
由上海市人工智能实验室、复旦大学与上海创新研究院联合研发的新型生成模型 Yume 正式亮相。该模型旨在突破传统生成式 AI 的静态局限,构建一个可探索、可控制、高保真且动态演化的虚拟世界。
- 项目主页:https://stdstu12.github.io/YUME-Project
- GitHub:https://github.com/stdstu12/YUME
- 模型:https://huggingface.co/stdstu123/Yume-I2V-540P
Yume 的核心目标是:让用户从图像、文本或视频出发,进入一个可交互的3D-like动态环境,并通过键盘、外设甚至未来神经信号进行自由探索与操控。

目前发布的预览版本已实现从单张图像生成无限时长、可导航的动态视频世界,并支持通过键盘进行前进、转向等视角控制,标志着“生成式世界”向“可交互世界”的关键演进。
核心功能:输入一张图,进入一个世界
想象以下场景:
- 你上传一张城市街景照片;
- 系统生成一个连续动态的虚拟环境;
- 你按下键盘“前进”键,视角开始沿街道移动;
- 按“左转”,视角自然转向岔路;
- 甚至可实时更改天气、时间或艺术风格。
这正是 Yume 所实现的交互式世界生成能力。
主要功能包括:
- ✅ 交互式探索:支持键盘输入控制相机运动(前进/后退/旋转);
- ✅ 动态世界生成:从图像出发,自回归生成无限长度视频;
- ✅ 世界编辑能力:结合多模态技术(如 GPT-4o),可修改环境属性(天气、光照、风格);
- ✅ 高保真输出:生成画面细节丰富,时间一致性高,伪影少。
技术架构:四大核心组件支撑交互式生成
为实现稳定、可控、高质量的动态世界生成,Yume 构建了包含四个关键模块的完整框架:
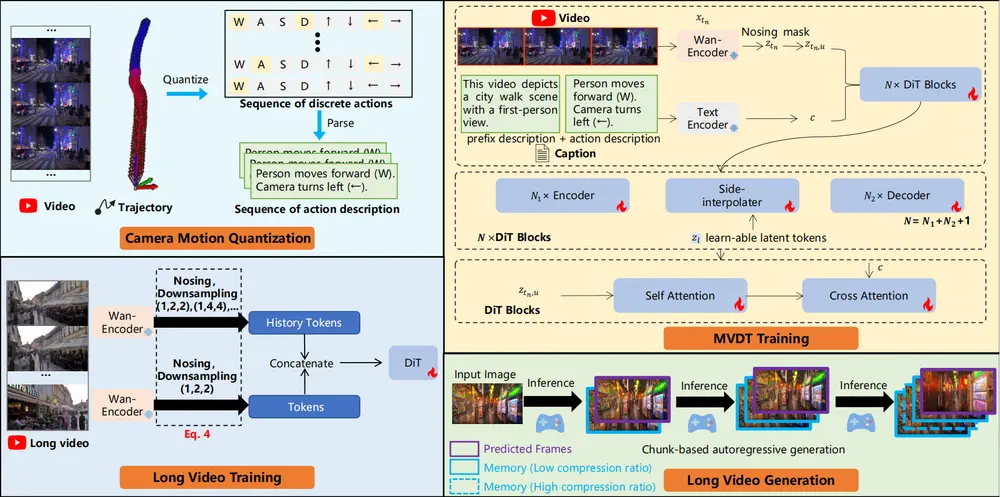
1. 相机运动量化(Quantized Camera Motion, QCM)
传统方法难以将用户输入(如键盘指令)与生成视频中的相机运动精准对齐。Yume 提出 QCM,将连续的相机轨迹离散化为:
- 方向动作:前进、后退、左移、右移;
- 旋转动作:左转、右转、抬头、低头。
这些动作直接映射到键盘操作,并作为条件信号注入模型,无需额外可学习模块,实现低延迟、高响应的交互控制。
2. 蒙版视频扩散变换器(MVDT)+ 帧记忆模块
Yume 采用 Masked Video Diffusion Transformer (MVDT) 作为生成主干,结合 FramePack 记忆模块,实现:
- 自回归式无限生成:逐块生成视频,支持长序列演化;
- 时空一致性保持:通过记忆机制缓存历史帧特征,减少漂移;
- 动态编辑能力:支持在生成过程中引入蒙版,实现局部重绘或对象替换。
这一设计克服了传统文本驱动视频生成中常见的结构崩塌与场景断裂问题。
3. 增强采样机制:提升质量与控制精度
为优化生成质量,Yume 引入两种无需训练的采样增强技术:
- 抗伪影机制(Artifact-free Mechanism, AAM)
对潜在空间表示进行轻量级优化,在不增加训练成本的前提下显著减少模糊、闪烁等视觉伪影。 - 时间旅行SDE采样(TTS-SDE)
基于随机微分方程(SDE)的采样策略,利用未来帧信息反向指导当前帧生成,增强时间连贯性,避免动作跳跃或抖动。
💡 这些机制均无需额外训练,可作为插件式模块集成到现有扩散流程中。
4. 模型加速:对抗蒸馏 + 缓存机制
为提升推理效率,Yume 采用协同优化策略:
- 对抗性蒸馏:训练一个轻量学生模型模仿教师模型行为;
- KV缓存机制:复用注意力键值状态,减少重复计算。
实测效果:采样步数从 50 降至 14 步,推理速度提升 3 倍,同时视觉保真度几乎无损。
测试表现:高一致性、强交互、快生成
在基于高质量世界探索数据集 Sekai 的测试中,Yume 表现出色:
| 指标 | 表现 |
|---|---|
| 指令跟随能力 | 键盘控制准确率达 0.657(满分1.0) |
| 长视频一致性 | 在18秒生成中,主体一致性下降仅 0.5%,背景一致性下降 0.6% |
| 视觉质量 | 在城市、自然、室内等复杂场景中生成清晰、连贯视频 |
| 加速效果 | 推理效率提升3倍,适合实时交互场景 |
应用前景:通向“可编程世界”的一步
Yume 不仅是一个视频生成模型,更是一种构建可交互虚拟空间的新范式,潜在应用场景包括:
- 虚拟旅游:从照片进入可探索的街景世界;
- 游戏开发:快速生成可导航的关卡原型;
- AI 导航训练:为具身智能体提供动态仿真环境;
- 教育与展示:构建可交互的历史场景或建筑模型;
- 未来脑机接口:为神经信号控制的沉浸式体验提供底层支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











