件编辑(Event Editing)
在生成过程中,通过新文本指令触发事件:“天开始下雨”、“一辆车驶入画面”、“出现一个幽灵”。 - 实时交互控制
用户通过键盘控制角色移动与相机视角,在生成世界中自由探索,实现“所想即所见,所控即所行”。
技术突破:如何实现高效、长时、可控的生成?
要生成一个无限长、高一致性、低延迟的交互式世界,需解决三大挑战:
- 历史帧累积导致计算爆炸
- 推理延迟过高,无法实时响应
- 文本指令难以精准控制动态内容
Yume1.5 通过两项核心技术应对:
✅ 联合时空通道建模(TSCM)
对历史生成帧进行时空压缩 + 通道压缩:
- 随机抽帧 + Patchify 降低分辨率与帧率
- 通过线性注意力融合压缩特征
→ 大幅减少显存与计算开销,同时保持长期一致性
✅ 自强迫策略(Self-Forcing)
推理时,模型使用自身生成的帧作为上下文,而非依赖真实数据。
→ 缩小训练-推理差异,缓解错误累积,使长视频生成更稳定
此外,文本控制模块将指令分解为“事件”与“动作”两部分,分别处理后融合,实现对世界状态的细粒度干预。
实测表现:快、准、长
- 图像到视频生成:在指令跟随任务中得分 0.836,显著优于 Wan-2.1、MatrixGame 等模型
- 生成速度:12 FPS(单张 A100 GPU),支持实时交互
- 长视频一致性:在第 4–6 个视频块中,美学质量得分 0.523(未用 TSCM 的基线为 0.442)
- 消融实验证明:移除 TSCM 后,指令跟随得分降至 0.767,验证其关键作用
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











