腾讯今天正式开源 HunyuanVideo-Foley —— 一个端到端的文本-视频-音频(Text-Video-to-Audio, TV2A)生成模型,专注于为视频内容自动生成高保真、语义对齐的音效。
- 项目主页:https://szczesnys.github.io/hunyuanvideo-foley
- GitHub:https://github.com/Tencent-Hunyuan/HunyuanVideo-Foley
- 模型:https://huggingface.co/tencent/HunyuanVideo-Foley
- Demo:https://huggingface.co/spaces/tencent/HunyuanVideo-Foley
它不是简单的背景音乐叠加,而是能让一段无声的海滩视频,精准“响起”海浪拍岸、海鸥鸣叫的声音;让动画角色的脚步声,随着动作节奏自然变化。这种能力,正是当前影视、游戏、短视频创作中亟需的“声音还原”技术。
HunyuanVideo-Foley 的目标很明确:解决视频生成中“有画无声”或“声画错位”的痛点,为创作者提供专业级、可控制、高同步的音效生成工具。
核心价值:为多领域创作赋能
HunyuanVideo-Foley的核心价值,在于打破传统音频生成与视频内容脱节的痛点,为不同场景的创作提供“音视同步”的专业级解决方案:
- 短视频创作:无需额外录制或寻找音效素材,模型可根据短视频画面(如美食制作、旅行风景)与文本描述(如“煎蛋滋滋声”“风吹树叶沙沙响”),快速生成贴合内容的音频,提升作品感染力;
- 电影与广告制作:针对复杂镜头(如动作场景、自然景观),能精准捕捉从主要主体(如人物对话、汽车引擎声)到细微背景元素(如远处鸟鸣、脚步声回音)的音效,减少后期配音的时间成本;
- 游戏开发:为游戏场景(如奇幻地图、战斗画面)生成沉浸式音景,让玩家在视觉交互的同时,通过声音感知场景氛围,增强游戏体验。
三大关键创新:破解V2A生成难题
为实现“高保真、强对齐、广适配”的音频生成效果,HunyuanVideo-Foley在技术层面实现了三大核心突破:
1. 卓越泛化能力:覆盖全场景音景生成
模型基于10万小时多模态数据集训练,数据集涵盖自然景观、城市生活、动画短片、游戏场景等多种类型。这使得模型能适应不同风格的视频内容,无论是静谧的森林画面,还是热闹的赛事场景,都能生成具有语义感知的音景,避免“千片一音”的局限。
2. 平衡多模态响应:MMDiT架构把控细节
传统V2A生成常出现“重视觉轻文本”或“重文本轻视觉”的问题,导致音频与内容脱节。HunyuanVideo-Foley创新采用多模态扩散变换器(MMDiT)架构,通过双流设计平衡视频视觉线索与文本语义信息:
- 一方面,通过视觉编码模块提取视频帧中的动态特征(如物体移动、光线变化);
- 另一方面,通过文本编码模块解析描述中的关键信息(如“雨声”“儿童笑声”);
- 最终通过交叉注意力机制融合两者,生成层次分明的音效,确保每一个细节都不被遗漏。
3. 高保真音频输出:技术组合消除噪声
为达到专业级音频质量,模型采用“REPA损失函数+音频变分自编码器(Audio VAE)”的技术组合:
- REPA损失函数:通过将扩散模型的隐藏嵌入与预训练自监督音频特征对齐,提升音频生成的稳定性,减少失真;
- 48kHz音频变分自编码器:自主研发的高采样率编码器,能精准重构音效、音乐和人声,有效消除传统生成中常见的噪声、卡顿与不一致性,让音频质量达到专业制作标准。
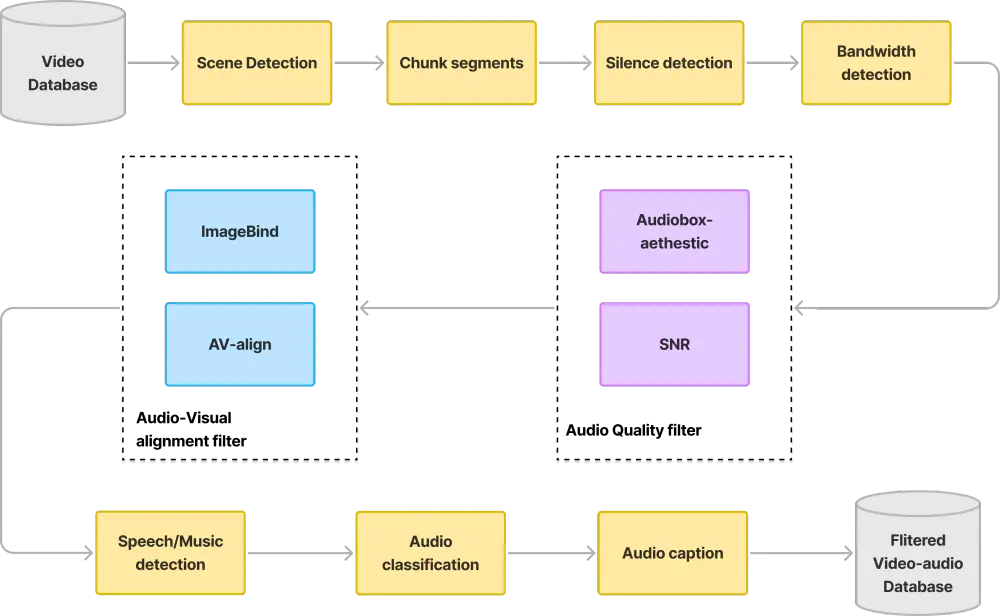
技术架构:从数据到生成的全流程设计
HunyuanVideo-Foley的端到端能力,依赖于从数据管道到模型生成的全流程优化,具体可分为四大模块:
1. 数据管道:筛选高质量训练素材
TV2A任务对数据集质量要求极高,模型通过多阶段过滤流程构建训练数据:
- 第一步,从海量原始视频数据库中筛选“视频-音频”配对素材;
- 第二步,通过算法排除音频模糊、内容不匹配的素材;
- 第三步,进行自动化标注(如标注“场景类型”“音效类别”)与分类,最终形成10万小时高质量多模态数据集,为模型泛化能力打下基础。
2. 编码模块:提取多模态特征
- 视觉编码:采用预训练SigLIP2编码器,从视频帧中提取动态与静态特征,捕捉物体运动、场景变化等信息;
- 文本编码:使用CLAP预训练文本编码器,解析输入描述中的语义,将“海浪声、海鸥叫”等文本转化为可计算的特征向量;
- 音频编码:通过DAC-VAE编码器处理原始音频,同时加入高斯噪声扰动,增强模型对不同音频质量的适应能力。
3. 多模态融合:MMDiT实现精准对齐
在融合阶段,MMDiT架构通过两大核心机制实现多模态协同:
- 联合自注意力:同时处理音频、视觉、文本特征,挖掘三者间的关联(如“海浪画面”与“海浪声”“文本描述”的对应关系);
- 门控调制:基于Synchformer的帧级同步技术,确保音频与视频帧在时间上精准对齐,避免“声画不同步”问题。
4. 生成优化:REPA引导提升质量
在音频生成过程中,通过表示对齐(REPA)策略进一步优化:将单流音频扩散模型(DiT)块的隐藏状态,与预训练自监督音频特征对齐,确保生成的音频在语义(如“雨声”对应“下雨画面”)和声学(如音质、音量)上均与内容匹配。
测试表现:多项基准刷新业界水平
在三大权威数据集测试中,HunyuanVideo-Foley的表现全面超越现有开源模型,具体成绩如下:
| 测试数据集 | 关键优势指标 | 表现亮点 |
|---|---|---|
| Kling-Audio-Eval | 分布匹配(FD、KL)、音频质量(PQ)、视觉-语义对齐(IB)、时间对齐(DeSync) | 所有指标均优于现有方法,实现“全维度领先” |
| VGGSound-Test | 音频质量(IS、PQ)、视觉-语义对齐(IB) | 音频质量表现突出,视觉-语义对齐保持最优 |
| MovieGen-Audio-Bench | 客观指标(PQ、DeSync、IB)、主观评估 | 几乎所有指标均为最佳,得到主观体验认可 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...