唇部同步(Lip Synchronization)是指将视频中的唇部动作与新的输入音频对齐,使其在视觉上看起来自然且与音频同步。尽管这一领域与音频驱动的面部动画(Audio-driven Facial Animation)密切相关,但唇部同步面临着独特的挑战,例如表情泄漏(expression leakage)和面部遮挡(facial occlusions)。这些问题在实际应用中(如自动配音)尤为重要,但往往被现有研究忽视。

为了解决这些挑战,来自帝国理工学院和弗罗茨瓦夫大学的研究人员提出了KeySync,这是一个基于两阶段框架的唇部同步方法,能够生成高分辨率、时间连贯且与音频对齐的视频,同时有效减少表情泄漏并处理面部遮挡。
- 项目主页:https://antonibigata.github.io/KeySync
- GitHub:https://github.com/antonibigata/keysync
- 模型:https://huggingface.co/toninio19/keysync
- Demo:https://huggingface.co/spaces/toninio19/keysync-demo
例如,有一段视频,其中人物正在说话,但音频被替换为另一种语言的配音。使用KeySync进行唇部同步时,它能够生成与新音频完全匹配的唇部动作,同时避免输入视频中的表情泄漏。此外,如果视频中人物的嘴巴被手或其他物体遮挡,KeySync能够自动识别并处理这些遮挡区域,生成自然且连贯的视频。
主要功能
- 高分辨率唇部同步:KeySync能够生成512×512分辨率的视频,显著高于常见的256×256标准,适用于实际应用场景。
- 减少表情泄漏:通过创新的遮罩策略,KeySync能够有效减少输入视频中的表情泄漏,确保生成的视频仅反映输入音频的内容。
- 处理面部遮挡:KeySync在推理阶段引入了一种新的遮挡处理方法,能够自动识别并排除遮挡区域,避免生成不自然的视觉效果。
- 跨语言和跨视频同步:KeySync在跨语言配音和跨视频同步任务中表现出色,适用于多语言内容制作和虚拟头像生成。
主要特点
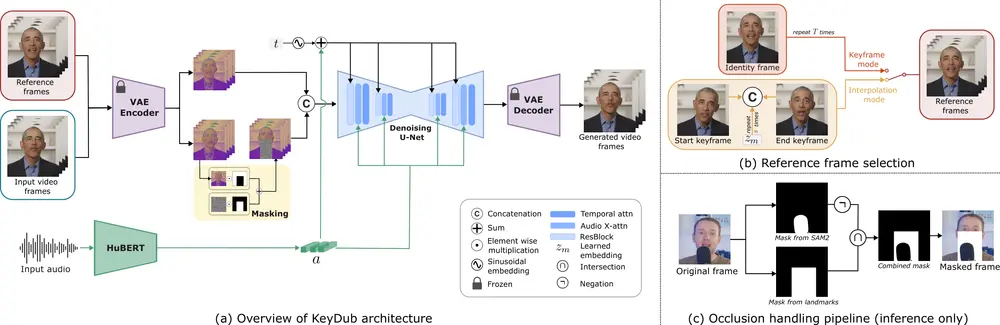
- 两阶段视频生成框架:KeySync采用两阶段方法,首先生成关键帧捕捉音频的关键唇部动作,然后通过插值生成平滑、时间连贯的视频。
- 创新的遮罩策略:通过扩展到鼻部水平的遮罩,KeySync在减少表情泄漏的同时保留了必要的上下文信息。
- 推理时遮挡处理:KeySync在推理阶段使用预训练的视频分割模型自动识别并排除遮挡区域,无需额外训练。
- 鲁棒性验证:通过多种消融实验,KeySync验证了其架构选择和遮罩策略的有效性,展现出在不同条件下的鲁棒性。
工作原理
- 数据集构建:研究人员构建了一个包含1400万图像-掩码对的大规模数据集,通过标注前景和背景类别(分别可能包含116和21个类别),为模型提供了丰富的学习素材。
- 潜在特征编码:使用两个固定大小的嵌入向量分别对前景和背景的潜在特征进行编码,确保模型能够精准地理解图像中的不同元素。
- 两阶段视频生成:
- 关键帧生成:模型首先生成一组稀疏的关键帧,捕捉音频序列中的主要唇部动作,同时保留输入视频的身份特征。
- 插值生成:在关键帧之间进行插值,生成平滑、时间连贯的视频。通过条件生成,模型能够直接建模视频的时间动态。
- 音频编码与对齐:使用HuBERT音频编码器将原始音频转换为学习表示,并通过音频注意力块将其集成到模型中,增强视频与音频的对齐效果。
- 损失函数:结合潜在空间的扩散损失和像素空间的L2损失,确保生成的视频在视觉质量和唇部同步方面表现出色。
应用场景
- 自动配音:KeySync能够将不同语言的音频与原始视频对齐,生成自然的唇部动作,适用于多语言内容制作,帮助消除语言障碍。
- 虚拟头像生成:在虚拟现实和增强现实应用中,KeySync可以生成与音频同步的虚拟头像,提升用户体验。
总结
KeySync通过其创新的两阶段框架和遮罩策略,在唇部同步领域取得了显著的突破。它不仅能够生成高分辨率、时间连贯的视频,还能有效减少表情泄漏并处理面部遮挡。这些特性使得KeySync在自动配音、虚拟头像生成和视频编辑等实际应用中具有广泛的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











