
多人对话视频的自动生成,长期以来受限于两个关键难题:一是高质量多人视频数据极难获取,二是多个角色之间的互动行为难以建模。为解决这些问题,来自香港科技大学、Video Rebirth、浙江大学和北京交通大学的研究团队提出了 AnyTalker —— 一个支持任意身份数量扩展、仅需单人数据训练、并能生成自然互动的音频驱动多人视频生成框架。
- 项目主页:https://hkust-c4g.github.io/AnyTalker-homepage
- GitHub:https://github.com/HKUST-C4G/AnyTalker
- 模型:https://huggingface.co/zzz66/AnyTalker-1.3B
- Demo:https://huggingface.co/spaces/C4G-HKUST/AnyTalker
核心目标
AnyTalker 的设计初衷非常明确:
- 降低数据成本:不依赖大规模真实多人视频数据集;
- 提升互动真实性:让多个角色在对话中表现出眼神交流、头部微动等自然反应;
- 实现身份可扩展:支持两人、四人甚至更多角色的对话视频生成,无需重新训练模型。
关键技术
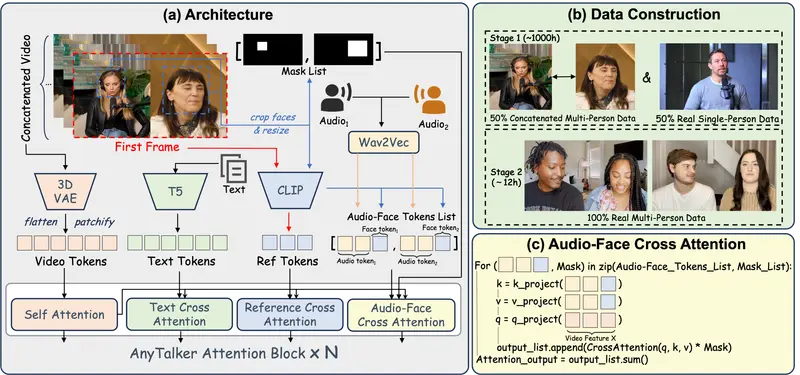
1. 身份感知注意力机制(Audio-Face Cross Attention, AFCA)
AnyTalker 在 Diffusion Transformer 的基础上,引入了一种音频-人脸交叉注意力机制(AFCA)。该机制能够迭代式地处理身份-音频对,将每个角色的人脸图像与其对应的语音信号动态对齐。
这一设计使得模型在推理时可接收任意数量的身份-音频输入组合,真正实现了“可扩展”的多人生成能力。
2. 两阶段训练策略
为绕过多人数据稀缺的瓶颈,AnyTalker 采用了一种高效的两阶段训练流程:
- 第一阶段(预训练):仅使用单人视频数据(如 HDTF、VFHQ),通过水平拼接多个单人视频的方式,模拟多人对话场景,学习基础的唇音同步与表情生成能力。
- 第二阶段(微调):引入少量真实多人视频片段(例如团队自建的 InteractiveEyes 数据集),专门优化角色间的互动行为建模,如倾听时的眼神偏移、点头等。
这种策略大幅降低了对标注数据的依赖,同时保留了高质量的生成效果。
3. 互动性量化评估
为了客观衡量生成视频的“自然互动”程度,团队还提出了新的评估方法:
- 通过眼睛关键点的运动幅度,量化角色在非说话状态(即“倾听”)下的反应强度;
- 发布了 InteractiveEyes 数据集,包含多视角、高帧率的真实多人对话视频,专用于评估互动性。
实验结果
- 单人任务表现:在 HDTF 和 VFHQ 等标准单人基准上,AnyTalker 在唇音同步准确率、视觉质量、身份保真度等指标上达到 SOTA 或接近 SOTA 水平。
- 多人任务优势:在 InteractiveEyes 数据集上,AnyTalker 在互动性指标上显著优于现有方法(如 Bind-Your-Avatar、MultiTalk)。
- 扩展性验证:成功生成四人对话视频,各角色口型、表情、互动行为协调一致,未出现身份混淆或动作僵硬问题。
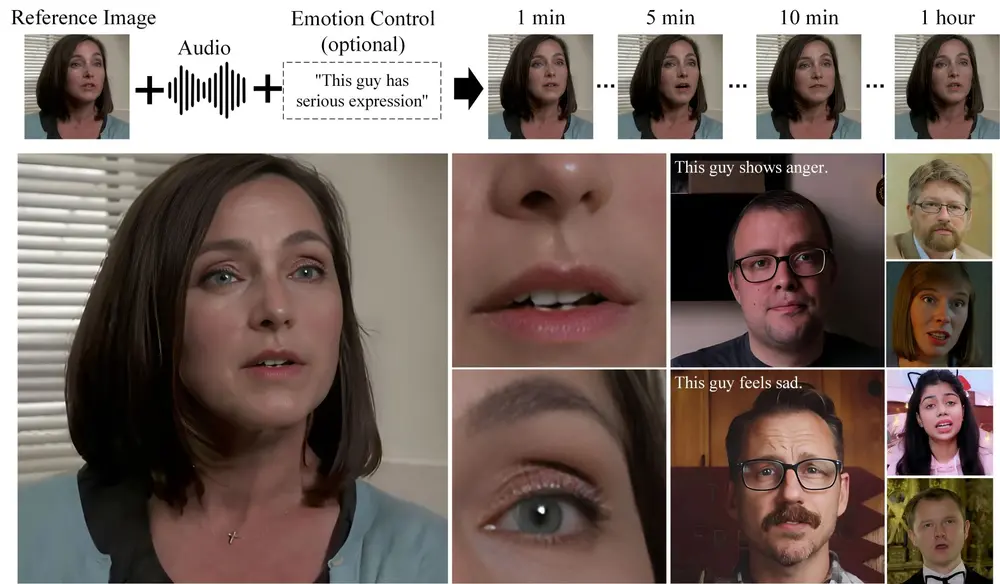
输入灵活性与角色泛化
AnyTalker 不仅支持真实人脸图像作为输入,还能处理:
- AI 生成的人脸(如 Stable Diffusion 生成的角色);
- 卡通或非人类角色(需提供对应面部结构);
这为虚拟偶像、游戏角色、教育动画等场景提供了广泛适用性。
应用场景
AnyTalker 的技术特性使其在多个领域具有实用价值:
- 虚拟会议:自动生成多人发言视频,提升远程协作的临场感;
- 内容创作:快速制作访谈、对谈类短视频,无需真人出镜或复杂动捕;
- 教育视频:通过多个虚拟教师/学生互动讲解知识,增强学习沉浸感;
- VR/AR 与游戏:为虚拟场景注入自然的多人对话行为,提升交互真实度;
- 无障碍辅助:为听障用户提供带精准口型和互动表情的多人语音可视化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











