
苹果最新发布的 STARFlow-V 为视频生成领域带来了全新技术路径——作为一款基于标准化流(Normalizing Flows)的端到端模型,它打破了当前扩散模型主导的格局,凭借全局-局部架构、因果生成能力和高效采样特性,在视觉保真度、时间一致性与实时性之间实现了平衡,原生支持文本到视频(T2V)、图像到视频(I2V)、视频到视频(V2V)三大核心任务。
- 项目主页:https://starflow-v.github.io
- GitHub:https://github.com/apple/ml-starflow
- 模型:https://huggingface.co/apple/starflow
核心突破:标准化流重构视频生成逻辑
传统视频生成多依赖扩散模型,但这类模型存在训练与测试非端到端、长序列生成易出现误差累积等问题。STARFlow-V 基于标准化流的可逆特性,重新定义了视频生成的技术框架,核心优势集中在三点:
- 端到端似然学习:通过最大似然估计实现端到端训练,避免扩散模型中“去噪迭代”与“生成推理”的流程割裂,原生支持似然估计,模型稳定性更强;
- 因果生成无回溯:后续帧生成不依赖或影响先前帧,完全符合实时流媒体、交互式应用的场景需求,解决了自回归模型“后帧修正前帧”的逻辑矛盾;
- 多任务原生适配:借助标准化流的可逆结构,无需修改架构或重新训练,即可无缝切换 T2V、I2V、V2V 任务,适配更多应用场景。
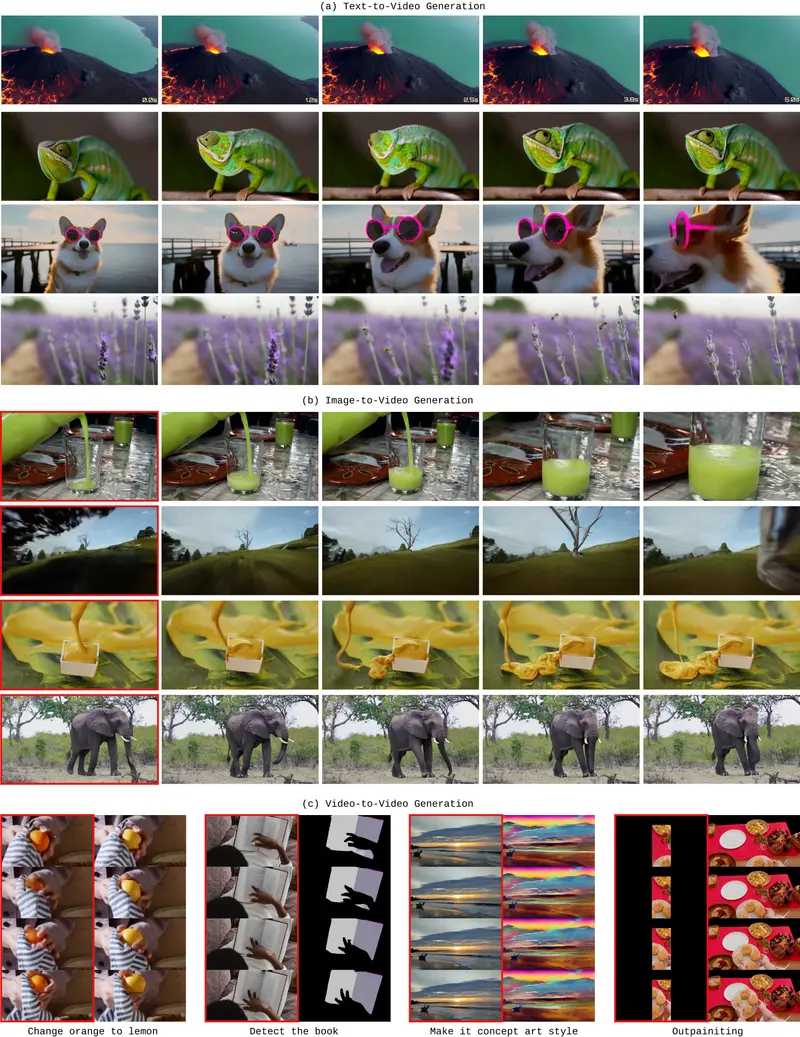
三大核心创新:破解视频生成关键痛点
1. 全局-局部架构:解决时间维度误差累积
STARFlow-V 采用两级分离设计,兼顾长程时空依赖与局部细节表达:
- 全局模块:由深度因果 Transformer 构成,在压缩后的潜在空间中以自回归方式处理时间序列,精准捕获帧间逻辑关联(如动作连续性、场景转换);
- 局部模块:由浅层流块组成,独立处理单帧内部的细节生成(如纹理、色彩、局部结构),避免单帧误差在长序列中放大;
- 核心价值:打破了“全局依赖导致误差累积、局部独立导致帧间割裂”的两难,使 30 秒长视频生成仍能保持结构连贯,无模糊、颜色漂移问题。
2. 流-得分匹配:轻量去噪提升一致性
针对标准化流生成质量易受噪声影响的问题,STARFlow-V 提出专属去噪方案:
- 训练轻量级因果神经去噪器,与主流模型协同工作,而非依赖非因果或性能有限的通用去噪器;
- 去噪器通过学习模型自身分布的对数概率梯度(得分),在保持因果性的前提下实现单步细化,大幅提升视频帧间一致性;
- 训练过程中通过“噪声注入-去噪优化”的闭环,增强模型对复杂场景的鲁棒性。
3. 视频感知雅可比迭代:采样效率提升15倍
为解决标准化流采样速度慢的传统短板,STARFlow-V 优化了生成流程:
- 将流反演(生成过程)重构为非线性系统求解,支持块级并行更新多个潜在变量,替代逐帧串行生成;
- 引入“视频感知初始化”,利用相邻帧的时间关联性优化初始值,减少迭代次数;
- 实现深浅模块流水线执行,在不损失质量的前提下,采样速度较标准自回归解码提升 15 倍,满足实用场景需求。

模型关键信息
- 参数规模:70 亿参数,基于 7000 万文本-视频对 + 4 亿文本-图像对联合训练;
- 生成规格:支持 480p 分辨率、16fps 帧率的视频生成,最长可生成 30 秒连贯内容;
- 技术特性:端到端训练、因果生成、可逆结构、原生似然估计;
- 核心优势:长序列一致性强、采样效率高、多任务无缝切换、因果推理适配实时场景。
测试表现:比肩扩散模型,长序列生成更优
在 VBench 等主流视频生成基准测试中,STARFlow-V 展现出差异化优势:
- 综合质量:总质量、语义一致性、审美质量等核心维度与顶尖扩散模型持平;
- 长序列表现:生成 30 秒视频时,无扩散模型常见的结构变形、细节丢失问题,时间一致性显著更优;
- 实时性:因果生成特性 + 高效采样方案,使其能适配低延迟场景,远超扩散模型的实时响应能力。
应用场景:覆盖实时交互与创意生成
STARFlow-V 的技术特性使其在多个场景中具备不可替代性:
- 实时交互场景:视频游戏实时渲染、虚拟人直播、机器人视觉模拟等,依赖因果生成能力实现无回溯实时输出;
- 创意内容生产:广告片、短视频、动画片段生成,支持文本/图像触发,或基于原始视频进行风格转换、对象编辑(V2V 任务);
- 视频编辑工具:快速实现“图像动起来”“文本转短片”“视频风格迁移”等功能,降低创意制作门槛;
- 世界模型构建:凭借似然估计与可逆特性,可用于物理场景模拟、环境预测等科研与工业场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











