随着多模态生成技术的发展,用户对虚拟角色的期待已从“能说话”升级为“能自然表达、实时互动、持续存在”。为此,智谱AI推出了 RealVideo —— 一个端到端实时流式视频对话系统,能够将文本对话实时转化为连续、高保真、身份一致的视频回应。
- 项目主页:https://z.ai/blog/realvideo
- GitHub:https://github.com/zai-org/RealVideo
- 模型:https://huggingface.co/zai-org/RealVideo
与传统“先生成整段视频再播放”的方案不同,RealVideo 采用流式自回归生成架构,以约 0.5 秒为单位逐步输出视频块,实现接近人与人对话的响应节奏,端到端延迟控制在 约 2 秒。
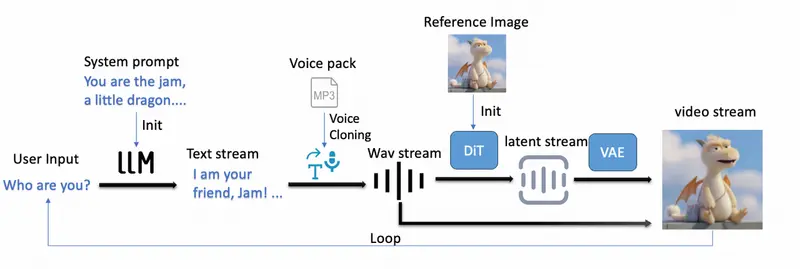
系统工作流程
RealVideo 的交互流程如下:
- 角色初始化:用户提供一张参考图像 + 一段参考语音,系统据此克隆角色外观与声音;
- 对话启动:用户输入文本(未来可扩展为语音),由大语言模型(LLM)生成回应;
- 语音合成:LLM 输出的文本经 TTS 转为音频;
- 视频生成:音频驱动自回归扩散模型,以 0.5 秒视频块为单位生成隐状态;
- 流式解码与播放:VAE 服务将隐状态实时解码为像素帧,并与音频同步推送到前端。
系统默认使用文本输入以保持模块化,但架构支持通过 ASR/VAD 扩展为语音输入,或通过流式 VLM 支持视频+语音多模态输入。
核心模型设计
1. 基座模型:WanS2V
团队基于开源音频驱动视频模型 WanS2V 构建 RealVideo,因其在 5 秒语音视频生成任务中表现优异。选择其非延续模式作为训练起点,便于自回归扩展。
2. 两阶段训练流程
- 阶段 1:ODE 蒸馏
从双向教师模型采样 ODE 轨迹,训练单向模型在 仅 2–4 步内拟合高质量生成,显著加速推理。 - 阶段 2:Self-Forcing + 对抗训练
引入 虚假分数模型作为判别器,在噪声隐状态上进行对抗训练。判别器特征来自模型深层(如第 14、22、30 层),通过交叉注意力分类头输出判别信号。
为避免干扰主损失,切断梯度回传至虚假模型,并动态控制判别器更新频率。该策略显著提升感知质量并减少色彩漂移。
3. 滑动窗口注意力(用于实时推理)
为控制每帧推理延迟,系统采用滑动窗口注意力,固定 KV 缓存长度。虽然该方法存在 长期记忆丢失 和 动作重复 风险,但在音频驱动场景下影响有限:
- 音频本身对每帧内容有强约束;
- 日常对话动作通常短时、简单(如点头、眨眼),无需长程记忆。
因此,滑动窗口成为当前版本的合理折中。
4. 动态 Sink RoPE —— 解决身份漂移
参考图像作为 Sink Tokens 被保留在 KV 缓存中,但其与当前帧的相对位置随生成延长而增大,超出训练时 RoPE 范围,导致角色逐渐失真(身份漂移)。
解决方案:动态调整参考图像的 RoPE 索引,始终满足:
RoPE(参考图像) = RoPE(当前帧) + 10
此策略确保位置关系始终落在训练分布区间 [10, 30] 内,有效维持长时间生成的身份一致性。

系统架构与优化
RealVideo 采用 双服务架构:
- VAE 服务:协调 LLM-TTS 流程、编码条件、解码视频帧、推流至前端;
- DiT 服务:运行流式扩散 Transformer,接收音频嵌入,自回归生成隐状态块。
实时性能优化
- 多 GPU 序列并行(Ulysses):2×H100 将单块推理从 943ms 降至 655ms;
- PyTorch 编译:通过
torch.compile优化关键模块,推理速度提升约 6%; - KV 缓存内存预分配:利用滑动窗口大小固定特性,预分配内存块,减少动态分配开销。
响应延迟控制
- 视频块大小 = 2 帧(0.5 秒):在计算效率与首帧延迟间取得平衡;
- 流水线缓冲 = 2–3 块:系统启动后预生成少量视频块,确保播放流畅;
- 端到端延迟 ≈ 2 秒:包含 LLM、TTS 与视频生成全链路。
曾实验“TTS 草稿并行”策略(低质音频先用于视频生成),但收益仅几十毫秒,且增加 API 负载,最终未采用。
静音处理
当用户无输入时,音频为零,模型易生成冻结画面。解决方法:在静音帧中注入与训练数据背景噪声方差匹配的随机噪声,维持角色微表情与临场感。
总结
RealVideo 并非追求“最长视频”或“最高分辨率”,而是聚焦于实时性、身份一致性与工程可用性。通过:
- 自回归扩散架构
- 动态 Sink RoPE 位置对齐
- 流式双服务部署
- 多级系统优化
它成为首批能持续、稳定、低延迟生成对话视频的开源系统之一,为虚拟主播、数字人客服、教育助手等场景提供了可落地的技术基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











