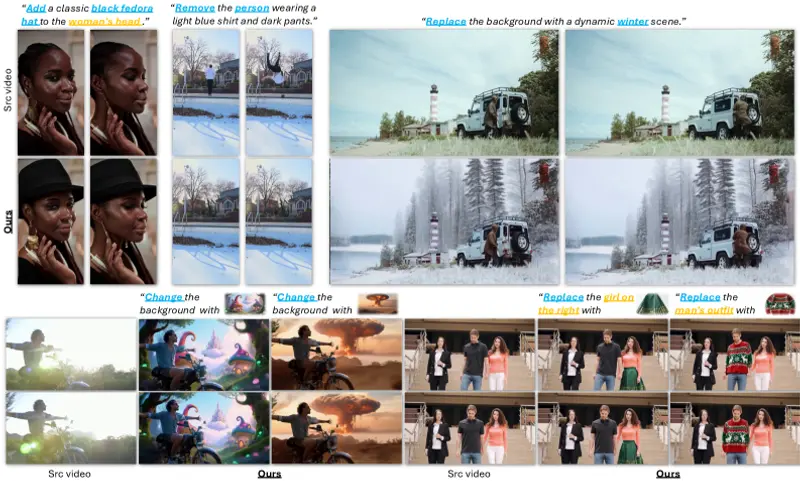
阿里 WAN 项目组正式推出 Wan2.2,这是对 WAN 系列视频生成模型的一次重大升级。本次发布涵盖多个模型变体,全面支持文本到视频(T2V)、图像到视频(I2V)以及混合输入(TI2V)任务,在生成质量、推理效率和可控性方面实现显著提升。
Wan2.2 已全部开源,提供完整模型权重与使用指引,适用于学术研究与工业部署。其核心突破来自三项关键技术:混合专家(MoE)架构、大规模数据扩展 和 高效高压缩视频生成设计。
核心升级:三大技术创新
✅ 1. 混合专家(MoE)架构:更大容量,不变开销
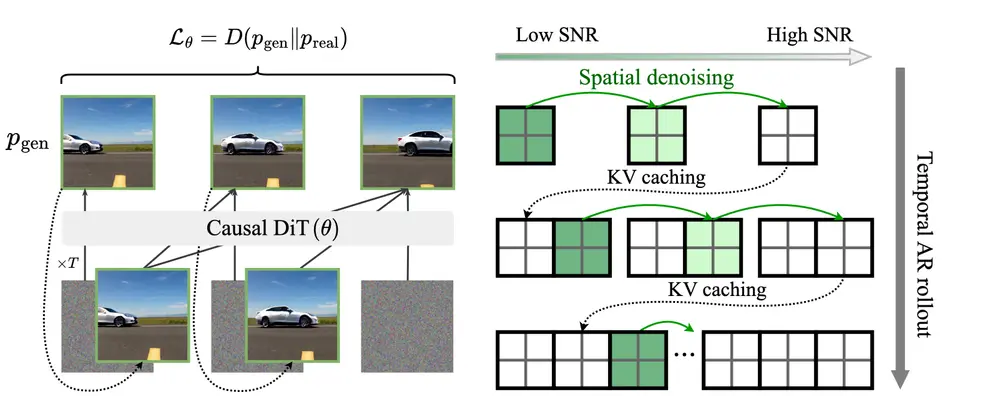
Wan2.2 首次将 混合专家(Mixture of Experts, MoE) 架构引入视频扩散模型。该设计通过在去噪过程中按时间步动态激活不同专家网络,在不增加推理计算成本的前提下,显著提升模型整体容量。
具体实现如下:
- 采用 双专家结构:一个“高噪声专家”负责早期去噪阶段(高噪声水平),专注整体布局与运动结构;一个“低噪声专家”处理后期细节,优化画面清晰度与纹理。
- 每个专家约 14B 参数,总参数达 27B,但每一步仅激活 14B,保持 GPU 内存和计算负载稳定。
- 切换时机由信噪比(SNR)控制:当去噪步数 $ t < t_{\text{moe}} $ 时切换至低噪声专家,确保阶段适配。
实验表明,Wan2.2(MoE)在验证损失上显著低于基线模型 Wan2.1 及其变体,说明其生成分布更接近真实视频数据,具备更强的建模能力。
✅ 2. 数据扩展:+65.6% 图像,+83.2% 视频
相比 Wan2.1,Wan2.2 在训练数据规模上大幅提升:
- 图像数据增加 65.6%
- 视频数据增加 83.2%
这一扩展显著增强了模型在动作连贯性、语义理解与视觉美学等方面的泛化能力。尤其在复杂场景(如人物交互、动态运镜)中表现更为自然。
此外,训练集经过严格清洗与标注,覆盖多样化的风格与主题,为高质量生成打下基础。
✅ 3. 高效高清 TI2V:消费级 GPU 上的 720P@24fps
针对实际部署需求,Wan2.2 推出 TI2V-5B 模型——一个基于高压缩 VAE 的轻量级视频生成方案。
- 支持 720P 分辨率、24fps 视频生成
- 使用 16×16×4 压缩比 的 Wan2.2-VAE,整体压缩率达 64×
- 可在单张消费级 GPU(如 RTX 4090)上运行
- 生成 5 秒视频耗时不足 9 分钟,是目前最快的开源 720P@24fps 模型之一
该模型原生支持 文本+图像联合输入(TI2V),适用于视频续写、图文驱动动画等场景,兼顾性能与实用性。
模型系列概览
| 模型 | 类型 | 分辨率 | 架构 | 特点 |
|---|---|---|---|---|
| Wan2.2-T2V-A14B | 文本到视频 | 480P / 720P | MoE(27B 总参) | 高质量生成,超越多个商业模型 |
| Wan2.2-I2V-A14B | 图像到视频 | 480P / 720P | MoE(27B 总参) | 稳定运动控制,减少异常镜头 |
| Wan2.2-TI2V-5B | 文本-图像到视频 | 720P @24fps | 密集(5B)+ 高压缩 VAE | 单卡可运行,速度快,适合落地 |
所有模型均支持 5 秒视频生成。
电影级美学控制:不只是清晰,更是风格
Wan2.2 特别引入了经过筛选的 电影美学数据集,包含精细标注的光线、构图与色彩信息。这使得模型能够生成更具“电影感”的视频内容,并支持通过提示词调节美学偏好。
例如:
cinematic lighting, shallow depth of field, golden hourneon noir style, slow dolly in, dramatic shadows
这种细粒度控制能力,使 Wan2.2 成为内容创作者、视觉设计师和影视预演团队的新工具。
性能对比:在 Wan-Bench 2.0 上超越领先商业模型
团队构建了新的评估基准 Wan-Bench 2.0,从动作合理性、语义一致性、视觉质量等多个维度对模型进行评测。结果显示:
Wan2.2 在多数关键指标上优于当前领先的闭源商业模型。
尤其在长时序动作连贯性和复杂语义理解任务中表现突出,验证了 MoE 架构与数据扩展的有效性。
模型下载
| 模型 | 下载链接 |
|---|---|
| T2V-A14B | Hugging Face | ModelScope |
| I2V-A14B | Hugging Face | ModelScope |
| TI2V-5B | Hugging Face | ModelScope |
💡 提示:TI2V-5B 支持 720P@24fps 视频生成,适合消费级硬件部署。
结语
Wan2.2 不仅是一次性能升级,更是对视频生成模型架构、训练范式与部署效率的系统性探索。它证明了:
- MoE 架构可有效应用于视频扩散模型;
- 高压缩 VAE 能在不牺牲质量的前提下实现高效推理;
- 开源模型已具备挑战闭源系统的实力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











