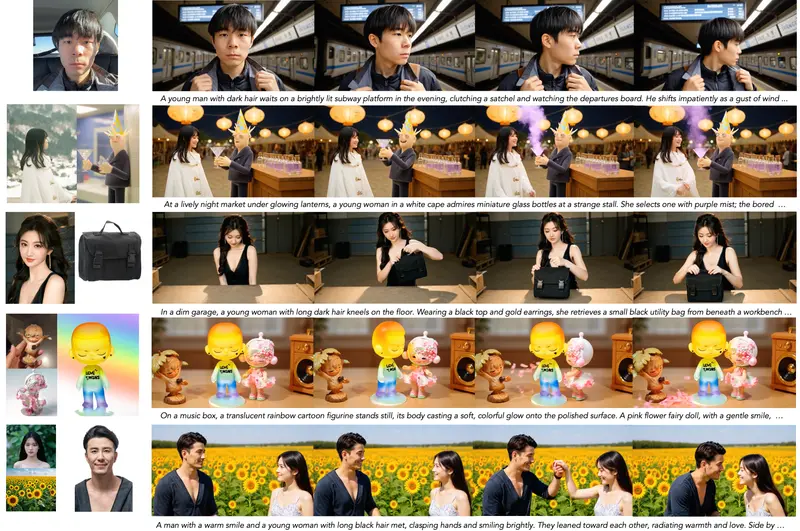
你是否曾想过,仅凭一张静态照片和一段语音,就能让照片中的人物“开口说话”,并持续数分钟自然表达?这正是音频驱动虚拟人视频生成(Audio-Driven Talking Head Generation)的核心目标。
然而,当前主流方法在生成长视频时普遍面临两大难题:
一是身份漂移——随着视频延长,人物面容逐渐失真或“变脸”;
二是音画不同步——口型与语音错位,动作僵硬,破坏沉浸感。
为突破这一瓶颈,复旦大学、微软亚洲研究院、西安交通大学与腾讯混元项目组联合提出 StableAvatar ——这是首个无需后处理、可端到端生成无限长度高质量虚拟人视频的扩散模型。
- 项目主页:https://francis-rings.github.io/StableAvatar
- GitHub:https://github.com/Francis-Rings/StableAvatar
- 模型:https://huggingface.co/FrancisRing/StableAvatar
该方法不仅实现了长时间生成下的身份一致性与音频同步,还在视频流畅性与视觉质量方面达到新高度,为虚拟人、数字助理、影视制作等应用提供了更具实用性的技术路径。
为什么长视频生成如此困难?
尽管已有不少基于生成对抗网络(GAN)或扩散模型的方法能够生成几秒内的 talking head 视频,但一旦扩展到数十秒甚至数分钟,性能便急剧下降。
根本原因在于:现有模型在音频建模方式上存在结构性缺陷。
大多数方法依赖第三方工具(如 Wav2Vec)提取音频嵌入,并通过交叉注意力机制直接注入扩散模型。但由于扩散骨干网络本身缺乏音频先验知识,这种“外挂式”注入会导致:
- 每个时间片段的潜在表示出现微小偏差;
- 随着视频延长,这些偏差不断累积,最终导致潜在分布偏离理想状态;
- 结果表现为:口型错乱、面部结构扭曲、身份特征丢失。
StableAvatar 的设计正是从这一核心问题出发,提出了系统性解决方案。
StableAvatar 的三大关键技术
1. 时间步感知音频适配器(Time-step-aware Audio Adapter)
传统音频注入方式是“静态”的——同一段音频嵌入被重复使用于不同去噪时间步,忽略了扩散过程中特征演化的需求。
StableAvatar 引入了 时间步感知调制机制,使音频嵌入能够根据当前去噪阶段动态调整。具体来说:
- 将扩散的时间步信息编码为条件信号;
- 调制音频嵌入的通道权重,使其更匹配当前潜在状态;
- 有效缓解了跨时间步的分布偏移问题,抑制误差累积。
这一设计使得模型在长序列生成中仍能保持稳定的音画对齐。
2. 音频原生引导机制(Audio Native Guidance)
在推理阶段,StableAvatar 提出一种新型引导策略:利用模型自身在扩散过程中生成的联合音频-潜在预测,作为动态引导信号。
与传统的固定引导不同,该机制具有“自反馈”特性:
- 模型在每一步去噪中预测音频与潜在的联合分布;
- 利用该预测结果反向增强后续生成过程;
- 实现更精细的口型控制与表情同步。
实验表明,该机制显著提升了语音与面部动作之间的时间对齐精度。
3. 动态加权滑动窗口策略(Dynamic Weighted Sliding Window)
为了保证长视频的帧间平滑性,避免片段拼接带来的跳跃或闪烁,StableAvatar 设计了一种时间维度上的潜在融合策略:
- 将视频划分为重叠的时间窗口;
- 对每个窗口的潜在表示进行加权融合,权重由内容相似性动态决定;
- 在推理时实现无缝衔接,提升整体连贯性。
该策略无需额外训练,可在推理阶段灵活应用,显著改善长视频的视觉流畅度。
工作流程简述
- 输入准备:
- 参考图像:提供身份先验;
- 音频信号:作为动作驱动源;
- 音频编码:
- 使用 Wav2Vec 提取音频特征;
- 经时间步感知音频适配器优化,生成时变嵌入;
- 扩散生成:
- 在潜在空间中,结合参考图像嵌入与优化后的音频嵌入;
- 通过交叉注意力进行联合建模;
- 推理增强:
- 启用音频原生引导机制,提升同步性;
- 应用动态滑动窗口融合,确保时间一致性;
- 解码输出:
- 由 VAE 解码器生成高分辨率视频帧,支持无限长度输出。
整个流程完全端到端,无需后处理或帧拼接。
实验表现:全面领先
研究团队在多个标准数据集上进行了评估,包括:
- HDTF(高清真实对话视频)
- AVSpeech(大规模语音-视频对)
- Long100(专为长视频生成设计的测试集)
评估指标涵盖:
| 指标 | 含义 |
|---|---|
| FID / FVD | 视频质量与真实性 |
| CSIM | 身份一致性(Clip Similarity) |
| Sync-C / Sync-D | 音频-口型同步精度(Content & Dynamics) |
| IQA / ASE | 主观画质与美学评分 |
关键结果:
- FID 与 FVD:在所有数据集上均优于现有方法,表明生成视频更接近真实分布;
- CSIM(身份一致性):在 Long100 上达到 0.849,显著高于次优方法,说明身份长期稳定;
- Sync-C 与 Sync-D:分别达到 8.24 和 6.79,音频同步性能领先;
- IQA 与 ASE:主观质量得分分别为 3.84 和 2.39,接近真实视频水平。
定性对比也显示,StableAvatar 在大表情变化、快速语速和复杂光照条件下仍能保持自然表现。
实用性与部署支持
StableAvatar 基于 Wan2.1-1.3B 扩散模型构建,在保证高质量的同时优化了资源消耗:
- 支持多种分辨率输出:480×832、832×480、512×512;
- 可生成超过 3 分钟的连续视频,且无明显质量衰减;
- 若遇显存不足,可通过减少帧数或降低分辨率灵活调整;
- 推理效率优于同类扩散模型,具备实际部署潜力。
未来可广泛应用于:
- 虚拟主播与数字人直播;
- 教育/客服场景中的个性化助手;
- 影视后期配音重制;
- 社交平台的趣味互动内容生成。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...