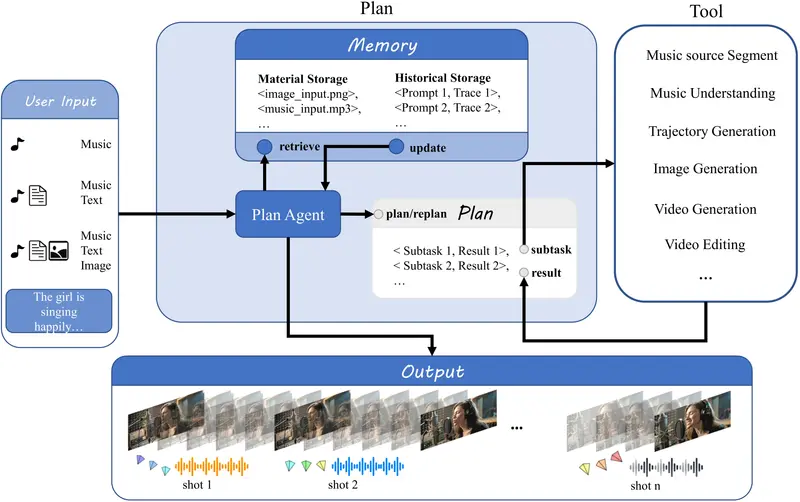
巨人网络AI实验室推出 YingVideo-MV,这是一个用于音乐驱动的多阶段视频生成框架,能够从音频信号中自动生成高质量的音乐表演视频。YingVideo-MV 集成了音频语义分析、可解释的镜头规划模块(MV-Director)、时间感知的扩散 Transformer 架构,以及长序列一致性建模,实现了从音频信号到高质量音乐表演视频的自动合成。
例如,给定一段音乐、文本描述和人物肖像,YingVideo-MV 可以生成具有高身份一致性和丰富情感表达的音乐表演视频。

主要功能
- 音乐驱动的视频生成:从音乐信号中生成高质量的音乐表演视频,支持精确的音乐节拍和情感同步。
- 镜头规划与相机控制:通过 MV-Director 模块,实现镜头规划和相机运动的精确控制,生成具有丰富镜头语言的视频。
- 长序列一致性建模:通过时间感知的动态窗口范围策略,解决长视频生成中的时间一致性问题,确保视频的连贯性。
- 多模态输入支持:支持多种输入模态,包括音频、文本、图像和参考视频,生成与输入语义一致的视频内容。
主要特点
- MV-Director 模块:通过整合多模态输入(文本提示、相机轨迹、初始帧和音乐片段)生成统一的语义指令,实现从低级线索跟踪到深度理解音乐电影语言的转变。
- 两阶段生成框架:第一阶段通过 MV-Director 进行全局语义和镜头规划,第二阶段通过时间感知的扩散 Transformer 实现每个镜头内的动画效果,平衡全局一致性与局部表现力。
- 时间感知动态窗口范围策略:通过动态调整去噪范围,解决长序列生成中的时间一致性问题,确保视频的连贯性和自然过渡。
- 高保真生成:在多种场景下生成高保真、时间连贯的肖像视频,实现精确的唇部同步、丰富的面部表情变化和与音乐节拍同步的相机运动。
工作原理
- 音频语义分析:使用 Wav2Vec 提取音频嵌入,并通过音频适配器进行细化,以减少分布不匹配。
- 镜头规划模块(MV-Director):通过分析音乐片段的情感属性和文本提示,生成镜头列表,包括初始帧构图、节拍提示和角色运动模式。
- 时间感知扩散 Transformer:将音频嵌入和相机轨迹嵌入注入扩散 Transformer,同时处理唇部同步、面部表情生成和相机运动合成,实现表演动作、音乐节拍和相机动态的自然协调。
- 动态窗口范围策略:通过动态调整去噪范围,确保长视频生成中的时间连贯性和视觉一致性,通过平滑传播视觉状态来实现相邻片段之间的无缝过渡。
测试结果
- 定量评估:
- FID(Frechet Inception Distance):30.36,衡量单帧视觉质量。
- FVD(Frechet Video Distance):193.68,评估时间一致性。
- CSIM(Cosine Similarity):0.753,衡量身份一致性。
- Sync-C 和 Sync-D:分别达到 6.07 和 8.67,评估唇部同步精度。
- RotErr 和 TransErr:分别达到 1.22 和 4.85,评估相机运动精度。
- 用户研究:
- 相机运动的平滑性和连贯性:平均评分 4.3±0.6。
- 唇部同步精度:平均评分 4.5±0.5。
- 角色运动的自然性:平均评分 4.2±0.5。
- 整体视频质量:平均评分 4.4±0.6。
应用场景
- 音乐视频生成:自动生成高质量的音乐表演视频,支持多种相机运动和情感表达。
- 虚拟角色动画:为虚拟角色生成逼真的音乐表演动画,支持实时互动和多模态输入。
- 广告和宣传视频:生成具有丰富视觉效果和情感表达的广告视频,支持多种创意需求。
- 电影和视频制作:辅助电影和视频制作,提供高效的镜头规划和动画生成工具,减少后期制作成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











