
“好莱坞大片里那些令人震撼的火焰、冰霜、能量波,曾经需要数百万美元和数年训练才能制作。现在,只需一段参考视频和一张照片,AI 就能为你‘克隆’出同样的奇迹。”
由 腾讯混元 (Tencent HunYuan) 与 香港城市大学 联合研发的 EffectMaker 。这是一个推理 - 生成框架,它打破了传统 AIGC 视频生成的局限,首次实现了无需针对特定效果进行 LoRA 微调,即可将复杂的视频特效从零样本迁移到静态图像上。
- 项目主页:https://effectmaker.github.io
- GitHub:https://github.com/ysy31415/EffectMaker
无论是让双手发出闪电,还是让身体化作水晶,EffectMaker 都能精准理解并完美复现,为电影后期、游戏设计及短视频创作带来了前所未有的生产力变革。

核心突破:告别“一效一训”,迈向“万能克隆”
1. ❌ 传统痛点:昂贵且低效
现有的 AI 视频生成工具在面对“超自然”特效(如魔法、变形、粒子爆炸)时往往束手无策,因为它们在训练数据中极为稀缺。更糟糕的是,传统方法通常需要对每一种新特效单独训练模型(LoRA 微调),耗时耗力,严重限制了创造力。
2. ✅ EffectMaker 方案:参考即指令
EffectMaker 提出了全新的“参考视频驱动”范式:
- 输入:一段包含 desired 特效的参考视频 + 一张目标人物/场景图片。
- 输出:一段目标人物完美演绎该特效的新视频。
- 优势:零样本 (Zero-Shot) 能力。无需任何额外训练,见所未见的特效也能瞬间迁移。
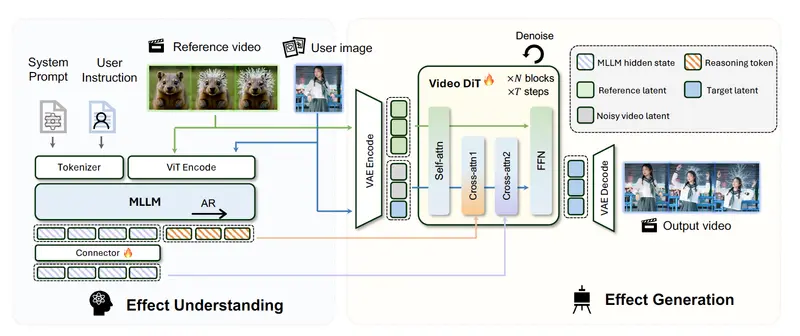
工作原理:会“思考”的特效导演 + 手艺精湛的特效师
EffectMaker 的创新在于其语义 - 视觉双路径引导机制,模拟了人类特效制作的专业流程:
第一步:语义推理(导演的智慧)
- 组件:多模态大语言模型 (Qwen3-VL)。
- 任务:
- 理解参考:分析参考视频,提取高级语义(“这是附着在手掌的蓝色闪电,带有强烈的脉冲感”)。
- 分析目标:观察目标图片的姿态、服装、场景。
- 逻辑推理:推导适配方案(“参考是长发女性,目标是短发男性,闪电应从掌心发出并沿手臂蔓延,而非头发”)。
- 产出:抽象的语义引导描述,确保特效的“神韵”正确。
第二步:视觉生成(特效师的双手)
- 组件:视频扩散变换器 (Wan2.2)。
- 任务:
- 细节捕获:利用上下文学习 (In-Context Learning),从参考视频中提取细粒度的视觉线索(火焰的纹理、粒子的运动轨迹)。
- 双流注意力:同时处理语义指导和视觉参考,通过解耦交叉注意力机制,避免两者干扰。
- 精准合成:生成既符合物理规律,又完美适配目标主体的新视频。
- 产出:高保真、动态一致的最终视频。
EffectData:迄今最大的特效数据集
为了训练如此强大的模型,团队构建了 EffectData —— 一个里程碑式的数据集:
- 规模:13 万段 高质量视频。
- 覆盖:3000+ 种多样化特效类别(氛围、变换、风格化、运动效应等)。
- 对比:类别数量是现有公开数据集的 10 倍 以上。
- 构建流程:采用自动化流水线,利用 LLM 生成指令 -> 图像编辑模型生成中间帧 -> 视频生成模型合成动态视频,确保了数据的多样性与标注的准确性。
性能实测:全面超越 SOTA
在多项基准测试中,EffectMaker 展现了统治级的表现:
| 指标 | EffectMaker | 最佳竞品 (VFX-Creator/Omni-Effect) | 提升幅度 |
|---|---|---|---|
| 视觉质量 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | +34% |
| 运动流畅度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | +25% |
| 特效匹配度 | 4.63 / 5.0 | ~3.8 | 显著领先 |
| 人类首选率 | 40-43% | <30% | 压倒性优势 |
典型案例:
- 爆炸特效:竞品常出现位置偏移或颜色失真,EffectMaker 完美复现爆炸形态与光影。
- 身体变形:在“充气膨胀”测试中,EffectMaker 实现了自然的体积变化,而竞品往往导致结构崩坏。
- 开放域泛化:面对训练未见过的“传送门”、“石膏化”特效,EffectMaker 依然能生成合理结果,证明了其强大的泛化能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











