
在肖像动画(Portrait Animation)任务中,身份一致性与推理效率是两大长期瓶颈。现有扩散模型即便能生成逼真短片,也常在长序列中出现身份漂移、颜色偏移或动作断裂,且生成速度慢,难以用于实际场景。
- 项目主页:https://francis-rings.github.io/FlashPortrait/
- GitHub:https://github.com/Francis-Rings/FlashPortrait
- 模型:https://huggingface.co/FrancisRing/FlashPortrait
由复旦大学、微软亚洲研究院、西安交通大学、腾讯、阿里巴巴联合提出的 FlashPortrait,首次实现了端到端、无限长度、高保真、身份稳定的肖像动画生成,并在推理速度上实现 高达 6 倍的加速——所有视频直接合成,无需任何换脸或面部修复后处理(如 FaceFusion、GFP-GAN、CodeFormer)。

三大技术突破,直击行业痛点
❌ 问题1:长视频身份不稳定
扩散模型在长时间生成中,因潜在空间漂移导致角色“越长越不像”。
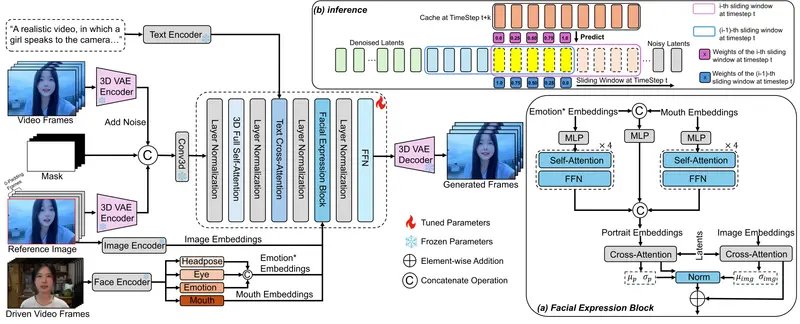
✅ 归一化面部表情块(Normalized Facial Expression Block)
- 使用预训练特征提取器获取身份无关的面部表情特征;
- 计算其与扩散潜在表示的均值与方差,进行归一化对齐;
- 显著缩小两者分布差距,强化身份锚定,从源头提升稳定性。
📌 关键设计:身份由参考图固定,表情由驱动信号控制,二者解耦。
❌ 问题2:生成速度慢,无法实用
标准扩散模型需数十步去噪,生成1秒视频常耗时数秒。
✅ 自适应潜在预测加速机制(Adaptive Latent Prediction)
- 在每个滑动窗口内,利用高阶隐变量导数(通过历史步差分近似);
- 通过动态阶数的泰勒展开,直接预测未来多步的潜在表示;
- 跳过冗余去噪步骤,推理速度提升 3–6 倍(实测平均 4.8 倍)。
❌ 问题3:长视频片段拼接不自然
分块生成易导致边界闪烁或动作跳变。
✅ 加权滑动窗口融合(Weighted Sliding Window)
- 窗口间设置重叠区;
- 对重叠区域的潜在表示进行时间加权融合;
- 确保动作、光照、身份在数千帧内平滑过渡。
性能表现:速度与质量双领先
定量评估(VoxCeleb2 / VFHQ / Hard100)
| 指标 | FlashPortrait | 对比方法(如 Wan-Animate) |
|---|---|---|
| AED(动作误差) | ↓30.9% | 基线 |
| APD(姿态误差) | ↓30.4% | 基线 |
| MAE(像素误差) | ↓37.5% | 基线 |
| 推理速度 | 3–6 倍加速 | 1× |
在 FID、FVD、PSNR、SSIM 等通用指标上,FlashPortrait 也全面领先。
定性效果
- 成功生成超过 3000 帧(约 2 分钟)的连续视频;
- 全程无身份漂移、无颜色偏移、无后处理依赖;
- 背景保持稳定,前景动作精准跟随驱动信号。
用户研究
在身份一致性、动作自然度、画面质量、整体偏好四项主观评价中,92.8% 的用户选择 FlashPortrait 优于对比模型。
无需后处理:端到端生成的工程意义
与多数“生成+换脸+修复”流水线不同,FlashPortrait 端到端输出最终视频。这意味着:
- 流程简化:无需部署 FaceFusion 等第三方工具;
- 质量可控:避免后处理引入的 artifacts(如边缘伪影、肤色失真);
- 部署轻量:更适合集成到直播、虚拟人、移动端等资源敏感场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











