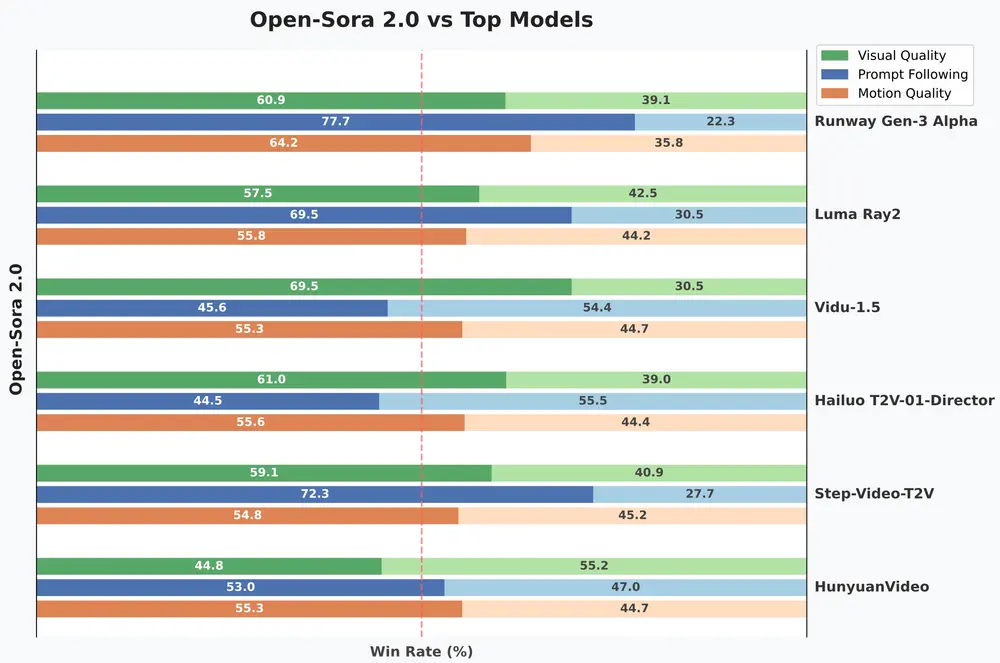
潞晨科技宣布推出开源视频生成模型 Open-Sora 2.0,并全面开源模型权重、推理代码及分布式训练全流程。这款模型仅用 20 万美元(相当于 224 张 GPU 的计算成本)便成功训练出商业级 11B 参数的大模型,性能直追腾讯混元和 30B 参数的 Step-Video。与 OpenAISora 闭源模型相比,性能差距从 4.52% 缩减至仅 0.69%,几乎实现了全面追平。

Open-Sora 2.0 的核心优势
Open-Sora 2.0 通过优化数据处理、模型架构、训练策略和系统优化,实现了高效且低成本的视频生成能力。其主要功能和特点如下:
主要功能
- 文本到视频生成
根据文本提示生成高质量视频,满足多样化的创作需求。 - 图像到视频生成
以图像为基础生成视频,支持更精确的视觉控制,增强创作灵活性。 - 运动控制
通过运动分数(motion score)控制视频中的动态程度,满足不同场景需求。 - 高分辨率支持
支持高达 768×768 像素的视频生成,适用于高质量内容创作。 - 高效训练
通过优化的数据处理和训练策略,仅用 20 万美元完成训练,显著降低了成本。
主要特点
- 高效数据处理
- 分层数据过滤系统:通过多级过滤,从原始视频中提取高质量的训练数据。
- 数据注释:使用先进的视觉语言模型为视频生成详细的字幕,增强训练效果。
- 优化的模型架构
- Video DC-AE:一种高效的 3D 视频自编码器,显著减少了生成视频所需的计算量。
- DiT 架构:结合双流和单流处理块,有效捕捉长距离依赖关系。
- 低成本训练
- 分阶段训练:先在低分辨率数据上训练,再逐步提升分辨率,优化计算资源。
- 系统优化:通过并行化策略和激活检查点技术,最大化训练效率。
- 灵活的条件生成
- 图像引导:通过图像引导生成视频,增强视觉一致性。
- 动态运动控制:通过运动分数控制视频的动态程度,满足不同场景需求。
工作原理
- 数据处理
- 分层过滤:从原始视频中逐步筛选出高质量的训练样本。
- 注释生成:使用预训练的视觉语言模型为视频生成详细的字幕。
- 模型架构
- Video DC-AE:通过高压缩比的自编码器减少生成所需的计算量。
- DiT 架构:结合双流和单流处理块,有效捕捉长距离依赖关系。
- 训练策略
- 分阶段训练:先在低分辨率数据上训练,逐步提升分辨率,优化计算资源。
- 系统优化:通过并行化策略和激活检查点技术,最大化训练效率。
- 条件生成
- 图像引导:通过图像引导生成视频,增强视觉一致性。
- 动态运动控制:通过运动分数控制视频的动态程度,满足不同场景需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











