
在虚拟角色动画、VR/AR交互和智能体控制中,如何让AI根据一句自然语言(如“一个人正在跳华尔兹”)生成逼真、连贯且语义一致的人体动作,一直是核心挑战。传统方法要么动作生硬,要么与文本描述脱节,难以兼顾真实性与语义对齐。
由图宾根大学、马克斯·普朗克信息学研究所、帝国理工学院等机构联合提出的 MoLingo,通过重构潜在空间与条件注入机制,在文本到人体动作生成(Text-to-Human Motion, T2M)任务上设立了新的技术标杆。

核心问题:为什么现有扩散模型在动作生成上“失语”?
当前主流T2M模型多采用两种策略:
- 全序列一次性扩散:在完整潜在空间上直接去噪,难以捕捉长时间动作的结构一致性;
- 自回归离散扩散:将动作拆分为离散符号序列逐帧生成,损失运动连续性。
两者共同的瓶颈在于:潜在空间缺乏语义结构,导致文本条件难以有效引导生成过程——即使输入“芭蕾舞旋转”,模型也可能输出一段模糊的原地踏步。
MoLingo 的突破,正是从潜在空间语义化与文本条件精细化两个维度入手。
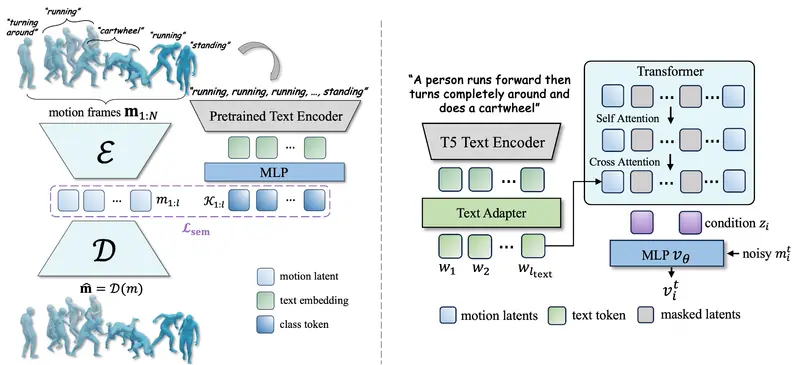
三大技术创新
1. 语义对齐的运动编码器(Semantic-Aligned Motion Encoder)
MoLingo 在训练运动编码器时,引入帧级文本标签(如“抬腿”“转身”“挥手”)作为监督信号。
→ 结果:在潜在空间中,语义相近的动作(如“慢跑”与“快走”)彼此靠近,而无关动作(如“打字”与“跳跃”)相距较远。
→ 优势:扩散过程在更“语义平滑”的空间中进行,显著提升生成动作的连贯性与语义匹配度。
2. 多标记交叉注意力(Multi-Token Cross-Attention)
传统方法通常将整段文本压缩为单个向量作为条件,信息严重损失。
MoLingo 则保留文本的完整词元序列(如“a person is performing a graceful ballet spin”中的每个词),并通过交叉注意力机制,让每个动作潜在变量动态关注相关文本词元。
→ 效果:模型能精准响应动作细节——“graceful”影响姿态流畅度,“ballet spin”触发特定旋转模式。
3. 掩码自回归扩散(Masked Auto-regressive Rectified Flow)
MoLingo 采用连续潜在空间 + 自回归掩码扩散的混合架构:
- 训练时:随机掩码部分时间步的潜在表示,用可学习的[MASK]标记替代;
- 推理时:从全掩码序列开始,逐步去噪,每次生成一小段动作并作为下一阶段的上下文。
→ 优势:兼顾长时结构(通过上下文传递)与局部细节(通过去噪优化),避免传统自回归模型的误差累积。
性能:新SOTA,用户也认可
✅ 定量评估(MARDM-67 基准)
| 指标 | MoLingo | 之前最佳 |
|---|---|---|
| FID(越低越好) | 0.049 | 0.067 |
| R-Precision@1 | 0.542 | 0.489 |
| CLIP-Score | 0.832 | 0.791 |
✅ 用户研究
在动作真实感与文本一致性两项主观评价中,84.7% 的用户认为 MoLingo 优于对比模型。
✅ 物理仿真验证
将生成动作驱动到物理引擎中的仿人机器人,MoLingo 的输出表现出更高的动力学稳定性,例如在“跳跃后落地”动作中,重心控制更自然,无明显失衡。
支持哪些动作?从日常到专业
MoLingo 能处理广泛的动作类型:
- 日常行为:扫地、倒水、开门、挥手;
- 体育运动:跳绳、瑜伽、拳击;
- 舞蹈与表演:华尔兹、芭蕾旋转、街舞动作;
- 复合指令:“先蹲下,然后缓慢站起并举手”。
得益于语义对齐潜在空间,模型对动作时序与组合逻辑的理解显著优于前代方法。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











