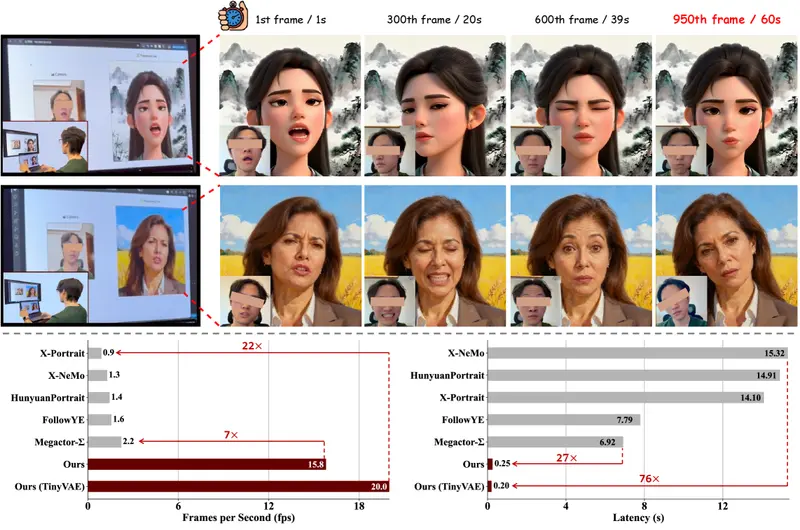
字节跳动近期推出新型视频角色生成框架 OmniHuman-1.5,核心突破在于模拟人类“系统1(快速直觉反应)+系统2(缓慢深思规划)”的双重认知过程,实现从“单一图像+语音轨道”到“物理逼真、语义连贯、富有表现力”的角色动画生成。无论是单人情感表演、音乐节奏同步,还是多人互动场景,该框架都能让角色动画与音频语义、文本指令精准匹配,甚至支持超过一分钟的长视频生成。
核心价值:解决传统角色动画生成的三大痛点
传统视频角色生成技术常面临“动作与语义脱节”“场景适配性差”“长视频连贯性不足”的问题,而OmniHuman-1.5通过认知模拟与多模态融合,针对性破解这些痛点:
- 告别“机械同步”:不再局限于“唇部动作随音频节奏动”的表层匹配,而是能解读音频中的情感(如愤怒、温柔)与意图(如强调观点、表达疑问),让角色手势、表情与语义深度契合;
- 突破“单一场景”:从单人表演扩展到多人互动,从真实人类延伸到动物、卡通角色,还能支持音乐演唱、电影化情感表达等复杂场景;
- 解决“长视频断层”:通过动态调整动作计划的“反思”机制,避免长视频中动作逻辑断裂(如前一秒抬手、后一秒突然放下),确保超过一分钟的动画连贯自然。
五大核心能力:覆盖多场景角色动画需求
OmniHuman-1.5的实用价值体现在具体场景的落地能力上,目前已实现五大核心功能,可直接适配内容创作、数字人演出等需求:
1. 语境感知的音频驱动动画
区别于传统“仅做唇部同步”的工具,该框架能深度解读音频语义:
- 若音频是“产品介绍”,角色会自然做出“指向虚拟屏幕”“手势强调重点”的动作;
- 若音频含情感波动(如从平静到激动),角色表情会同步从温和过渡到皱眉、提高手势幅度,仿佛“拥有自主意志”。
2. 音乐节奏适配的表演生成
针对音乐场景,框架可将单一角色图像转化为“数字歌手”:
- 不仅能精准匹配歌词的唇部动作,还能捕捉音乐的节奏变化(如抒情曲的缓慢抬手、快歌的活力摆臂);
- 支持自然停顿处理(如歌曲间奏时,角色会停止演唱动作,保持放松姿态),适配从独唱到演唱会的多种风格。
3. 音频情感驱动的电影化表演
无需额外文本提示,模型可通过分析音频中的情感潜台词,生成戏剧化动画:
- 若音频是“激烈争吵”,角色会出现皱眉、握拳、身体前倾的动作;
- 若音频是“真挚告白”,角色会呈现柔和眼神、缓慢抬手轻触胸口的细节,还原电影级的情感表达。
4. 文本引导的多维度控制
通过文本提示,可精准调控动画的细节维度,实现“指令即所得”:
- 文本输入“角色手持话筒,镜头从远拉近”,模型会同时生成“持话筒动作”与“镜头移动效果”,且不破坏与音频的同步性;
- 文本输入“角色做出OK手势,背景保持简洁”,框架能在保证音频匹配的前提下,精准添加指定动作、控制场景元素。
5. 多人场景的互动动画生成
支持复杂的多人互动场景,解决“多角色音频分配”难题:
- 输入含多个说话人的音频轨道+多人同框图像,模型能自动将不同音频分配给对应角色(如左侧角色说第一句,右侧角色说第二句);
- 生成互动动作(如角色A说话时,角色B点头回应;合唱场景中,多人动作同步且各具细节),避免“多人同框但动作独立”的生硬感。
此外,框架还具备强鲁棒性,可对真实动物(如生成“小狗跟着指令叫,动作同步音频”)、拟人化角色(如卡通形象唱歌)生成高质量动画,不局限于人类角色。
技术创新:三大设计支撑认知模拟与多模态融合
OmniHuman-1.5的性能突破,源于底层技术的三大核心创新,确保“认知模拟”与“多模态对齐”落地:
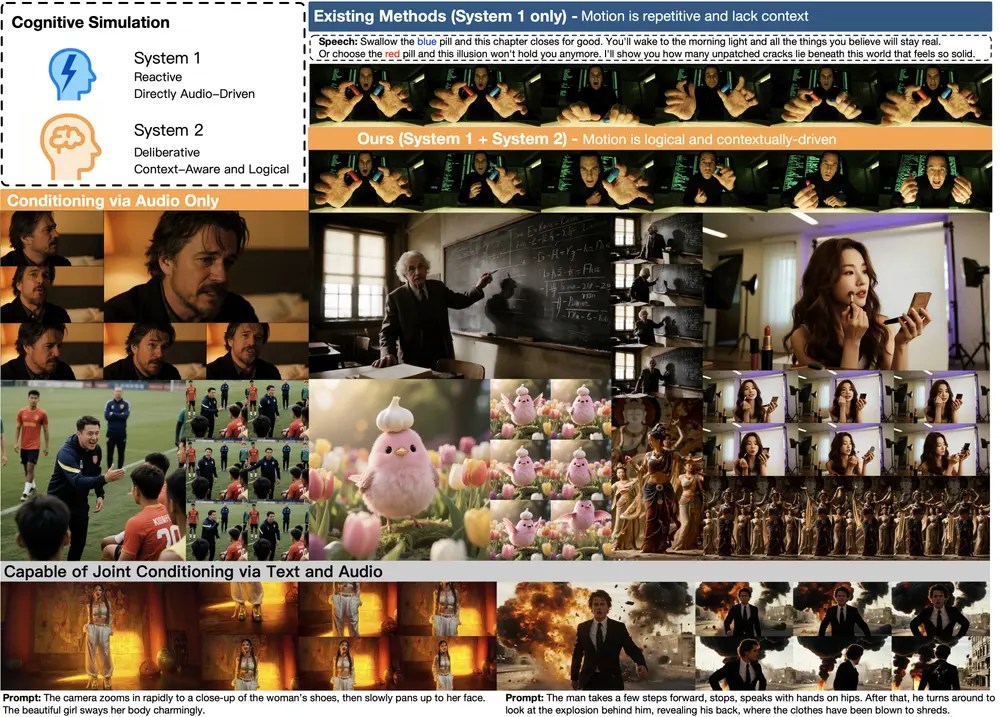
1. 双重认知模拟架构(系统1+系统2)
受人类认知理论启发,框架融合多模态大语言模型(MLLM)与扩散变换器,分别模拟两种思维模式:
- 系统1(快速直觉反应):负责即时性、高频的动作生成,如唇部同步、随音频节奏的快速手势,确保“动作不延迟”;
- 系统2(缓慢深思规划):由MLLM提供高层语义指导,分析音频情感、文本指令,规划长时间段的动作逻辑(如“接下来10秒,角色需从站立转为坐下,并保持与音频同步”),避免动作混乱。
2. 伪最后一帧设计
解决传统模型“静态参考图像干扰动态生成”的问题:
- 训练时,模型不直接使用初始输入的角色图像作为参考,而是生成“伪最后一帧”(模拟前一帧的动态状态);
- 以此引导后续帧的动作生成,确保动作连贯(如初始图像是“角色双手下垂”,伪最后一帧可生成“角色抬手至胸前”,避免后续帧突然回到“双手下垂”的静态状态)。
3. 对称融合架构
实现音频、文本、视频的深度语义对齐,避免“多模态信息脱节”:
- 设计专门的音频分支,提取音频的节奏、情感特征;
- 通过多模态注意力机制,将音频特征、文本指令特征与视频动作特征对称融合(如文本“持话筒”、音频“唱歌”、视频“手部动作”三者相互校准),确保各模态信息不冲突、不遗漏。
工作原理:五步骤实现从输入到动画的端到端生成
OmniHuman-1.5的工作流程清晰,可分为五个核心步骤,实现“多模态输入→语义解析→动作规划→动画生成→动态调整”的端到端闭环:
- 多模态输入接收:获取初始角色图像(单人/多人)、音频轨道(单声道/多声道)、可选文本提示(如动作、镜头控制指令);
- 高层语义指导生成:多模态大语言模型(MLLM)分析输入条件,生成结构化文本表示(如“音频情感:愤怒;核心动作:握拳、前倾;文本指令:持话筒”),为动作规划提供依据;
- 动作计划制定:基于MLLM的语义指导,模型生成时间维度的动作计划(如“0-5秒:角色站立,开始说话,唇部动作同步;5-10秒:角色抬手握拳,表情皱眉”);
- 动态融合生成动画:通过伪最后一帧策略引导动作连贯性,结合对称融合架构将音频、文本、动作特征融合,生成逐帧动画;
- 长视频自适应调整:生成超过30秒的长视频时,模型启动“反思”过程,检查前序动作与后续计划的逻辑一致性(如发现“前一帧角色抬手,后一帧突然放下”的矛盾),动态调整动作计划,确保整体连贯。
测试表现:多维度指标领先,用户认可度高
在权威基准测试与用户研究中,OmniHuman-1.5的表现全面优于现有方法:
- 客观指标领先:在唇部同步准确性(如音频与唇部动作的时间差)、视频质量(清晰度、无模糊)、动作自然性(无卡顿、无逻辑矛盾)、语义一致性(动作与音频/文本匹配度)等指标上,均排名前列;
- 用户反馈优异:对比实验显示,超过75%的用户认为OmniHuman-1.5生成的动画“更自然、更符合语义”,显著优于传统方法;
- 场景扩展性强:在多人场景、非人类角色(动物、卡通)测试中,模型保持高质量输出,未出现性能下降(如多人互动时动作不同步、动物角色动作失真)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











