扩散模型在图像和视频合成任务中展现出卓越性能,但其依赖多步迭代去噪的过程,导致计算成本高昂。为解决这一问题,一致性模型(Consistency Models) 在加速扩散模型方面取得了重要进展。
然而,直接将一致性方法应用于视频扩散模型时,往往会导致时间不一致和细节模糊等问题。近期,来自南京大学、香港大学、上海人工智能实验室、中国科学院大学和南洋理工大学的研究团队提出了一种参数高效的解决方案 —— DCM(Dual Expert Consistency Model),通过“语义 + 细节”双专家架构,在保证视觉质量的同时显著提升推理效率。
- 项目主页:https://vchitect.github.io/DCM
- GitHub:https://github.com/Vchitect/DCM
- 模型:https://huggingface.co/cszy98/DCM
问题背景:蒸馏过程中的学习动态冲突
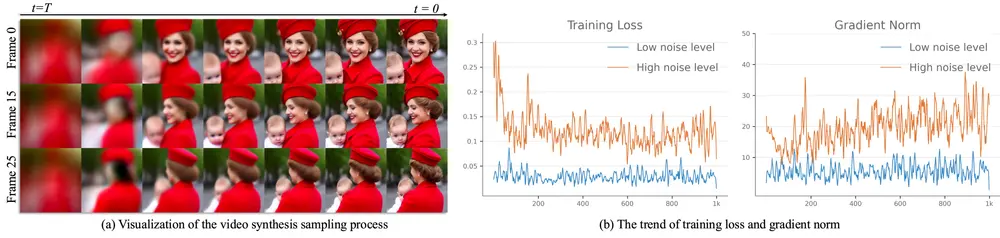
一致性模型通常通过对预训练扩散模型进行知识蒸馏来构建,从而实现单步采样。但在视频生成场景中,研究人员发现:
- 不同噪声阶段的学习目标存在差异:
- 早期高噪声阶段主要关注语义布局与运动建模;
- 后期低噪声阶段则聚焦于细节修复与纹理增强。
- 这种梯度方向与损失贡献上的差异,使得单一学生模型难以同时兼顾两种任务,最终导致:
- 视频帧之间出现运动不连贯
- 画面细节出现模糊或失真
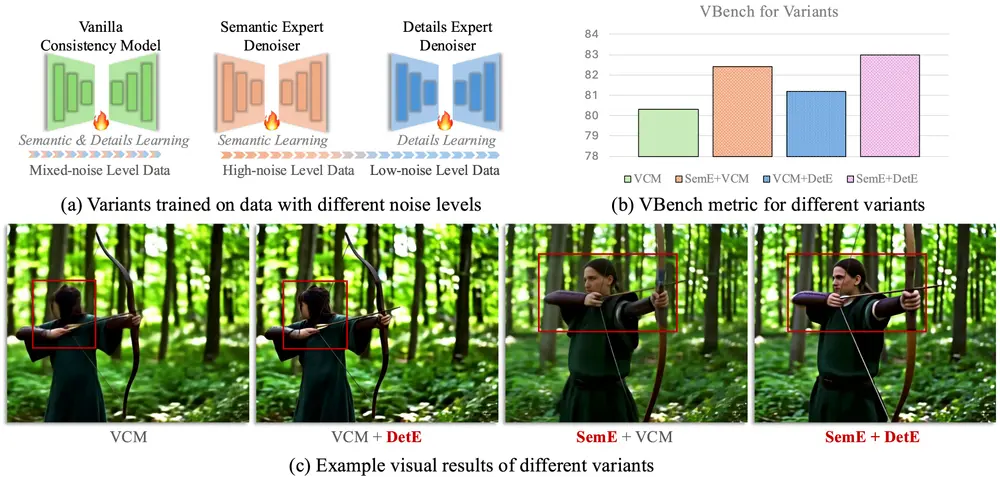
解决方案:双专家架构 + 参数高效设计
为应对上述挑战,研究团队提出了 DCM 模型,其核心思想是:
将视频生成任务拆解为两个子任务,并由两个独立专家分别负责。
✅ 双专家架构设计
| 专家类型 | 负责任务 | 损失函数 |
|---|---|---|
| 语义专家 | 学习语义布局与运动模式 | 引入时间一致性损失,强化帧间运动平滑性 |
| 细节专家 | 优化画面细节与纹理表现 | 使用 GAN 损失 + 特征匹配损失,提升画质质量 |
参数高效策略
研究发现,语义专家与细节专家之间的参数差异主要集中在注意力模块的时间步嵌入层和线性变换部分。因此,DCM 提出了一个轻量级的架构改进方式:
- 首先训练并冻结语义专家;
- 然后仅对注意力层添加 LoRA 微调模块,用于适配细节优化任务;
- 推理时根据当前噪声水平自动选择对应专家,完成分阶段预测。
该方法以极小的额外参数量,实现了接近双独立专家模型的性能,显著提升了训练效率和部署灵活性。
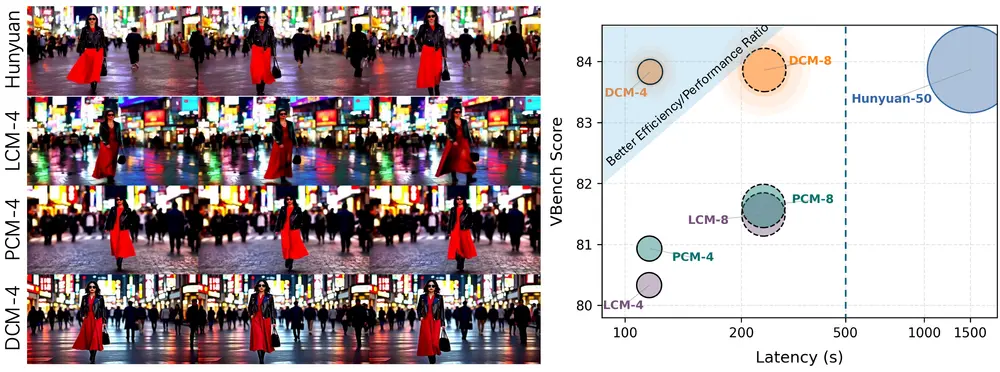
实验验证:高效采样下的视觉质量领先
在多个视频生成基准测试中,DCM 表现出色:
- 支持单步或少量采样步骤即可生成高质量视频;
- 在视觉质量和时间一致性指标上达到SOTA(最先进)水平;
- 显著优于传统一致性模型及蒸馏扩散模型。
此外,该方法已被成功应用于两个主流视频生成框架的蒸馏任务中:
| 模型 | 数据集 | 备注 |
|---|---|---|
| HunyuanVideo | HD-Mixkit-Finetune-Hunyuan | 已提供预处理脚本与模型初始化说明 |
| WAN2.1 | 自建在线数据集 | 可自定义数据集类,支持灵活扩展 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...