
在数字人、虚拟主播和直播场景中,高质量、低延迟、身份一致的肖像动画是核心需求。然而,主流扩散模型虽能生成逼真画面,却因高计算成本与多步去噪,难以满足实时交互要求——生成一段3秒视频往往需要数十秒,远不能用于直播。
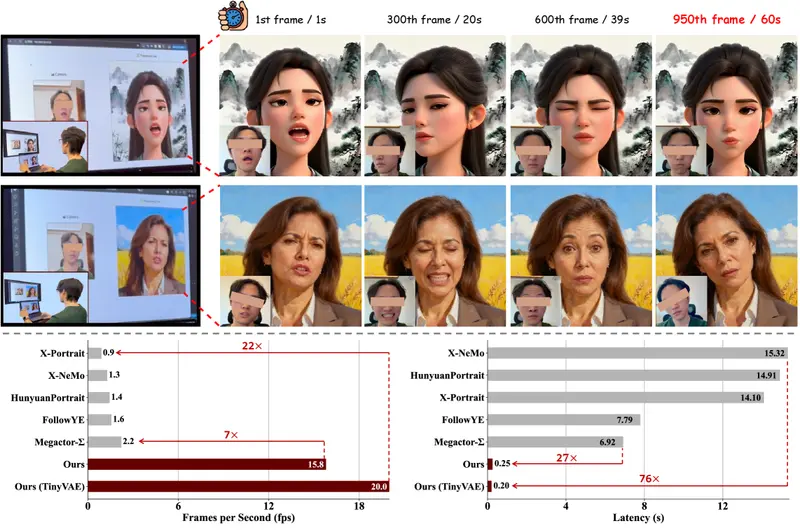
由澳门大学、Dzine.ai 与大湾区大学联合提出的 PersonaLive,首次将扩散模型带入实时肖像动画直播的实用范畴。它在单张 NVIDIA H100 GPU 上实现 15.82 FPS 的推理速度,平均端到端延迟仅 0.253 秒,同时保持高保真度与长期稳定性。
为什么传统扩散模型“不适合直播”?
典型扩散肖像动画流程(如 AnimateDiff 或其变体)存在三大瓶颈:
- 步骤多:需20–50步去噪,每帧耗时数百毫秒;
- 错误累积:自回归生成中,前一帧的微小偏差会逐帧放大,导致“脸崩”或身份漂移;
- 运动控制粗糙:仅依赖2D关键点或光流,难以精细表达3D头部姿态与微表情。
PersonaLive 通过三重架构创新,系统性解决这些问题。
三大核心技术突破
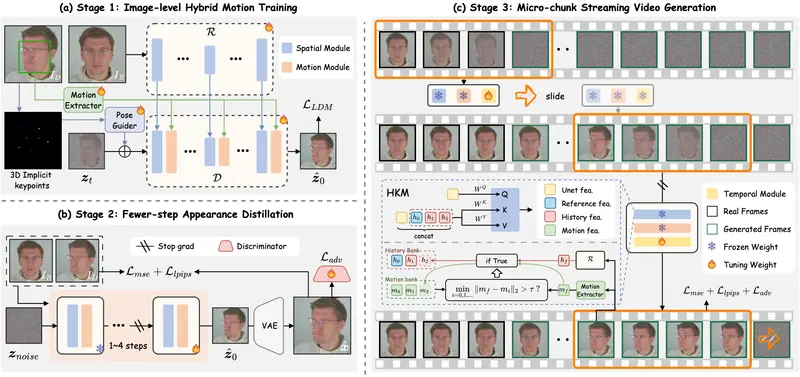
1. 混合隐式信号控制:更精细的运动驱动
PersonaLive 引入两种隐式信号作为运动条件:
- 隐式面部表示(Implicit Facial Representation):编码表情细微变化(如眼皮颤动、嘴角上扬);
- 3D 隐式关键点(3D Implicit Keypoints):捕获头部旋转、平移等空间运动。
这两种信号通过交叉注意力机制注入扩散模型,实现对表情+姿态的解耦控制,避免传统方法中“表情带动头部抖动”等耦合失真。
2. 更少步骤的外观蒸馏:提速不降质
团队对预训练扩散模型进行外观蒸馏(Appearance Distillation):
- 将原本需多步优化的细节(如皮肤纹理、头发反光)压缩至极少数采样步骤(如4–6步);
- 保留语义结构的同时,大幅降低计算开销。
✅ 实测:在仅4步去噪下,视觉质量仍接近全步长模型。
3. 微块流式视频生成:解决长期稳定性问题
为避免自回归错误累积,PersonaLive 提出 “微块流式生成”(Micro-Chunk Streaming) 范式:
- 将长视频切分为多个短时微块(如16帧);
- 每个微块训练时引入滑动窗口历史关键帧作为上下文;
- 推理时流式输出,新微块以旧微块末尾帧为锚点,确保时序连贯。
该设计有效抑制身份漂移与动作断裂,实现分钟级稳定生成。
性能:真正“直播可用”
✅ 效率指标(NVIDIA H100)
| 配置 | FPS | 平均延迟 |
|---|---|---|
| 标准 VAE | 15.82 | 0.253 s |
| TinyVAE(轻量解码器) | 20.0 | ~0.2 s |
对比:多数扩散动画模型 < 2 FPS,延迟 > 2 秒。
✅ 质量评估(TalkingHead-1KH 数据集)
- L1 / SSIM / LPIPS:全面优于 AnimateDiff、V-Express 等主流方法;
- tLP(时序 Lipschitzness):衡量动作平滑性,PersonaLive 显著领先,表明运动更自然。
✅ 用户研究
在真实感、身份一致性和动作自然度三项主观评价中,84.7% 的用户偏好 PersonaLive。
应用场景
- 虚拟主播直播:用一张照片+实时摄像头/音频驱动,生成低延迟数字人;
- 远程会议:用户上传肖像,系统实时驱动其“在场”发言;
- 游戏与社交:为玩家提供个性化、表情丰富的实时Avatar;
- 内容创作:快速生成高质量数字人短视频,无需后期渲染。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











