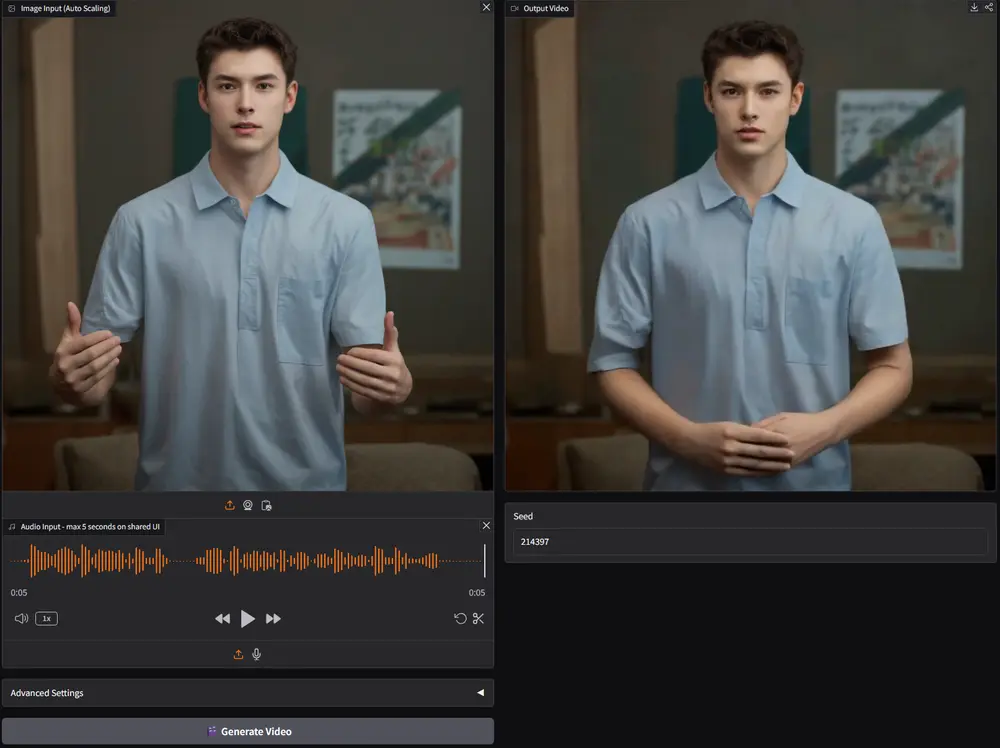
音频驱动的人类视频合成(Audio-Driven Talking Head)近年来在唇形同步和画面逼真度上取得显著进展。但生成长时间、高动态、身份一致的视频仍是行业难题:现有方法要么在长序列中出现身份漂移,要么在静音段落变得动作僵直,甚至因“关键帧复制”导致动作重复。
- 项目主页:https://meigen-ai.github.io/LongCat-Video-Avatar
- GitHub:https://github.com/meituan-longcat/LongCat-Video
- 模型:https://huggingface.co/meituan-longcat/LongCat-Video-Avatar
美团 LongCat 团队最新发布的 LongCat-Video-Avatar,通过统一架构设计与三项关键技术,系统性解决了这些问题。它不仅能生成超逼真、唇音同步的长视频,还支持多种输入模式(音频+文本、音频+图像、纯音频)和多人物对话场景。
三大核心挑战,LongCat 如何破解?
❌ 问题1:静音时角色“石化”
多数模型过度依赖语音信号,一旦输入静音,角色便停止所有微表情和身体动作,显得不自然。
✅ 解耦无条件引导(Disentangled Unconditional Guidance)
LongCat 将语音内容与动作动态解耦:
- 语音仅控制唇部同步;
- 动作由独立的“无条件引导”模块生成,即使在静音段落,角色仍会自然眨眼、点头、呼吸。
→ 实现“有声时说话,无声时活着”。
❌ 问题2:长视频身份漂移 & “复制粘贴”效应
为维持身份一致性,一些方法(如 InfiniteTalk)周期性插入参考关键帧,但会导致动作重复、缺乏多样性。
✅ 参考跳过注意力机制(Reference Skip Attention)
- 参考图像作为身份锚点注入,但在注意力计算中被策略性跳过;
- 既保留身份特征,又避免模型直接“复制”参考帧的细节;
→ 动作多样、身份稳定,告别“循环播放”。
❌ 问题3:长序列像素退化(VAE 误差累积)
传统方法在分块生成长视频时,需反复对每块进行 VAE 解码→编码,导致像素信息逐块退化。
✅ 跨块潜在缝合(Cross-Chunk Latent Stitching)
- 在训练与推理中,直接传递前一块的潜在表示作为下一区块的上下文;
- 完全跳过中间的 VAE 解码-编码循环;
→ 减少信息损失,缩小训练-测试差距,提升长视频一致性。
一个模型,三种生成模式
LongCat-Video-Avatar 采用统一 DiT(Diffusion Transformer)架构,无需切换模型即可支持:
- AT2V(音频+文本 → 视频)
→ 仅需语音和文字描述(如“微笑并看向右侧”),生成完整角色动画; - ATI2V(音频+文本+参考图 → 视频)
→ 指定角色外观,生成高度个性化视频; - 视频延续(Audio-Driven Video Continuation)
→ 基于已有视频片段,继续生成后续内容,适用于长对话场景。
✅ 兼容单流/多流音频:支持单人说话或多人对话(每人一路音频),天然适配虚拟会议、播客等场景。
性能表现:全面超越现有方法
定量评估(HDTF 数据集)
| 指标 | LongCat-Video-Avatar | 之前最优 |
|---|---|---|
| FID(↓) | 51.63 | 62.1 |
| FVD(↓) | 206.46 | 280.3 |
| Sync-C(↑) | 9.23 | 8.1 |
| Sync-D(↑) | 6.51 | 5.7 |
FID/FVD 衡量画质与时序一致性,Sync-C/D 衡量唇音同步精度。
用户研究
在自然度、身份一致性、动作多样性、整体逼真度四项主观评价中,LongCat 显著优于对比模型,尤其在长时间生成(>30秒)场景下优势更明显。
定性效果
- 生成 1 分钟以上视频无身份漂移;
- 静音段落仍有自然微动作;
- 多人物对话中,各角色表情与语音精准对应。
应用前景
- 虚拟主播/数字人:生成长时段、高动态、身份稳定的直播内容;
- AI 视频客服:结合 TTS 与角色动画,提供自然交互体验;
- 影视预演:快速生成带表演的剧本可视化;
- 无障碍通信:为听障用户提供带表情的语音可视化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...