
字节跳动 AI 实验室发布了一项令人眼前一亮的视频生成技术 —— ATI(Any Trajectory Instruction),它让普通人也能通过“画轨迹”的方式,精准控制视频中物体的运动、镜头的移动甚至局部细节的动态变化。
官方宣布,配套模型 ATI-Wan2.1 14B 即将在不久后向公众开放,意味着开发者和创作者将能直接上手使用这一前沿技术。
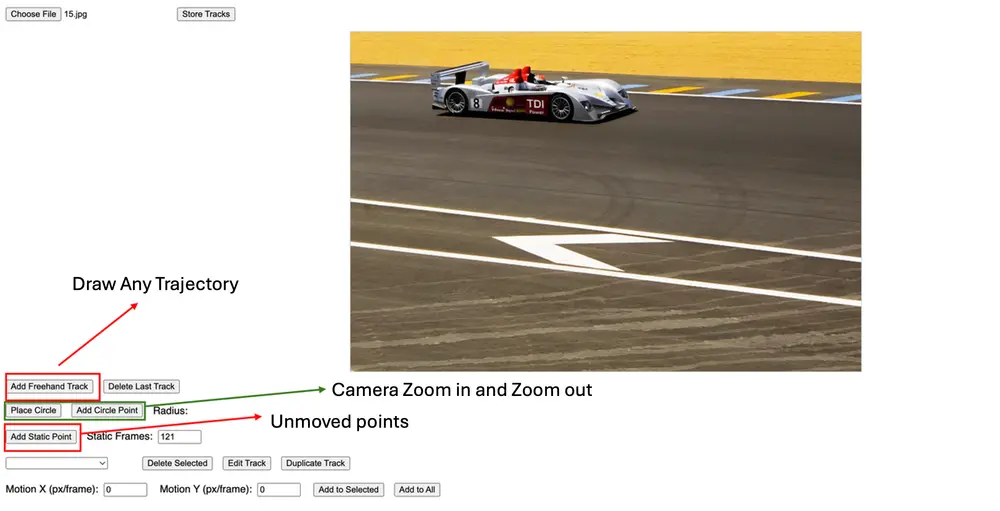
什么是 ATI?一个“画轨迹就能生成视频”的新方法
传统的视频生成工具,往往只能粗略地控制画面内容,比如“让汽车从左到右移动”,但很难做到“让车头先转、再加速、最后刹车停住”。
而 ATI 的出现,打破了这种限制。它的核心思想是:
你只需要在图像上画出你想动的点的轨迹路径,AI 就能根据这些路径生成一段符合运动逻辑的视频。
无论是:
- 对象整体移动(如人物走路)
- 局部变形(如挥手、眨眼)
- 摄像机视角变换(推拉、旋转)
ATI 都能统一处理,实现精细控制。
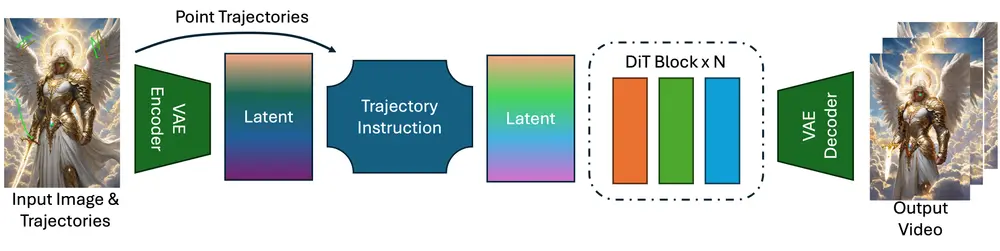
技术原理简析:如何用轨迹生成视频?
ATI 并没有从头训练一个新模型,而是基于现有的图生视频模型(Wan2.1),加入了一个轻量级的“运动注入器”模块。具体流程如下:
✅ 步骤一:用户绘制轨迹
- 用户可以在图像上指定多个关键点,并绘制它们的运动路径;
- 轨迹可以是自由手绘,也可以是系统辅助的相机运动模板。
✅ 步骤二:高斯分布编码轨迹信号
- 系统会将每个轨迹点转换为潜在空间中的特征;
- 使用高斯分布模型,对相邻像素进行权重分配,实现平滑过渡。
✅ 步骤三:注入扩散模型,生成视频
- 这些轨迹特征被注入到视频生成模型中;
- 最终输出一个时间连贯、语义一致的视频序列。
此外,为了减少轨迹中断或遮挡带来的失真,ATI 还引入了“尾部丢弃正则化”策略,让模型学会处理不完整的运动路径。
核心优势一览
| 功能 | 描述 |
|---|---|
| ✅ 统一运动控制 | 支持对象运动、局部动作、摄像机动态的一体化控制 |
| ✅ 无需重新训练 | 兼容现有主流视频生成模型,无需额外训练 |
| ✅ 高可控性 | 只需画轨迹,即可引导生成高质量动画 |
| ✅ 高质量输出 | 在风格化运动、视角切换等任务中表现优异 |
应用场景广泛,创作者友好
ATI 的最大价值在于它的操作门槛低、适用范围广。以下是一些典型应用场景:
🖌️ 动画制作
- 想让角色挥挥手?只需画出手的轨迹,AI 自动补全中间帧。
- 不再依赖复杂的骨骼绑定或逐帧绘制。
📹 视频特效
- 控制虚拟摄像机的移动轨迹,模拟电影级运镜效果;
- 快速生成特定角度的动作片段,用于后期剪辑。
🎭 游戏与虚拟角色
- 让 NPC 或虚拟主播做出精确的表情和动作;
- 降低角色动画开发成本,提升互动体验。
🎞️ 创意内容生成
- 教育、科普、短视频创作者可通过轨迹快速生成动态演示;
- 配合文生图、视频生成大模型,打造完整创作闭环。
测试结果亮眼:准确率优于现有方案
研究人员通过测试集验证了 ATI 的性能:
| 指标 | 表现 |
|---|---|
| Acc@0.01(轨迹误差小于图像对角线1%的帧比例) | 59.0% |
| Acc@0.05(轨迹误差小于图像对角线5%的帧比例) | 36.0% |
这意味着,在大多数情况下,AI 生成的视频都能较好地贴合用户定义的轨迹路径。
当然,它也有局限性,例如在极快运动或复杂解构动作中可能出现失真,但整体表现已明显优于当前主流方法。
开发者友好,兼容性强
ATI 的一大亮点就是它的高度兼容性。它不依赖于某个特定模型,而是可以轻松适配多种先进的图像到视频生成架构。
这意味着:
- 它可以无缝集成进已有视频生成平台;
- 也能作为插件或附加模块,提升现有模型的可控性;
- 更重要的是,它不会增加模型训练负担,节省大量资源。
工具已上线,即将开源
目前,研究团队已经提供了交互式编辑工具,支持:
- 手动绘制任意轨迹;
- 设置相机放大/缩小路径;
- 编辑并应用全局相机位移。
开发者和创作者可以通过这些工具,尝试构建自己的轨迹驱动视频内容。
据透露,配套的大模型 ATI-Wan2.1 14B 也将很快开源,届时所有人都可以下载使用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











