腾讯今天正式推出混元世界模型 - Voyager(HunyuanWorld-Voyager),这是一款创新的视频扩散框架。其核心能力在于:基于单张输入图像即可生成具备世界一致性的 3D 点云,支持用户按照自定义相机路径沉浸式探索虚拟世界;同时能同步生成精确对齐的深度信息与 RGB 视频,无需额外后处理,可直接用于高质量三维重建。
- 项目主页:https://3d-models.hunyuan.tencent.com/world
- GitHub:https://github.com/Tencent-Hunyuan/HunyuanWorld-Voyager
- 模型:https://huggingface.co/tencent/HunyuanWorld-Voyager
与传统视频生成方法不同,Voyager 不仅关注画面质量,更强调场景的几何合理性与跨视角一致性。用户可自定义相机路径,在生成的虚拟空间中进行沉浸式探索,而无需依赖额外后处理即可直接用于3D重建。

核心能力:一次生成,双重输出
Voyager 的关键突破在于其联合生成RGB视频与深度序列的能力。在推理过程中,模型同时输出彩色帧及其对应的逐像素深度图,二者在时空维度上严格对齐。这一特性使得生成结果可直接用于如 3D Gaussian Splatting(3DGS)等现代重建技术,显著降低了从2D内容构建3D世界的门槛。
更重要的是,整个生成过程保持了全局场景的一致性——即便相机移动较远距离,物体结构、空间关系仍能稳定维持,避免常见于扩散模型中的结构崩塌或形变失真。

模型架构:两大核心技术支撑长距离探索
Voyager 的设计围绕两个核心模块展开:
- 世界一致的视频扩散机制
采用统一的扩散架构,以历史观测为条件,逐步生成未来帧的RGB与深度数据。通过引入跨帧注意力与几何约束损失,确保生成序列在视觉和几何层面均保持连贯,有效应对大范围相机运动带来的挑战。 - 长距离探索与动态世界缓存
面对连续生成中的记忆累积问题,Voyager 提出一种上下文感知的世界缓存机制。该机制结合点云剔除策略与自回归推理,动态更新场景表示,在控制计算开销的同时实现场景的渐进式扩展,支持长时间、远距离的自由导航。
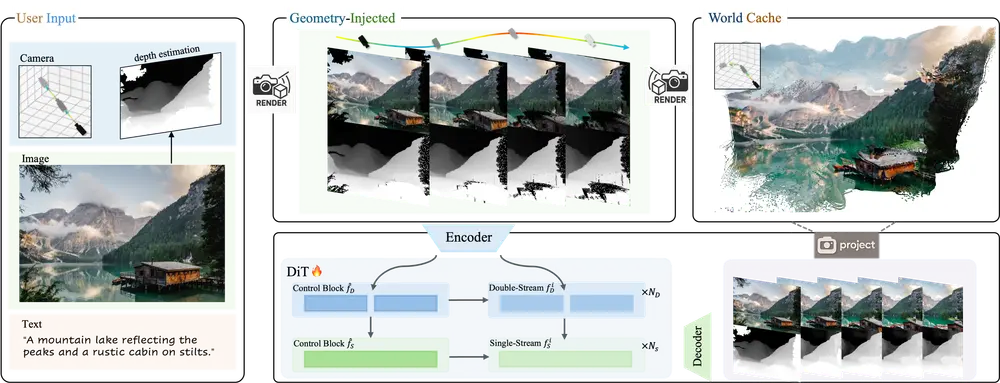
数据构建:自动化流水线支撑大规模训练
为训练这一复杂模型,团队开发了一套可扩展的数据构建引擎,实现从原始视频到训练样本的全自动化处理。
该流水线能自动估计输入视频的相机位姿与度量深度(metric depth),无需人工标注,即可生成包含RGB-D序列与对应轨迹的大规模数据集。基于此,Voyager 融合了真实拍摄视频与虚幻引擎合成数据,最终构建出超过 10万段视频片段 的多样化训练集,覆盖室内外多种场景类型。
实验验证:多维度性能领先
1. 视频生成质量对比
在 RealEstate10K 测试集上,研究团队将 Voyager 与四种开源相机可控视频生成方法进行对比,评估指标包括 PSNR、SSIM 和 LPIPS。
| 方法 | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| Baseline A | 28.1 | 0.86 | 0.19 |
| Baseline B | 27.5 | 0.84 | 0.22 |
| ... | ... | ... | ... |
| Voyager (Ours) | 30.4 | 0.91 | 0.13 |
结果显示,Voyager 在所有指标上均优于基线模型。定性对比也表明,其生成视频在细节保留(如纹理、边缘)方面表现更优。例如,在产品展示类图像中,其他方法在大角度运动下易出现模糊或伪影,而 Voyager 能有效维持原始结构特征。
2. 场景重建能力评估
由于多数基线仅生成RGB帧,需借助外部深度估计模型(如VGGT)才能进行3D重建。而 Voyager 直接输出RGB-D数据,省去中间步骤。
实验显示:
- 使用 VGGT 对基线方法生成视频估计深度后重建,Voyager 仍取得更优的点云完整性与几何保真度;
- 若直接使用 Voyager 自带的深度信息初始化点云,重建质量进一步提升,验证了其深度生成模块的准确性。
在吊灯、家具等复杂结构场景中,Voyager 成功还原了精细几何形态,而其他方法往往只能生成粗略轮廓。
3. 世界生成综合表现
在 WorldScore 静态基准测试中,Voyager 在相机控制精度、空间一致性与视觉真实性等方面均获得最高分,表明其在构建“可探索世界”方面具备显著优势。
此外,得益于以度量深度作为生成条件,Voyager 支持更大范围的相机运动(如环绕、纵深推进),这对模型的空间理解能力提出了更高要求,也体现了其更强的泛化能力。
应用前景:通向具身智能与虚拟探索
Voyager 的能力不仅限于视觉生成。其输出的RGB-D序列与一致的空间结构,为以下方向提供了基础支持:
- 虚拟现实内容快速生成:从一张照片出发,构建可交互的3D环境;
- 机器人仿真与导航训练:生成具真实感的动态场景,用于感知与路径规划测试;
- 数字孪生与城市建模:辅助从有限视角推断完整空间布局。
更重要的是,该模型展示了从被动观看向主动探索转变的技术趋势——用户不再是视频的接收者,而是可以自由移动的“观察者”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











